作者:妩媚天天想我 | 来源:互联网 | 2023-08-15 23:06
本文由编程笔记#小编为大家整理,主要介绍了深度学习框架多样化与Deep Learning的IR“之争”相关的知识,希望对你有一定的参考价值。
# 深度学习框架多样化为AI开发带来的三个挑战:
对于算法的开发者来说,由于各AI框架的前端交互和后端实现之间都存在很多区别,换框架很麻烦,而开发和交付过程中可能会用到的框架不止一个。
为了应对这个问题,之前Facebook和微软也联合发布了模型间转换工具ONNX。
深度学习框架的开发者需要维护多个后端,来保证自己的框架能适用于从手机芯片到数据中心GPU的各种硬件。
从芯片供应商的角度来看,他们每新开发一款芯片都需要支持多个AI框架,每个框架表示和执行工作负载的方式都不一样,所以,就连卷积这样一个运算,都需要用不同的方式来定义。支持多个框架,就代表要完成巨大的工作量。
# 那么,什么是IR呢?
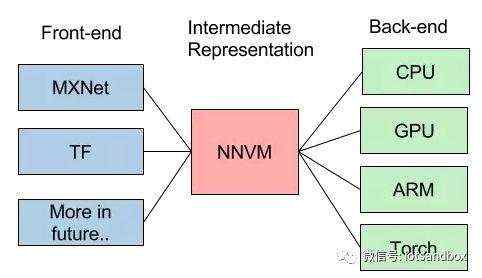
简单来说,现在Deep Learning有这么多不同前端(开发框架),有这么多不同的后端(硬件架构),是否能找到一个桥梁更有效实现他们之间的优化和影射呢?IR(Intermediate representation,中间表示层)就是这样一座桥梁。
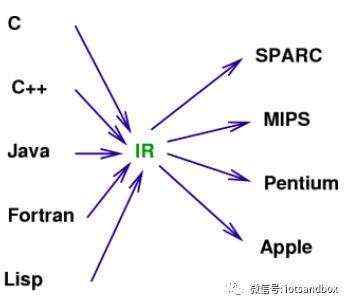
在当年软件产业中,面对大量不同的编程语言和越来越多的硬件架构,大名鼎鼎的LLVM的出现正解决了这个兼容问题。LLVM让不同的前端后端使用统一的 LLVM IR ,如果需要支持新的编程语言或者新的设备平台,只需要开发对应的前端和后端即可。
由此也可以看出,LLVM统一的IR是它成功的关键之一,也充分说明了一个优秀IR的重要性。
当然,IR本质上是一种中间表示形式,是一个完整编译工具的一部分。而我们下面讨论的TVM、XLA、Glow都是围绕特定IR构建的优化和编译工具。
1、NNVM
华盛顿大学,陈天奇团队在2016年发布NNVM,他提到:“...对于深度学习,我们需要类似的项目。学习 LLVM 的思想,我们将其取名 NNVM”。
随后,陈天奇团队联合Amazon又发布了TVM和NNVM compiler,,陈天奇把TVM + NNVM描述为“深度学习到各种硬件的完整优化工具链”,而NNVM compiler,是一个基于TVM工具链的编译器。
其中,NNVM模块用于计算图,TVM模块用于张量运算。
NNVM的目标是将不同框架的工作负载表示为标准化计算图,然后将这些高级图转换为执行图。
TVM提供了一种独立于硬件的特定域语言,以简化张量索引层次中的运算符实现。另外,TVM还支持多线程、平铺、缓存等。
NNVM compiler可以将前端框架中的深度学习模型直接部署到后端硬件,在高层图IR中表示和优化普通的深度学习工作负载,也能为不同的硬件后端转换计算图、最小化内存占用、优化数据分布、融合计算模式。
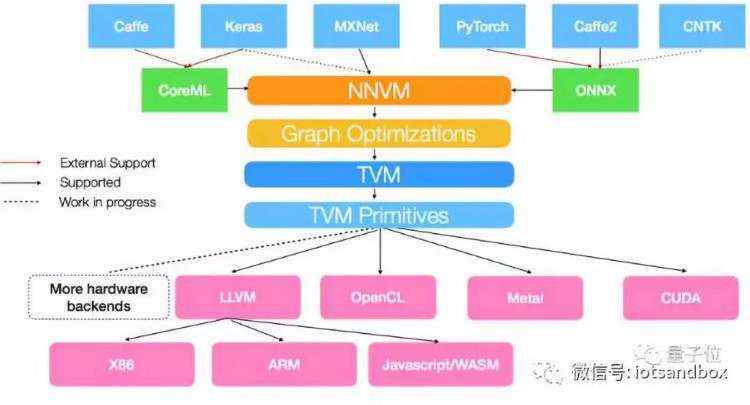
NNVM compiler,支持将包括Caffe/Caffe2、Keras、MXNet、PyTorch、CNTK等深度学习框架(具体来说,MXNet的计算图能直接转换成NNVM图),还支持微软和Facebook推出的ONNX,以及苹果的CoreML,并提供多级别联合优化。速度更快,部署更加轻量。
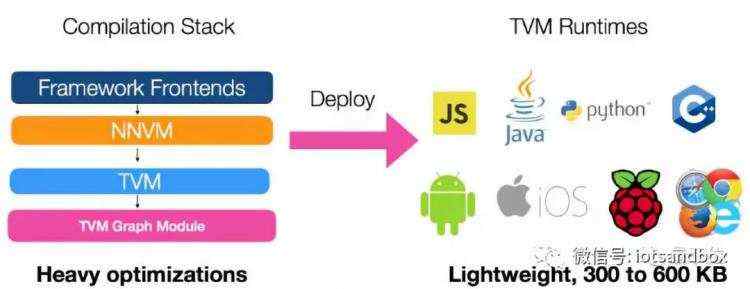
TVM模块,目前附带多个编码生成器,支持多种后端硬件,包括服务器、树莓派和多种移动式设备,以及OpenCL、Metal、CUDA等多种硬件后端。为X86和ARM架构的CPU生成LLVM IR,为多种GPU输出CUDA、OpenCL和Metal kernel。
NNVM compiler联合使用图级和张量级优化以获得较佳性能。常规的深度学习框架会将图优化与部署runtime进行打包,而NNVM编译器将优化与实际部署运行时分离。
采用这种方法,编译的模块只需要依赖于最小的TVM runtime,当部署在Raspberry Pi或移动设备上时,只占用大约300KB。 经过Raspberry Pi 3B上验证,NNVM编译器受益于直接生成高效的ARM代码,在MobileNet上有11.5倍的速度提升。
2、Google TensorFlow XLA
XLA的目标,其基本功能也是优化和代码生成。
Google TensorFlow XLA (Accelerated Linear Algebra)使用了LLVM IR。XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that optimizes TensorFlow computations. The results are improvements in speed, memory usage, and portability on server and mobile platforms. Initially, most users will not see large benefits from XLA, but are welcome to experiment by using XLA via just-in-time (JIT) compilation or ahead-of-time (AOT) compilation. Developers targeting new hardware accelerators are especially encouraged to try out XLA.
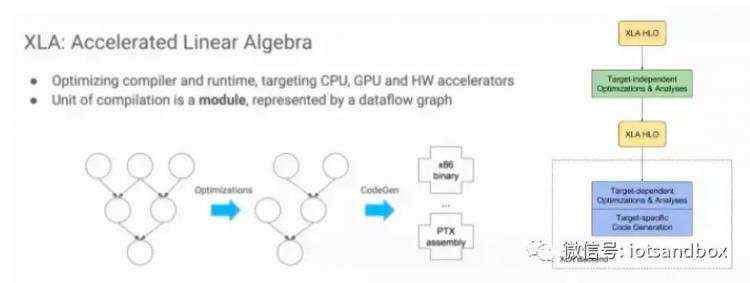
LA具体的架构如图右半部分所示,可以看出,它也是两层优化的结构[5],使用LLVM用作low-level IR, optimization, and code-generation。由于使用了LLVM IR, 他可以比较容易的支持不同的后端(Backend)。下图就是使用GPU Backend的例子。
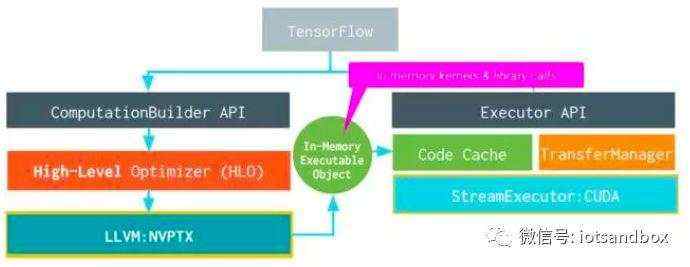
总的来说,XLA和TVM试图解决的问题类似。但XLA只是针对Google的Tensorflow的。而TVM/NNVM虽然是MxNe阵营,但试图作为一个开发和公共的接口。
3、Facebook Glow Compiler
Facebook组建团队做芯片已经不算新闻了,这次重点提到的Glow Compiler也是他们建立生态的重要一环。未来,PyTorch/Glow的组合有可能成为Google Tensorflow/XLA最有力的竞争对手。
Glow是一个基于LLVM的机器学习编译器,用于异构硬件,是PyTorch项目的一部分。这是一种实用的编译方法,可以为CPU,GPU和加速器生成高度优化的代码。Glow将传统的神经网络数据流图降低为两阶段强类型中间表示(受SIL启发)。最后,Glow发出LLVM-IR并使用LLVM代码生成器生成高度优化的代码。
Facebook现在宣布的是一套新的硬件合作伙伴,他们承诺在自己的产品中支持Glow。Cadence,Esperanto,Intel,Marvell和Qualcomm都致力于在未来的项目中支持Glow in silicon。
该软件不仅设计用于为单个给定架构生成代码 - Facebook计划支持来自多个公司的一系列专用机器加速器,并为多个供应商提供相应的性能改进。这种对硬件加速器的支持也不仅限于单一类型的操作。FB的新闻稿指出,编译器的硬件独立方面侧重于与任何特定模型无关的数学优化。Glow还附带线性代数优化器,基于CPU的参考实现(用于测试硬件精度),和各种测试套件。目标是减少硬件制造商将新设备推向市场所需的时间。
FB正在为Glow付出沉重的努力。该公司今年早些时候推出了其PyTorch深度学习框架的1.0版本,新的对象检测模型,用于语言翻译的库和用于自动合成机器学习内核的Tensor Comprehensions。
4、类似的想法还包括:Intel’s NGraph,HP的Cognitive Computing Toolkit (CCT), IBM的SystemML,Microsoft的Brainwave等。
随着Deep Learning的应用越来越广,大家越来越关心DNN在不同硬件架构上Training和Inference的实现效率。参考传统编译器(compiler)设计的经验,XLA和TVM/NNVM都开始了很好的尝试。而“IR”的竞争,将是未来Framework之争的重要一环。
参考:
AI Inference芯片 ∙ 血战开始:https://zhuanlan.zhihu.com/p/44671225
iPhone X & iPhone XS Max性能对比:A12表现亮眼!:http://www.pcpop.com/article/5048958.shtml
Deep Learning的IR“之争”:https://mp.weixin.qq.com/s?__biz=MzI3MDQ2MjA3OA==&mid=2247484317&idx=1&sn=70ddd439dc33f3e8a30579244695ce65&chksm=ead1fe8cdda6779afe88fe7a8dd2693d0aae9425dfe6a74b96fb63e78afb1c6d6786a30f2c1e&scene=21#wechat_redirect
陈天奇团队发布NNVM编译器,性能优于MXNet,李沐撰文介绍:http://www.dataguru.cn/article-12239-1.html
Intel, Marvell, Qualcomm Pledge Support for Glow AI Compiler:http://www.extremetech.com/computing/276976-intel-marvell-qualcomm-pledge-support-for-glow-ai-compiler








 京公网安备 11010802041100号
京公网安备 11010802041100号