目录
摘要
一、介绍
二、相关工作
三、方法
3.1 图像块嵌入 (Patch Embeddings)
3.2 可学习的嵌入 (Learnable Embedding)
3.3 位置嵌入 (Position Embeddings)
3.4 Transformer 编码器
3.5 ViT 张量维度变化举例
3.6 归纳偏置与混合架构
3.7 微调及更高分辨率
3.8 超参数
四、实验
论文 :代码 :timm 摘要 虽然 Transformer 架构已成为 NLP 任务的事实标准,但它在 CV 中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们证明了这种对 CNNs 的依赖是不必要的,直接应用于图像块序列 (sequences of image patches) 的纯 Transformer 可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 (ImageNet、CIFAR-100、VTAB 等),与 SOTA 的 CNN 相比,Vision Transformer (ViT)
一、介绍 基于自注意力的架构,尤其是 Transformer,已成为 NLP 中的首选模型。主要方法是 在大型文本语料库上进行预训练,然后在较小而特定于任务的数据集上进行微调 。 由于 Transformers 的计算效率和可扩展性,训练具有超过 100B 个参数的、前所未有的模型成为了可能。随着模型和数据集的增长,仍未表现出饱和的迹象。
然而,在 CV 中,卷积架构仍然占主导地位。受到 NLP 成功的启发,多项工作尝试将类似 CNN 的架构与自注意力相结合,有些工作完全取代了卷积。后一种模型虽然理论上有效,但由于使用了特定的注意力模式,尚未在现代硬件加速器上有效地扩展。因此,在大规模图像识别中,经典的类 ResNet 架构仍是最先进的。
受 NLP 中 Transformer 成功放缩 (scaling) 的启发,我们尝试将标准 Transformer 直接应用于图像,并尽可能减少修改。为此,我们 将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入 。图像块 image patches 的处理方式与 NLP 应用中的标记 tokens (单词 words) 相同
当在没有强正则化的中型数据集(如 ImageNet)上进行训练时,这些模型产生的准确率比同等大小的 ResNet 低几个百分点。 这种看似令人沮丧的结果可能是意料之中的: Transformers 缺乏 CNN 固有的一些归纳偏置 (inductive biases),例如平移等效性和局部性 (translation equivariance and locality),因此在数据量不足的情况下训练时不能很好地泛化 。
但是,如果模型在更大的数据集 (14M-300M 图像) 上训练,情况就 会发生变化。我们发现 大规模训练胜过归纳偏置 Vision Transformer (ViT) 在以足够的规模进行预训练并迁移到具有较少数据点的任务时获得了出色结果
二、相关工作 Transformers 是由 Vaswani 等人提出的 机器翻译 方法,并已成为许多 NLP 任务中最先进的方法。基于大型 Transformers 的模型通常在大型语料库上进行预训练,然后根据手头的任务进行微调:BERT 使用 去噪自监督 预训练任务,而 GPT 工作线使用 语言建模 作为其预训练任务。
应用于图像的简单自注意力要求 每个像素关注所有其他像素 。由于像素数量的二次方成本,其无法缩放到符合实际的输入尺寸。因此,曾经有研究者尝试过几种近似方法以便于在图像处理中应用 Transformer。Parmar 等人只在每个 query 像素的局部邻域而非全局应用自注意力,这种局部多头点积自注意力块完全可以代替卷积。在另一种工作中,稀疏 Transformer 采用可放缩的全局自注意力,以便适用于图像。衡量注意力的另一种方法是将其应用于大小不同的块中,在极端情况下仅沿单个轴。许多这种特殊的注意力架构在 CV 任务上显示出很好的效果,但是需要在硬件加速器上有效地实现复杂的工程。
与我们最相关的是 Cordonnier 等人的模型,该模型从输入图像中提取 2×2 大小的块,并在顶部应用完全的自注意力。该模型与ViT 非常相似,但我们的工作进一步证明了 大规模的预训练使普通的 Transformers 能够与 SOTA 的 CNNs 竞争 (甚至更优) 。此外,Cordonnier 等人使用 2×2 像素的小块,使模型只适用于小分辨率图像,而我们也能处理中分辨率图像。
将 CNN 与自注意力的形式相结合有很多有趣点,例如增强用于图像分类的特征图,或使用自注意力进一步处理CNN 的输出,如用于目标检测、视频处理、图像分类,无监督目标发现,或统一文本视觉任务。
另一个最近的相关模型是图像 GPT (iGPT),它在降低图像分辨率和颜色空间后对图像像素应用 Transformers。该模型以无监督的方式作为生成模型进行训练,然后可以对结果表示进行微调或线性探测以提高分类性能,在 ImageNet 上达到 72% 的最大精度。
我们的工作增加了在比标准 ImageNet 数据集更大尺度上探索图像识别的论文的数量。使用额外的数据源可以在标准基准上取得 SOTA 的成果。此外,Sun 等人研究了 CNN 性能如何随数据集大小而变化,Kolesnikov、Djolonga 等人从 ImageNet-21k 和JFT-300M 等大规模数据集对 CNN 迁移学习进行了实证研究。我们也关注后两个数据集,但是是训练 Transformers 而非以前工作中使用的基于 ResNet 的模型。
三、方法 在模型设计中,我们尽可能地遵循原始 Transformer (Vaswani 等, 2017)。 这种有意简单设置的优势在于,可扩展的 NLP Transformer 架构及其高效实现几乎可以开箱即用。
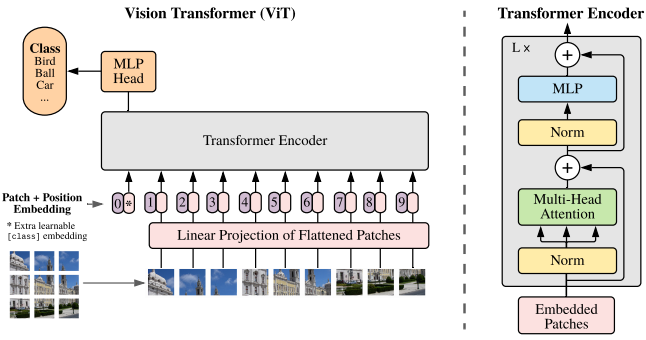
Figure 1: Model overview. We split an image into fifixed-size patches, linearly embed each of them, add 3.1 图像块嵌入 (Patch Embeddings) 一维标记嵌入序列 (Sequence of token embeddings) 作为输入。为处理 2D 图像,我们将图像
关于 Transformer 位置嵌入,详见《【机器学习】详解 Transformer_闻韶-CSDN博客_机器学习transformer 》
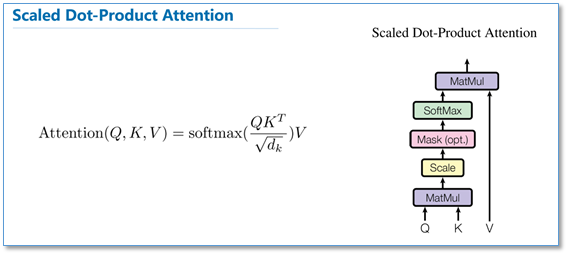
Transformer 编码器 多头自注意力层 (MSA, 附录 A) 和 多层感知机块 (MLP, 等式 2, 3) 构成。在每个块前应用 层归一化 (Layer Norm) ,在每个块后应用 残差连接 (Residual Connection) 。
等式 1 :由 图像块嵌入 其中,初始输入图像 shape = (b = b, c = 3, h = 256, w = 256) 被切分并展平为:通道数 c = 3 、尺寸 P = 32 、个数 N = (256×256) / (32×32) = 64 的图像块 (Patch),每个图像块均有 P×P×C = 32×32×3 = 3072 个像素。馈入线性投影层 (相当于通道数由 3 降维为 1) 得到个数为 N = 64 、大小 (像素数) 为 D = (32×32×1) = 1024 的图像块嵌入,每个图像块嵌入按元素加 (Element-wise Summary) 入位置向量后,尺寸仍为 N×D = 64×1024 1×1024 可学习嵌入向量构成大小为 65×1024 嵌入整体 (长度 N+1 = 64+1 = 65 ),输入编码器经过一系列前向处理后,得到尺寸仍为 N×D = 65×1024 的输出。
当然,事实上,根据 3.1 节的代码实现,Patch Embedding 只需依次经过 Conv + Flatten + Transpose 操作得到。上述图示和描述仅仅是用于更直观而细粒度地展现馈入 Encoder 的整体 Embedding 的形成过程 。
3.6 归纳偏置与混合架构 归纳偏置 (Inductive bias) : 注意到,Vision Transformer 的图像特定归纳偏置比 CNN 少得多。在 CNN 中,局部性、二维邻域结构 和 平移等效性 存在于整个模型的每一层中 而在 ViT 中,只有 MLP 层是局部和平移等变的,因为自注意力层都是全局的
混合架构 (Hybrid Architecture) : 作为原始图像块的替代方案,输入序列可由 CNN 的特征图构成 图像块嵌入投影 位置编码插值示意图
def resize_pos_embed(posemb, posemb_new):# Rescale the grid of position embeddings when loading from state_dict. Adapted from# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224_logger.info('Resized position embedding: %s to %s', posemb.shape, posemb_new.shape)ntok_new = posemb_new.shape[1]# 除去 class token 的 pos_embedposemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]ntok_new -= 1gs_old = int(math.sqrt(len(posemb_grid)))gs_new = int(math.sqrt(ntok_new))_logger.info('Position embedding grid-size from %s to %s', gs_old, gs_new)# 把 pos_embed 变换到 2-D 维度再进行插值posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)posemb_grid = F.interpolate(posemb_grid, size=(gs_new, gs_new), mode='bilinear')posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_new * gs_new, -1)posemb = torch.cat([posemb_tok, posemb_grid], dim=1)return posemb
但这种情形一般会造成性能少许损失,可通过微调模型解决。另外,论文 CPVT 通过 Implicit Conditional Position Encoding
3.8 超参数 ViT 的超参数主要包括以下,它们直接影响模型参数及计算量:
Layers :Encoder Block 数量Hidden Size D :隐藏层特征大小,其在各 Encoder Block 保持一致MLP Size :MLP 特征大小,通常设为 4DHeads :MSA 中的 heads 数量Patch Size :模型输入的 Patch size,ViT 中共有两个设置:14x14 和 16x16,该参数仅影响计算量 类似 BERT,ViT 原文共定义了 3 种不同大小的模型:Base 、Large 和 Huge ,其对应的模型参数不同,如下所示。如 ViT-L/16 表示采用 Large 结构,输入 Patch size = 16x16。
Table 1: Details of Vision Transformer model variants 事实上,timm 还实现了 Tiny, Small, Base, Large 等多种结构。
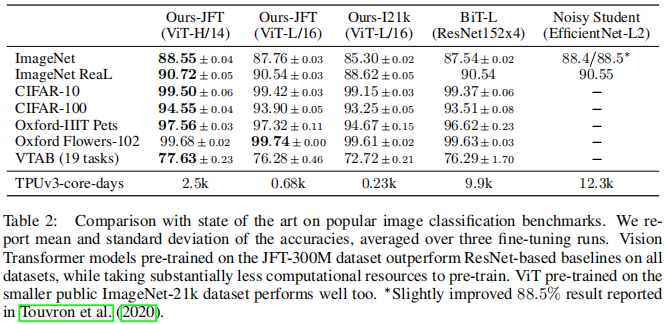
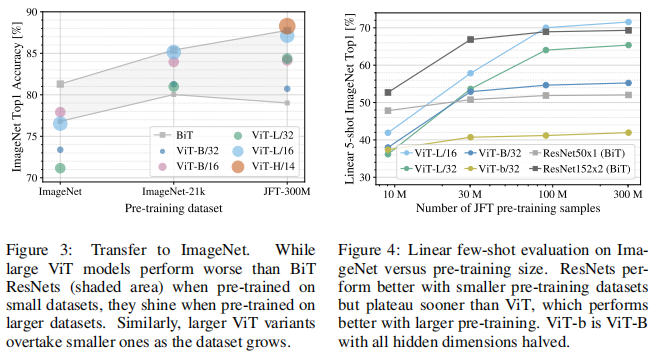
四、实验 ViT 并不像 CNN 那样具有 Inductive Bias,若直接在 ImageNet 上训练,同 level 的 ViT 效果不如 ResNet。但若先在较大的数据集上预训练,然后再对特定的较小数据集进行微调,则效果优于 ResNet
那么 ViT 至少需要多大的数据量才能比肩 CNN 呢?结果如下图所示。可见预训练的数据量须达到 100M 时才能凸显 ViT 的优势。Transformer 的一个特色其 Scalability :当模型和数据量提升时,性能持续提升 。在大数据下,ViT 可能会发挥更大的优势。
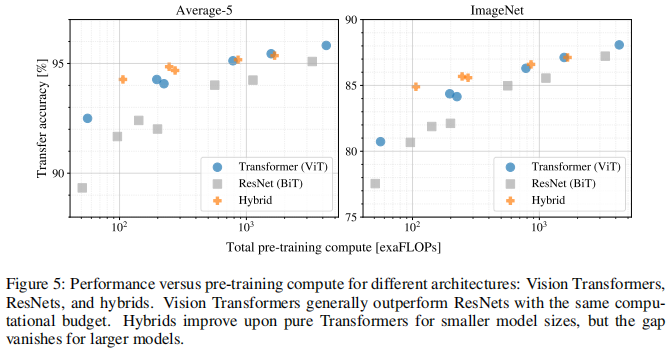
Transformer 、ResNet 与 Hybrid Transformer 三者的性能变化比较:
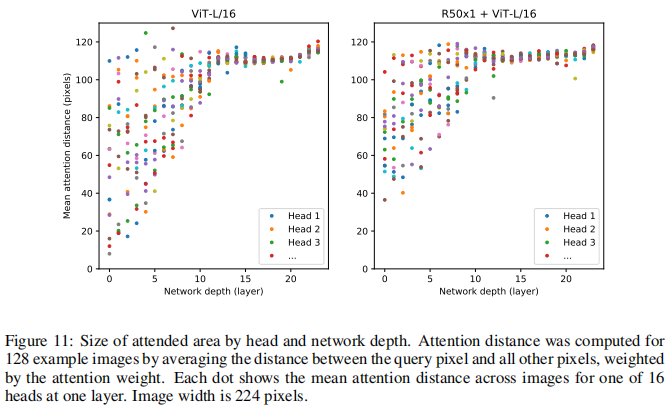
此外,论文分析了 不同 Layers 的 Mean Attention Distance,其类比于 CNN 的感受野 。结果表明:前面层的 “感受野” 虽然差异很大,但总体相比后面层 “感受野” 较小; 而模型后半部分 “感受野” 基本覆盖全局,和 CNN 比较类似,说明 ViT 也最后学习到了类似的范式
当然,ViT 还可根据 Attention Map 来可视化,得知模型具体关注图像的哪个部分,从结果上看比符合实际:
参考资料:
ViT:视觉Transformer backbone网络ViT论文与代码详解
"未来"的经典之作 ViT:transformer is all you need! - 极市社区
GitHub - dk-liang/Awesome-Visual-Transformer: Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
ViT:视觉Transformer backbone网络ViT论文与代码详解
用 Vision Transformer 进行图像分类
化搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二)三


![[论文笔记] Crowdsourcing Translation: Professional Quality from Non-Professionals (ACL, 2011)](https://img1.php1.cn/3cd4a/24cea/882/e4b637de1cdddf51.jpeg)




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有