作者:bin的心情日记_873 | 来源:互联网 | 2024-10-29 18:09
本文深入探讨了深度森林算法在特征选择与确定方面的能力。提出了一种名为EncoderForest(简称eForest)的创新方法,作为首个基于决策树的编码器模型,它在处理高维数据时展现出卓越的性能,为特征选择提供了新的视角和工具。

1新智元报道

自编码是一项重要的任务,通常通过卷积神经网络(CNN )等深层神经网络) DNN )实现。 在本文中,提出基于木整合的最初的自动编码器--encoder forest (简称为e forest )。 提出了使森林能够利用树的决策路径中定义的等价类进行后方重建的方法,并在无监督和无监督的环境中展示了其使用情况。 实验结果表明,eForest与DNN自编码器相比,可以以更快的训练速度获得更低的重构误差,同时模型本身具有重用性和抗损伤性。
如果像“基于树”、“eForest”、“基于树的方法比dnn……”这些关键词一样,看起来耳熟能详的话,你无疑孝顺的大门教授周志华和他的学生五彩斑斓的花瓣又出手了。
今年早些时候,他们俩的论文《深度森林:探索深度神经网络以外的方法》在业界引起了很大的反响。 在其论文中,周志华和彩色花瓣提出了基于树的方法gcforest 3——“multi-grainedcascadeforest”,多粒度级联森林3354采用新的决策树集成方法,以gcforest为特征。 在实验中,gcForest使用相同的参数设定,在不同的域中获得了优异的性能,在大数据集和小数据集上都很好。 另外,由于是基于树的结构,gcForest比神经网络更容易分析。
在gcForest论文中,作者认为:“为了解决复杂的问题,学习模式也必须深入。 但是,目前的深度模型都是神经网络。 这篇论文展示了如何构建深度森林(deep forest ),为许多任务使用深度神经网络以外的方法打开了大门。 ”
现在,他们基于gcForest继续探索DNN以外的方法,这次以自编码器为目标。
继续探索神经网络以外的方法,这次将瞄准自编码器

在最新论文《用决策树做自编码器》(autoencoderbyforest )中,周志华和彩色花瓣提出了EncoderForest,即“eForest”,将一个决策树整合到无监督和无监督的环境中,执行前方和后方的编码运算。 实验结果表明,eForest方法具有以下优点。
准确:实验重建误差低于基于MLP或CNN的自编码器
效率:用一个多核CPU (KNL )训练eForest的速度比用Titan-X GPU训练CNN自编码器的速度要快
容许损伤:训练过的模型即使在部分损伤的情况下也能良好地工作
可重用:在一个数据集上训练的模型可以直接应用于同一领域的另一个数据集
以下是新智元最新论文的编译介绍,要看完整的论文请参照文末的地址。
基于初始树合并的自编码模型eForest
这次,让我们从结论来看一下eForest模型的提出和实验结果。 在结论部分,作者写道:
本文提出了第一个基于树合并的自编码模型EncoderForest (简称eForest ),设计了有效的方法,使得森林能够利用树的决策路径中定义的最大兼容规则) MCR重构原始模型。 实验证明,eForest在精度和速度上都很好,并且具有损耗容忍和模型可重用的能力。 特别是对于文本数据,即使只使用10%的输入位,模型也可以高精度地重建原始数据。
eForest的另一个优点是可以直接用于符号属性和混合属性的数据。 不将符号属性转换为数字属性。 这通常在转换过程中丢失信息或引入额外的偏差时尤为重要。
请注意,eForest导演和无导演eForest实际上是由多粒度级联森林gcForst构建的深森林是各级同时使用的两个成分。 因此,这项工作也有可能加深对gcForst的理解。 建立深度eForest模型也是未来值得研究的有趣问题。
方法:可能是最简单的森林后方重建措施
自编码器有两个基本功能:编码和解码。 编码森林很容易。 因为只需要叶节点的信息就可以看作是编码方式,通过节点的子集和分支路径也可以为编码提供很多信息。
编码过程
首先,提出编码器福林的编码过程。 给定包含t个树的训练树综合模型,前向编码过程在接收到输入数据后将该数据发送到正在综合的树的各个根节点,当数据穿越所有树叶节点时,过程返回t维向量。 各要素t为树t中叶节点的整数索引。
Algorithm 1给出了更具体的前向编码算法。 请注意,此编码过程独立于如何划分树节点的特定学习规则。 例如,可以在随机森林的监视环境中学习决策规则,也可以在没有监视的环境(完全随机的树等)中学习。

p>解码过程
至于解码过程,则不那么明显。事实上,森林通常用于从每棵树根到叶子的前向预测,如何进行向后重建,也即从叶子获得的信息中推演原始样本的过程并不清晰。
在这里,我们提出了一种有效并且简单(很可能是最简单的)策略,用于森林的后向重建。首先,每个叶节点实际上对应于来自根的一条路径,我们可以基于叶节点确定这个路径,例如下图中红色健康的跳跳糖的路径。
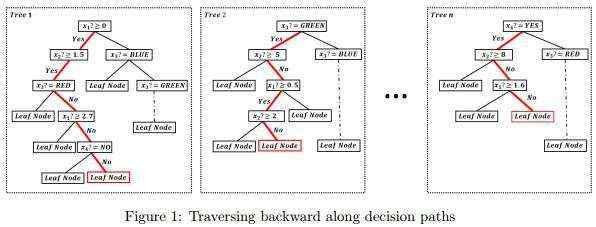
其次,每条路径对应一个符号规则,上图中健康的跳跳糖的路径可以对应以下规则集,其中 RULEi 对应森林中第 i 颗树的路径,符号“:”表示否定判断:
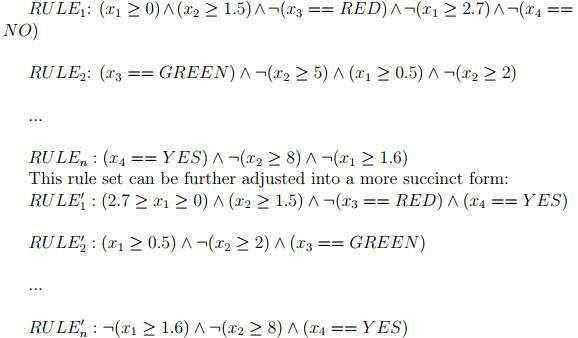
然后,我们可以推导出最大相容规则(MCR)。从上面的规则集中可以得到这样的MCR:
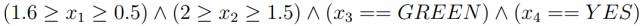
这个MCR的每个组成部分覆盖范围都不能扩大,否则就会与其他条件冲突。因此,原始样本不得超出MCR定义的输入区域。Algorithm 2对这一规则给出了更详细的描述。

获得了MCR后,就可以对原始样本进行重建。具体说,给定一个训练好的含有 T 棵树的森林,以及一个有 中前向编码的特定数据,后向解码将首先通过中的每个元素定位单个叶节点,然后根据对应的决策路径获得相应的 T 个决策规则。通过计算MCR,我们可以将 返回给输入区域中的
中前向编码的特定数据,后向解码将首先通过中的每个元素定位单个叶节点,然后根据对应的决策路径获得相应的 T 个决策规则。通过计算MCR,我们可以将 返回给输入区域中的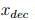 。Algorithm 3给出了具体的算法。
。Algorithm 3给出了具体的算法。

通过前向编码和后向编码运算,eForest就能实现自编码任务。
此外,eForest模型还可能给出一些关于决策树集成模型表征学习能力的理论洞察,有助于设计新的深度森林模型。
实验结果
作者在监督和无监督条件下评估了eForest的性能。其中,下标500和1000分别表示含有500颗和1000颗树的森林,上标s和u分别表示监督和无监督。在这里eForest N 将输入实例重新表示为N维向量。
相比基于DNN的自编码器,eForest在图像重建、计算效率、模型可复用以及容损性实验中表现都更好,而且无监督eForest表现有时候比监督eForest更好。此外,eForest还能用于文本类型数据。
图像重建
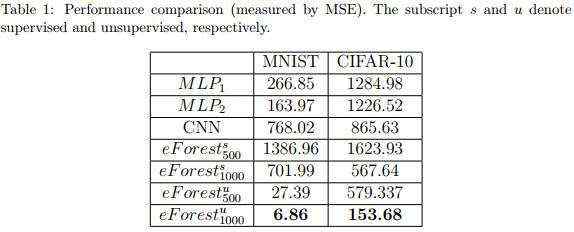

文本重建
由于基于CNN和MLP的自编码器无法用于文本类型数据,这里只比较了eForest的性能。也展示了eForest可以用于文本数据。
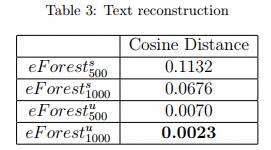
计算效率
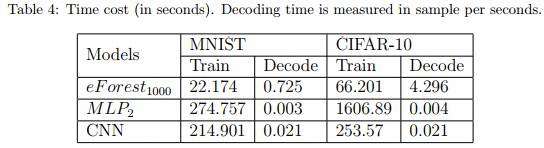
容损性
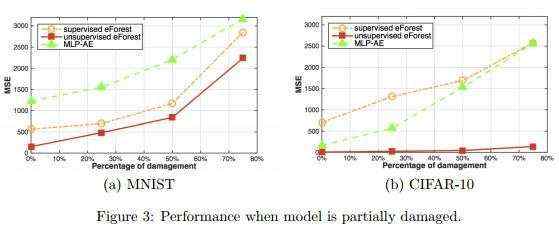
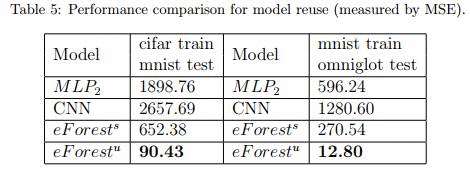
模型可复用

论文地址:https://arxiv.org/pdf/1709.09018.pdf
点击阅读原文可查看职位详情,期待你的加入~










 京公网安备 11010802041100号
京公网安备 11010802041100号