通常,在内核模式下,使用fio工具来测试设备在实际的工作负载下所能承受的最大压力。用户可以启动多个线程,对设备来模拟各种IO操作,使用filename指定所被测试的设备。然而,在SPDK用户态模式情况下,SPDK在使用前会unbind内核驱动,直接通过PCI地址来识别设备,因此用户在系统上无法直接看到设备。为此,SPDK推出fio_plugin与SPDK深度集成,用户可以通过指定设备的PCI地址,来决定所要进行压力测试的设备。同时,在fio_plugin内部,采用SPDK用户态设备驱动所提供的轮询和异步的方式进行I/O操作,I/O通过SPDK直接写入磁盘。
SPDK提供两种形态的fio_plugin:
在编译时,fio_plugin要依赖于一些原本fio所提供的库文件,因此在编译SPDK前,要首先编译fio,并且在运行SPDK configure脚本时,要指定fio源码的路径,否则fio_plugin默认是不会编译的。例如
./configure --with-fio=/path/to/fio/repo
下面我们来介绍fio_plugin的使用方法。
1. 基于裸盘的fio_plugin
在使用fio_plugin的时候,基本的命令与参数和fio的相同。只有以下两点需要变化:
[Global]
ioengine=spdk
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
ramp_time=0
runtime=1800
iodepth=128
rw=randread
bs=4k
[test]
numjobs=1
filename=key=value [key=value] ... ns=value
fio_plugin提供了两种模式的设备类型,如下:
a. NVMe over PCIe :测试的时候,指定PCI地址,以及namespace,例如:
fio config.fio ‘-- filename=trtype=PCIe traddr=0000.06.00.0 ns=1’
b. NVMe over Fabrics:测试的时候,指定IP地址、类型以及namespace,例如:
fio config.fio ‘-- filename=trtype=RDMA adrfam=IPv4 traddr=192.168.100.8 trsvcid=4420 ns=1
2. 基于bdev的fio_plugin
在使用基于bdev的fio_plugin时,SPDK会通过配置文件,在特定的设备上初始化bdev。因此启动时,需要指定SPDK应用程序配置文件(与SPDK NVMe-oF、SPDK vhost启动时候所指定的配置文件基本相同),同时在测试时,测试设备应设定为相应的bdev名称。所以,与fio相比,在使用上的差别可以总结为以下两点:
注意事项:
1. fio_plugin限制只能使用线程模式,因此在fio配置参数中,需要制定thread = 1。
2. 当测试random模式的read/write时候,因为在random map的时候,要额外耗费很多的CPU cycle,从而降低性能。因此在测试randread/randwrite的时候,建议指定norandommap=1。
SPDK提供自己的性能测试工具perf。SPDK的perf与通常Linux系统中的perf工具有所不同,SPDK中的perf主要是用于对设备做压力测试,来评估其性能的工具。perf相比于fio_plugin更加灵活,可以直接配置core mask来指定进行I/O操作的CPU核。SPDK通过使用CPU的亲和性,将线程和CPU核做绑定,每个线程对应一个CPU核。在启动perf时,可以通过core mask指定所用的CPU核,在所指定的每个CPU核上,都会为之注册一个worker_thread进行I/O操作。每个worker_thread都会调用SPDK所提供的I/O操作接口,通过异步的方式向底层的裸盘发送读写命令。
perf的使用方法如下所示:
下面给出一个perf的使用范例:
./perf -q 32 -s 4096 -w randwrite -t 1200 -c 0xF -r 'trtype:PCIe traddr:0000:06:00.0'
在这里,core mask为0xF,代表我们使用核1,2,3,4来创建4个worker_thread对PCI地址为0000:06:00.0的盘进行随机写操作,其中-q 表示queue depth, -s 代表block size, -t 代表time。

相比于fio_plugin,perf有以下优势:
1. 可以通过core mask灵活指定CPU核。
2. 如果使用单个线程来测试多块盘性能的时候,fio_plugin的所得到的性能与perf所的到的性能有很大的差距。这是由于fio软件架构的问题,所以不适用于单个线程来操作多块盘。因此在评估单个线程(单核)的能力的时候,一般选用perf作为测试工具。若为多个线程对应操作多块盘,则无需顾虑。在这种情况下,fio_plugin与perf结果无差异。
1通过使用fio和perf对SPDK性能评估,得到的结果不同,大部分的时候perf所得到的性能会比fio所得到的性能要高。
两种工具最大的差别在于,fio是通过与Linux fio工具进行集成,使其可以用来测试SPDK的设备,而由于fio本身架构的问题,不能充分发挥SPDK的优势,例如fio使用Linux的线程模型,在使用的时候,线程仍会被内核调度。而对于perf来说,是针对SPDK定制的性能测试工具,因此在底层,不仅是I/O操作会通过SPDK进行下发,同时一些底层架构都是为SPDK所设计的。例如刚刚所提到的线程模型,perf中是使用DPDK所提供的线程模型,通过使用CPU的亲和性将CPU核与线程捆绑,不再受内核调度,因此可以充分发挥SPDK下发I/O时的异步无锁化的优势。这就是为什么perf所测得的性能要比fio的高,因此,在同等情况下,我们更推荐用户使用perf工具对SPDK进行性能评估。
2对SPDK和内核的性能评估时,虽然性能有所提升,但是没有看到SPDK官方所展示的特别大的性能差异。
首先,如问题1中所述,不同的工具之间得出的性能结果是不同的,另外最主要的因素还是硬盘本身性能瓶颈所导致的问题。例如,使用2D NAND的P3700,本身的性能存在一定的瓶颈,因此无论是SPDK驱动还是内核驱动,都会达到较高的IOPS。
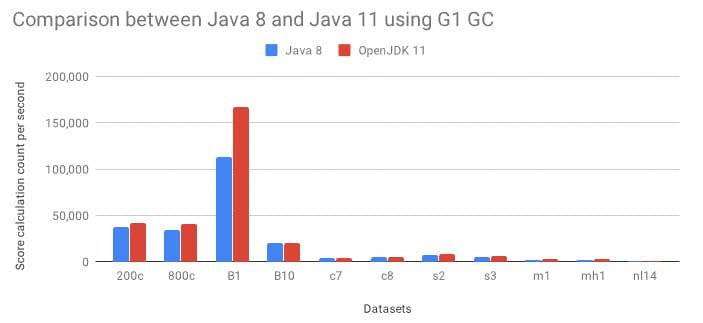
如果我们换用更高性能的硬盘,例如使用3DXpoint的Optane(P4800X),便会发现很大的性能差异。因此,硬盘性能越高,SPDK所发挥出的优势越明显,这也是SPDK产生的初衷,本身就是为高性能硬盘所订制的。我们用下面这幅图来说明问题:

图1 P4800X Random Read SPDK vs. Kernel
图1采用了基于裸盘的fio_plugin,使用单个CPU核,对单盘测试random read的结果。我们可以清楚地看到,用P4800X来测试的时候,无论qd增加多少,Kernel所能到的性能都是在300K+的IOPS。已经达到Kernel的最大能力,而SPDK可以轻松达到接近500k的IOPS。
此外,我们再普及两点额外的知识:
对于评估以2D NAND、3D NAND介质的硬盘,例如P3700、P4500,一般情况下,为了达到磁盘的最高性能,通常会选择较高的qd(queue depth),通常qd=128即可,已经达到SPDK发I/O的最高效率。如果在128之上再增加qd,通常IOPS不会再有所增加,反而会增加单个I/O的latency。因此推荐使用qd=128。但对于新介质3DXpoint的硬盘,通常qd为8的时候,就已经可以达到一个最高值,因此若测试Optane(P4800X)的性能,通常推荐使用qd=8,而不是128。
通常以2D NAND、3D NAND为介质的磁盘,在测试write的性能时,会有一些不稳定且虚高的现象,常见为测到的IOPS结果远远大于specification里的最高值,这是由于磁盘介质本身的问题。因此在测试此类磁盘时,为了避免上述现象,通常会在测试之前做precondition。通常做法为:在格式化之后,对磁盘不断进行写操作写满整个磁盘,使写入进入稳态。以P3700 800GB为例,通常我们会先顺序写两小时(4k),之后再随机写一小时(4k)。








 京公网安备 11010802041100号
京公网安备 11010802041100号