1.列和表别名SQL别名用于为表或表中的列提供临时名称。SQL别名通常用于使表名或列名更具可读性。SQL一个别名只存在于查询期间。别名使用AS关键字,通常可以省略
1.列和表别名
SQL 别名用于为 表 或 表中的列 提供临时名称。 SQL 别名通常用于使 表名 或 列名 更具可读性。 SQL 一个别名只存在于查询期间。
别名使用 AS 关键字,通常可以省略。
建议在下列情况下使用别名 查询涉及多个表 用于查询函数 需要把两个或更多的列放在一起 列名长或可读性差
SELECT 列名
FROM 表名 AS 别名;
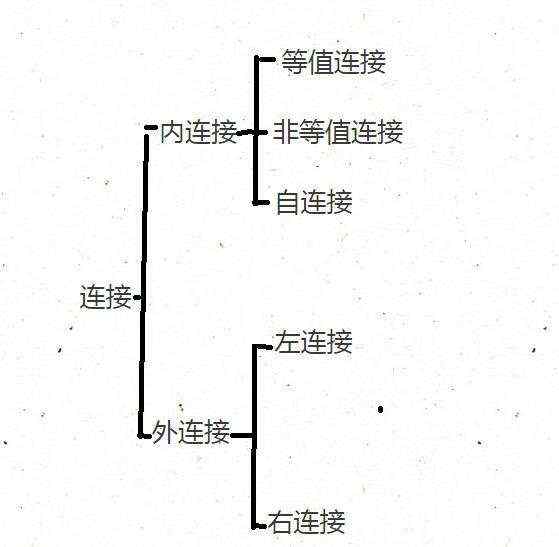
2. 连接表
在关系数据库中,数据分布在多个逻辑表中。
要获得完整有意义的数据集,需要使用连接来查询这些表 中的数据。
SQL Server支持多种连接,包括 [内连接],[左连接],[右连接],[全外连接]和[交叉连接]。 每种连接类型指定SQL Server如何使用一个表中的数据来选择另一个表中的行。
(1).SQL Server内连接
内连接是SQL Server中最常用的连接之一。 内部联接子句用于查询来自两个或多个相关表的数据。 SQL Server INNER JOIN 子句的语法:
SELECT
product_name,
category_name,
brand_name,
list_price
FROM
production.products p
INNER JOIN production.categories c ON c.category_id = p.category_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
ORDER BY
product_name DESC;
(2).SQL Server左连接
LEFT JOIN 子句用于查询来自多个表的数据。
它返回左表中的所有行和右表中的匹配行。 如果在右表中找不到匹配的行,则使用 NULL 代替显示。 以下图说明了两个结果集的左连接结果:
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
ORDER BY
order_id
(2).ON与WHERE子句
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id = 100
ORDER BY
order_id;
(3). SQL Server右连接
RIGHT JOIN 子句组合来自两个或多个表的数据。
RIGHT JOIN 开始从右表中选择数据并与左表中的行 匹配。
RIGHT JOIN 返回一个结果集,该结果集包含右表中的所有行,无论是否具有左表中的匹配行。
如果右表中的行没有来自右表的任何匹配行,则结果集中右表的列将使用 NULL 值。 以下是 RIGHT JOIN 的语法:
SELECT
product_name,
order_id
FROM
sales.order_items o
RIGHT JOIN production.products p
ON o.product_id = p.product_id
ORDER BY
order_id;
(4).SQL Server 交叉连接
CROSS JOIN 连接两个或多个不相关的表。 以下是两个表的SQL Server CROSS JOIN 的语法:
SELECT
select_list
FROM
T1
CROSS JOIN T2;
或者
SELECT
select_list
FROM
T1, T2;
CROSS JOIN 将第一个表(T1)中的每一行与第二个表(T2)中的每一行连接起来。
换句话说,交叉连接返回 两个表中行的笛卡尔积。
与INNER JOIN或LEFT JOIN不同,交叉连接不会在连接的表之间建立关系。
假设 T1 表包含三行: 1 , 2 和 3 , T2 表包含三行: A , B 和 C 。
CROSS JOIN 从第一个表(T1)获取一行,然后为第二个表(T2)中的每一行创建一个新行。
然后它对第一个 表(T1)中的下一行执行相同操作,依此类推。 在此图中, CROSS JOIN 总共创建了 9 行。 通常,如果第一个表有 n 行,第二个表有 m 行,则交叉连接 将产生 n x m 行。
(5).SQL Server自连接
自联接用于将表连接到自身(同一个表)。
它对于查询分层数据或比较同一个表中的行很有用。 自联接使用内连接或左连接子句。 由于使用自联接的查询引用同一个表,因此表别名用于为查询中的表 分配不同的名称。
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
sales.staffs e
INNER JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
manager
(6).SQL Server全外链接
FULL OUTER JOIN当左表或右表中存在匹配项时,该命令将返回所有行。 下面创建一些示例表来演示全外连接。 首先,创建一个名为 pm 的新模式,它代表项目管理
INSERT INTO
pm.projects(title)
VALUES
('New CRM for Project Sales'),
('ERP Implementation'),
('Develop Mobile Sales Platform');
INSERT INTO
pm.members(name, project_id)
VALUES
('John Doe', 1),
('Lily Bush', 1),
('Jane Doe', 2),
('Jack Daniel', null);
3.分组数据
(1).SQL Server Group By语句
Group By 从字面意义上理解就是根据“By”指定的规则对数据进行分组,
所谓的分组就是将一个“数据集” 划分成若干个“小区域”,
然后针 对若干个“小区域”进行数据处理。 以下是 GROUP BY 子句的语法:
SELECT
customer_id,
YEAR (order_date) order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
ORDER BY
customer_id;
(2).GROUP BY子句和聚合函数
GROUP BY 子句通常与聚合函数一起用于统计数据。
聚合函数对组执行计算并返回每个组的唯一值。
例如, COUNT() 函数返回每个组中的行数。
其他常用的聚合函数是: SUM() , AVG() , MIN() , MAX()。
GROUP BY 子句将行排列成组,聚合函数返回每个组的统计量(总数量,最小值,最大值,平均值,总和 等)。 例如,以下查询返回客户按年度下达的订单数:
SELECT
customer_id,
YEAR (order_date) order_year,
COUNT (order_id) 订单数量
FROM
sales.orders
WHERE
customer_id IN (1, 2)
GROUP BY
customer_id,
YEAR (order_date)
ORDER BY
customer_id;
(1).带有COUNT()函数示例的GROUP BY子句
SELECT
city,
COUNT (customer_id) customer_count
FROM
sales.customers
GROUP BY
city
ORDER BY
city;
(2).GROUP BY子句带有MIN和MAX函数示例
SELECT
brand_name,
MIN (list_price) min_price,
MAX (list_price) max_price
FROM
production.products p
INNER JOIN production.brands b ON b.brand_id = p.brand_id
WHERE
model_year = 2018
GROUP BY
brand_name
ORDER BY
brand_name;
4.SQL Server Having子句
HAVING 子句通常与[GROUP BY]子句一起使用,以根据指定的条件列表过滤分组。 以下是 HAVING 子句 的语法:
SELECT
select_list
FROM
table_name
GROUP BY
group_list
HAVING
conditions;
在此语法中,
GROUP BY 子句将行汇总为分组,
HAVING 子句将一个或多个条件应用于这些每个分组。
只有使条件评估为 TRUE 的组才会包含在结果中。
换句话说,过滤掉条件评估为 FALSE 或 UNKNOWN 的 组。
因为SQL Server在 GROUP BY 子句之后处理 HAVING 子句,所以不能通过使用列别名来引用选择列表中指 定的聚合函数。 以下查询将失败:
SELECT
column_name1,
column_name2,
aggregate_function (column_name3) column_alias
FROM
table_name
GROUP BY
column_name1,
column_name2
HAVING
column_alias > value
5.子查询
(1).SQL Server子查询
子查询是嵌套在另一个语句(如:[SELECT],[INSERT]
,[UPDATE]或[DELETE])中的查询。 以下语句显示如何在 SELECT 语句的[WHERE]子句中使用子查询来查找位于纽约( New York )的客户的销售订单:
SELECT
order_id,
order_date,
customer_id
FROM
sales.orders
WHERE
customer_id IN (
SELECT
customer_id
FROM
sales.customers
WHERE
city = 'New York'
)
ORDER BY
order_date DESC;
(2).SQL Server嵌套子查询
子查询可以嵌套在另一个子查询中。
SQL Server最多支持 32 个嵌套级别。 请考虑以下示例:
SELECT
product_name,
list_price
FROM
production.products
WHERE
list_price > (
SELECT
AVG (list_price)
FROM
production.products
WHERE
brand_id IN (
SELECT
brand_id
FROM
production.brands
WHERE
brand_name = '上海永久'
OR brand_name = '凤凰'
)
)
ORDER BY
list_price;
(3).SQL Server相关子查询
相关子查询是使用外部查询的值的[子查询]。
换句话说,它取决于外部查询的值。
由于这种依赖性,相 关子查询不能作为简单子查询独立执行。
此外,对外部查询评估的每一行重复执行一次相关子查询。 相关子查询也称为重复子查询。 以下示例查找价格等于其类别的最高价格的产品。
SELECT
product_name,
list_price,
category_id
FROM
production.products p1
WHERE
list_price IN (
SELECT
MAX (p2.list_price)
FROM
production.products p2
WHERE
p2.category_id = p1.category_id
GROUP BY
p2.category_id
)
ORDER BY
category_id,
product_name;
-- 子查询写法
SELECT
p1.product_id,p1.product_name,p1.category_id,p1.list_price
FROM
production.products p1
INNER JOIN (
SELECT
category_id,
max(list_price) max_price
FROM
production.products
GROUP BY
category_id
) p2 ON p1.category_id = p2.category_id
AND p1.list_price = p2.max_price;
(4).SQL Server Exists运算符
EXISTS 运算符是一个逻辑运算符,用于检查子查询是否返回任何行。 如果子查询返回一行或多行,则 EXISTS 运算符返回 TRUE 。 以下是SQL Server EXISTS 运算符的语法:
EXISTS ( subquery)
(1).1. 带子查询的EXISTS返回NULL示例 以下示例返回 customers 表中的所有行:
SELECT
customer_id,
first_name,
last_name
FROM
sales.customers
WHERE
EXISTS (SELECT NULL)
ORDER BY
first_name,
last_name;
(5).SQL Server Any运算符
ANY 运算符是一个逻辑运算符,它将标量值与子查询返回的单列值集进行比较。 以下是 ANY 运算符的语法:
scalar_expression comparison_operator ANY (subquery)
在上面语法中,
scalar_expression - 是任何有效的表达式。
comparison_operator - 是任何比较运算符,包括等于( &#61; )&#xff0c;不等于( <> )&#xff0c;大于( > )&#xff0c;大于或等于 ( >&#61; )&#xff0c;小于( <)&#xff0c;小于或等于( <&#61; )。
subquery 是一个[SELECT]语句&#xff0c;它返回单个列的结果集&#xff0c;其数据与标量表达式的数据类型相同。
SELECT
product_name,
list_price
FROM
production.products
WHERE
product_id &#61; ANY (
SELECT
product_id
FROM
sales.order_items
WHERE
quantity >&#61; 2
)
ORDER BY
product_name;
(7).SQL Server All运算符
SQL Server ALL 运算符是一个逻辑运算符&#xff0c;
它将标量值与子查询返回的单列值列表进行比较。 以下是 ALL 运算符语法&#xff1a;
scalar_expression comparison_operator ALL ( subquery)
在上面语法中&#xff0c; scalar_expression 是任何有效的表达式。
comparison_operator 是任何有效的比较运算符&#xff0c;包括等于( &#61; )&#xff0c;不等于( <> )&#xff0c;大于( > )&#xff0c;大于或 等于( >&#61; )&#xff0c;小于( <)&#xff0c;小于或等于( ALL ( subquery ) 如果 scalar_expression 大于子查询返回的最大值&#xff0c;则表达式返回 TRUE 。
例如&#xff0c;以下查询查找价格大于所有品牌产品的平均价格的产品&#xff1a;
SELECT
product_name,
list_price
FROM
production.products
WHERE
list_price > ALL (
SELECT
AVG (list_price) avg_list_price
FROM
production.products
GROUP BY
brand_id
)
ORDER BY
list_price;
(2).scalar_expression 如果标量表达式( scalar_expression )小于子查询( subquery )返回的最小值&#xff0c;则表达式求值为 TRUE 。 以下示例按品牌查找价格低于平均价格中最低价格的产品&#xff1a;
SELECT
product_name,
list_price
FROM
production.products
WHERE
list_price SELECT
AVG (list_price) avg_list_price
FROM
production.products
GROUP BY
brand_id
)
ORDER BY
list_price DESC;



 京公网安备 11010802041100号
京公网安备 11010802041100号