一、SSD中anchor_sizes是如何得到的
default_params = SSDParams(img_shape=(300, 300),num_classes=21,no_annotation_label=21,feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],anchor_size_bounds=[0.15, 0.90],anchor_sizes=[(21., 45.),(45., 99.),(99., 153.),(153., 207.),(207., 261.),(261., 315.)],anchor_ratios=[[2, .5],[2, .5, 3, 1./3],[2, .5, 3, 1./3],[2, .5, 3, 1./3],[2, .5],[2, .5]],anchor_steps=[8, 16, 32, 64, 100, 300],anchor_offset=0.5,normalizations=[20, -1, -1, -1, -1, -1],prior_scaling=[0.1, 0.1, 0.2, 0.2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
其中这个anchor_sizes是最magic的一组数字,他到底是怎么来的呢?
首先你要知道这个公式:
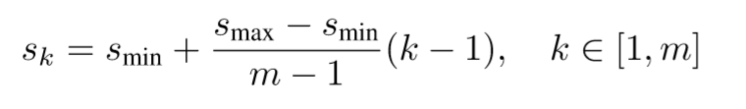
Sk是每个特征层的先验框大小与原图片大小之比,Smax和Smin分别是最大,最小的比例.
在SSD中一共有6个用于分类和回归的特征层(feature map),
分别是feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
m是就是特征层的个数,按理说分母应该是6-1=5,但是这里是5-1=4, 因为作者将第一层S1, 单独拿出来设置了.
k是第几个特征层的意思,注意k的范围是1~m, 也就是1~6.
知道这些就可以开始计算了.
Sk在实际计算中考虑到取整的问题,所有与上式有所区别:
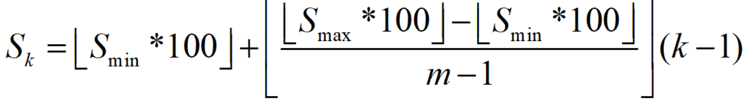
需要向下取整.
所以你将m=5, Smin, Smax=(0.2, 0.9) 就是anchor_size_bounds=[0.20, 0.90],带入之后,
得到S1~S6: 20, 37, 54, 71, 88, 105, 其实就是挨个+17.
此时你还需要将其除以100还原回来,也就是:
0.2, 0.37, 0.54, 0.71, 0.88, 1.05
然后,我们这个是比例, 我们需要得到其在原图上的尺寸,所以需要依次乘以300, 得到:
60, 111, 162, 213, 264, 315.
最后,你会问: 30呢? 这就要说到S1’了,S1’=0.5*S1, 就是0.1, 再乘以300, 就是30.
这样, 我们有七个数, 6个区间段, 也就是6组min_size和max_size. 就可以计算每个特征层的anchor_box 的尺寸了.详细见下片博文.
可以看出作者为了不让我们搞懂他的代码,也是煞费苦心啊…
最后, 既然我们高明白了anchor_size, 这个参数直接决定了当前特征层的box 的大小, 可以看出越靠近输入层, box越小, 越靠近输出层, box越大, 所以 SSD的底层用于检测小目标, 高层用于检测大目标.
二、SSD的anchor_box计算
看过SSD的tensorflow实现的小伙伴一定对anchor_box的计算很是好奇, 网上也是五花八门的解释,今天我结合源码和原理来解释一下.
default_params = SSDParams(img_shape=(300, 300),num_classes=21,no_annotation_label=21,feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],anchor_size_bounds=[0.15, 0.90],anchor_sizes=[(21., 45.),(45., 99.),(99., 153.),(153., 207.),(207., 261.),(261., 315.)],anchor_ratios=[[2, .5],[2, .5, 3, 1./3],[2, .5, 3, 1./3],[2, .5, 3, 1./3],[2, .5],[2, .5]],anchor_steps=[8, 16, 32, 64, 100, 300],anchor_offset=0.5,normalizations=[20, -1, -1, -1, -1, -1],prior_scaling=[0.1, 0.1, 0.2, 0.2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这个anchor_box的计算与anchor_sizes和anchor_ratios有关.
先解释一下anchor_box的由来. 我们假设当前层是block4, 那么我们的feat_shape就是(38, 38),
你可以将其理解为38*38个cell单元, 每个单元要预测出来几个anchor_box, 不同的层, 这个数理论上讲都是6个, (paper上就是这么写的). 每个box的长宽比是有ratios决定的, paper上是两个 1 , 以及4个其他的值. 但是作者的源码却很调皮的改了一下.
看一下我们的长宽比,这里面没有那两个1, 因为他们是单独设定的:
anchor_ratios=[[2, .5],[2, .5, 3, 1./3],[2, .5, 3, 1./3],[2, .5, 3, 1./3],[2, .5],[2, .5]],
我们看到第一层还有最后两层, 只有两种长宽比, 所以这三层就只有4种box.

这个图可以说介绍的相当准确定了, 网上有错的, 以这个为准 . 以block4层为例, 他每个cell单元只有4个box, 包括一大一小两个正方形, 以及两个长方形.
对于小正方形,其边长为min_size, 这个min_size是什么呢?就是前面参数中的anchor_sizes:
anchor_sizes=[(30., 60.),(60., 111.),(111., 162.),(162., 213.),(213., 264.),(264., 315.)],
其中每一行为一组, 每一行对应相应的特征层, 第一行对应的就是block4, 依次类推, 对于(30, 60), 30就是min_size, 60就是max_size.
大正方形其边长为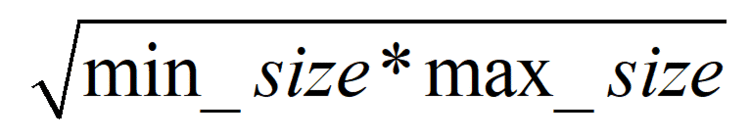
然后是另外两个长方形,这个时候anchor_ratios就出马了,长方形的长宽是有公式可寻的.
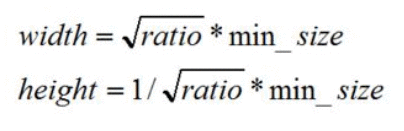
这个ratio就是anchor_ratios里的2, 5, 3, 1/3 之类的.
这样,原理上box的大小就介绍完了.但是别忘了这个尺寸是在原图上的尺寸, 我们需要这个尺寸相对于原图的比例.
看下源码的这一部分:
h[0] = sizes[0] / img_shape[0]w[0] = sizes[0] / img_shape[1]di = 1if len(sizes) > 1:h[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[0]w[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[1]+= 1 for i, r in enumerate(ratios):h[i+di] = sizes[0] / img_shape[0] / math.sqrt(r)w[i+di] = sizes[0] / img_shape[1] * math.sqrt(r)
最后, 既然我们高明白了anchor_size, 这个参数直接决定了当前特征层的box 的大小, 可以看出越靠近输入层, box越小, 越靠近输出层, box越大, 所以 SSD的底层用于检测小目标, 高层用于检测大目标.
三、SSD中feat_shapes与anchor_steps的对应问题
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)]
anchor_steps=[8, 16, 32, 64, 100, 300],
按理说anchor_step * feat_shape 应该全部等于300的呀, 可为什么不是呢? 这就涉及到向上取整的问题了.300/38 = 7.89 那就是8, 300/19 = 15.789 那就是16, 以此类推. 这个问题就明白了.
转博客: https://blog.csdn.net/qq_36735489/article/details/83654900,如有需要请从原文出处转载;









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有