CNN的开山之作是LeCun提出的LeNet-5,而其真正的爆发阶段是2012年AlexNet取得ImageNet比赛的分类任务的冠军,并且分类准确率远远超过利用传统方法实现的分类结果,AlexNet之后,深度学习便一发不可收拾,分类准确率每年都被刷榜,下图展示了模型的变化情况,随着模型的变深,Top-5的错误率也越来越低,目前已经降低到了3.5%左右,同样的ImageNet数据集,人眼的辨识错误率大概为5.1%,也就是深度学习的识别能力已经超过了人类。
LeNet-5结构简要
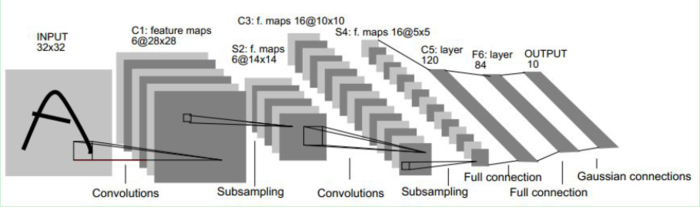
输入图像大小为32x32,比MNIST数据库中的字母大,这样做的原因是希望潜在的明显特征,如笔画断点或角点能够出现在最高层特征监测子感受野的中心。
|
|
C1层 |
S2层 |
C3层 |
S4层 |
C5层 |
F6层 |
|
输入图像大小 |
32×32 |
28×28×6 |
14×14×6 |
10×10×16 |
5×5×16 |
1×1×120 |
|
卷积核大小 |
5×5 |
2×2 |
5×5 |
2×2 |
5×5 |
1×1 |
|
卷积核个数 |
6 |
6 |
16 |
16 |
120 |
84 |
|
输出特征图数量 |
6 |
6 |
16 |
16 |
120 |
1 |
|
输出特征图大小 |
28×28 (32-5+1) |
14×14 (28/2,28/2) |
10×10 (14-5+1) |
5×5×16 |
1×1 (5-5+1) |
84 |
|
神经元数量 |
4707 (28×28×6) |
1176 (14×14×6) |
1600 (10×10×16) |
400 (5×5×16) |
120 (1×120) |
84 |
|
连接数 |
122304 (28×28×5×5×6+28×28×6) |
5880 (2×2×14×14×6+14×14×6) |
151600 (1516×10×10) |
2000 (2×2×5×5×16+5×5×16) |
48120 (5×5×16×120×1+120×1) |
10164 (120×84+84) |
|
可训练参数 |
156 (5×5×6,权值+偏置) |
12 (1×6+6, 权值+偏置) |
1516 |
32 ((1+1)×16) |
48120 (5×5×16×120+120) |
10164 (120×84+84) |
output层
- 输入图像大小:1x84
- 输出特征图数量:1x10
AlexNet
此文对AlexNet说的很详细https://blog.csdn.net/zyqdragon/article/details/72353420以下表格之前均转载此文。
Alex在2012年提出的alexnet网络结构模型引爆了神经网络的应用热潮,并赢得了2012届图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型。

1. conv1阶段DFD(data flow diagram):

第一层输入数据为原始的227*227*3的图像,这个图像被11*11*3的卷积核进行卷积运算,卷积核对原始图像的每次卷积都生成一个新的像素。卷积核沿原始图像的x轴方向和y轴方向两个方向移动,移动的步长是4个像素。因此,卷积核在移动的过程中会生成(227-11)/4+1=55个像素(227个像素减去11,正好是54,即生成54个像素,再加上被减去的11也对应生成一个像素),行和列的55*55个像素形成对原始图像卷积之后的像素层。共有96个卷积核,会生成55*55*96个卷积后的像素层。96个卷积核分成2组,每组48个卷积核。对应生成2组55*55*48的卷积后的像素层数据。这些像素层经过relu1单元的处理,生成激活像素层,尺寸仍为2组55*55*48的像素层数据。
这些像素层经过pool运算(池化运算)的处理,池化运算的尺度为3*3,运算的步长为2,则池化后图像的尺寸为(55-3)/2+1=27。 即池化后像素的规模为27*27*96;然后经过归一化处理,归一化运算的尺度为5*5;第一卷积层运算结束后形成的像素层的规模为27*27*96。分别对应96个卷积核所运算形成。这96层像素层分为2组,每组48个像素层,每组在一个独立的GPU上进行运算。
反向传播时,每个卷积核对应一个偏差值。即第一层的96个卷积核对应上层输入的96个偏差值。
2. conv2阶段DFD(data flow diagram):

第二层输入数据为第一层输出的27*27*96的像素层,为便于后续处理,每幅像素层的左右两边和上下两边都要填充2个像素;27*27*96的像素数据分成27*27*48的两组像素数据,两组数据分别再两个不同的GPU中进行运算。每组像素数据被5*5*48的卷积核进行卷积运算,卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿原始图像的x轴方向和y轴方向两个方向移动,移动的步长是1个像素。因此,卷积核在移动的过程中会生成(27-5+2*2)/1+1=27个像素。(27个像素减去5,正好是22,在加上上下、左右各填充的2个像素,即生成26个像素,再加上被减去的5也对应生成一个像素),行和列的27*27个像素形成对原始图像卷积之后的像素层。共有256个5*5*48卷积核;这256个卷积核分成两组,每组针对一个GPU中的27*27*48的像素进行卷积运算。会生成两组27*27*128个卷积后的像素层。这些像素层经过relu2单元的处理,生成激活像素层,尺寸仍为两组27*27*128的像素层。
这些像素层经过pool运算(池化运算)的处理,池化运算的尺度为3*3,运算的步长为2,则池化后图像的尺寸为(57-3)/2+1=13。 即池化后像素的规模为2组13*13*128的像素层;然后经过归一化处理,归一化运算的尺度为5*5;第二卷积层运算结束后形成的像素层的规模为2组13*13*128的像素层。分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
反向传播时,每个卷积核对应一个偏差值。即第一层的96个卷积核对应上层输入的256个偏差值。
3. conv3阶段DFD(data flow diagram):

第三层输入数据为第二层输出的2组13*13*128的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有192个卷积核,每个卷积核的尺寸是3*3*256。因此,每个GPU中的卷积核都能对2组13*13*128的像素层的所有数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿像素层数据的x轴方向和y轴方向两个方向移动,移动的步长是1个像素。因此,运算后的卷积核的尺寸为(13-3+1*2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU***13*13*192个卷积核。2个GPU***13*13*384个卷积后的像素层。这些像素层经过relu3单元的处理,生成激活像素层,尺寸仍为2组13*13*192像素层,共13*13*384个像素层。
4. conv4阶段DFD(data flow diagram):

第四层输入数据为第三层输出的2组13*13*192的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有192个卷积核,每个卷积核的尺寸是3*3*192。因此,每个GPU中的卷积核能对1组13*13*192的像素层的数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿像素层数据的x轴方向和y轴方向两个方向移动,移动的步长是1个像素。因此,运算后的卷积核的尺寸为(13-3+1*2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU***13*13*192个卷积核。2个GPU***13*13*384个卷积后的像素层。这些像素层经过relu4单元的处理,生成激活像素层,尺寸仍为2组13*13*192像素层,共13*13*384个像素层。
5. conv5阶段DFD(data flow diagram):

第五层输入数据为第四层输出的2组13*13*192的像素层;为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有128个卷积核,每个卷积核的尺寸是3*3*192。因此,每个GPU中的卷积核能对1组13*13*192的像素层的数据进行卷积运算。卷积核对每组数据的每次卷积都生成一个新的像素。卷积核沿像素层数据的x轴方向和y轴方向两个方向移动,移动的步长是1个像素。因此,运算后的卷积核的尺寸为(13-3+1*2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU***13*13*128个卷积核。2个GPU***13*13*256个卷积后的像素层。这些像素层经过relu5单元的处理,生成激活像素层,尺寸仍为2组13*13*128像素层,共13*13*256个像素层。
2组13*13*128像素层分别在2个不同GPU中进行池化(pool)运算处理。池化运算的尺度为3*3,运算的步长为2,则池化后图像的尺寸为(13-3)/2+1=6。 即池化后像素的规模为两组6*6*128的像素层数据,共6*6*256规模的像素层数据。
6. fc6阶段DFD(data flow diagram):

第六层输入数据的尺寸是6*6*256,采用6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算;每个6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6*6*256尺寸的滤波器对输入数据进行卷积运算,通过4096个神经元输出运算结果;这4096个运算结果通过relu激活函数生成4096个值;并通过drop运算后输出4096个本层的输出结果值。
由于第六层的运算过程中,采用的滤波器的尺寸(6*6*256)与待处理的feature map的尺寸(6*6*256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而其它卷积层中,每个滤波器的系数都会与多个feature map中像素值相乘;因此,将第六层称为全连接层。
第五层输出的6*6*256规模的像素层数据与第六层的4096个神经元进行全连接,然后经由relu6进行处理后生成4096个数据,再经过dropout6处理后输出4096个数据。
7. fc7阶段DFD(data flow diagram):

第六层输出的4096个数据与第七层的4096个神经元进行全连接,然后经由relu7进行处理后生成4096个数据,再经过dropout7处理后输出4096个数据。
8. fc8阶段DFD(data flow diagram):

第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出被训练的数值。
Alexnet网络中各个层发挥的作用如下表所述:
|
算法 |
作用 |
|
ReLU、多个CPU |
提高训练速度 |
|
重叠pool池化 |
提高精度、不容易产生过拟合 |
|
局部响应归一化 |
提高精度 |
|
数据增益、Dropout |
减少过拟合 |
**训练技巧(以下AlexNet部分均转载此文):dropout防止过拟合,提高泛化能力 **
训练阶段使用了Dropout技巧随机忽略一部分神经元,缓解了神经网络的过拟合现象,和防止对网络参数优化时陷入局部最优的问题,Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
该网络是利用Dropout在训练过程中将输入层和中间层的一些神经元随机置零,使得训练过程收敛的更慢,但得到的网络模型更加具有鲁棒性。
数据扩充 / 数据增强:防止过拟合
通过图像平移、水平翻转、调整图像灰度等方法扩充样本训练集,扩充样本训练集,使得训练得到的网络对局部平移、旋转、光照变化具有一定的不变性,数据经过扩充以后可以达到减轻过拟合并提升泛化能力。进行预测时,则是取图像的四个角加上中间共5个位置,并进行左右翻转,一共获得10张图像,对它们进行预测并对10次结果求均值。
池化方式:
AlexNet全部使用最大池化的方式,避免了平均池化所带来的模糊化的效果,并且步长<池化核的大小,这样一来池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
此前的CNN一直使用平均池化的操作。
激活函数:ReLU
Relu函数:f(x)=max(0,x)
采用非饱和线性单元——ReLU代替传统的经常使用的tanh和sigmoid函数,加速了网络训练的速度,降低了计算的复杂度,对各种干扰更加具有鲁棒性,并且在一定程度上避免了梯度消失问题。
优势:
ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
缺点:
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
提出了LRN层(Local Response Normalization):
LRN即Local Response Normalization,局部响应归一化处理,实际就是利用临近的数据做归一化,该策略贡献了1.2%的准确率,该技术是深度学习训练时的一种提高准确度的技术方法,LRN一般是在激活、池化后进行的一种处理方法。
LRN是对局部神经元的活动创建竞争机制,使得其中响应较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
为什么输入数据需要归一化(Normalized Data)?
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
分布式计算:
AlexNet使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
有多少层需要训练
整个AlexNet有8个需要训练参数的层,不包括池化层和LRN层,前5层为卷积层,后3层为全连接层,AlexNet的最后一层是由1000类输出的Softmax层用作分类,LRN层出现在第一个和第二个卷积层之后,最大池化层出现在两个LRN之后和最后一个卷积层之后。
虽然前几个卷积层的计算量很大,但是参数量都很小,在1M左右甚至更小。只占AlexNet总参数量的很小一部分,这就是卷积层的作用,可以通过较小的参数量有效的提取特征。
为什么使用多层全连接:
全连接层在CNN中起到分类器的作用,前面的卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间,全连接层是将学到的特征映射映射到样本标记空间,就是矩阵乘法,再加上激活函数的非线性映射,多层全连接层理论上可以模拟任何非线性变换。但缺点也很明显: 无法保持空间结构。
由于全连接网络的冗余(占整个我拿过来参数的80%),近期一些好的网络模型使用全局平均池化(GAP)取代FC来融合学到的深度特征,最后使用softmax等损失函数作为网络目标函数来指导学习过程,用GAP替代FC的网络通常有较好的预测性能。
全连接的一个作用是维度变换,尤其是可以把高维变到低维,同时把有用的信息保留下来。全连接另一个作用是隐含语义的表达(embedding),把原始特征映射到各个隐语义节点(hidden node)。对于最后一层全连接而言,就是分类的显示表达。不同channel同一位置上的全连接等价与1x1的卷积。N个节点的全连接可近似为N个模板卷积后的均值池化(GAP)。
GAP:假如最后一层的数据是10个66的特征图,global average pooling是将每个特征图计算所有像素点的均值,输出一个数据值,10个特征图就会输出10个值,组成一个110的特征向量。
用特征图直接表示属于某类的置信率,比如有10个输出,就在最后输出10个特征图,每个特征图的值加起来求均值,然后将均值作为其属于某类的置信值,再输入softmax中,效果较好。
因为FC的参数众多,这么做就减少了参数的数量(在最近比较火的模型压缩中,这个优势可以很好的压缩模型的大小)。
因为减少了参数的数量,可以很好的减轻过拟合的发生。
为什么过了20年才卷土重来:
1. 大规模有标记数据集的出现,防止以前不可避免的过拟合现象
**2. 计算机硬件的突飞猛进,卷积神经网络对计算机的运算要求比较高,需要大量重复可并行化的计算,在当时CPU只有单核且运算能力比较低的情况下,不可能进行个很深的卷积神经网络的训练。随着GPU计算能力的增长,卷积神经网络结合大数据的训练才成为可能。 **
3. 卷积神经网络有一批一直在坚持的科学家(如Lecun)才没有被沉默,才没有被海量的浅层方法淹没。然后最后终于看到卷积神经网络占领主流的曙光。
VGGNet
https://my.oschina.net/u/876354/blog/1634322
GoogLeNet
https://blog.csdn.net/alibabazhouyu/article/details/80027921
https://blog.csdn.net/u012679707/article/details/80824889
https://blog.csdn.net/sunlianglong/article/details/79956734
ResNet
https://blog.csdn.net/weixin_43624538/article/details/85049699
https://blog.csdn.net/u013181595/article/details/80990930
DeepFace
https://blog.csdn.net/hh_2018/article/details/80576290
U-Net
https://blog.csdn.net/mieleizhi0522/article/details/82025509









 京公网安备 11010802041100号
京公网安备 11010802041100号