2021SC@SDUSC
目录
一、前情回顾
1.PP-OCR文字识别策略
2.本文策略——学习率衰减的简单介绍
学习率衰减介绍
学习率衰减的常见参数
几种固定学习率衰减策略介绍
学习率衰减的warm-up策略
Paddle OCR所涉及的学习率衰减策略
二、学习率衰减策略与代码分析
1.PP-OCR的学习率衰减策略
2.代码分析
总结
策略的选用主要是用来增强模型能力和减少模型大小。下面是PP-OCR文字识别器所采用的九种策略:
深层神经网络的参数学习主要是通过梯度下降方法来寻找一组可以最小化结构风险的参数。 在梯度下降中学习率的取值非常关键,如果过大可能不会收敛,过小则收敛速度太慢。
通常的策略在一开始采用大的学习率保证收敛,在收敛到最优点附近时要小些以避免来回震荡。因此,比较简单直接的学习率调整可以通过学习率衰减(Learning Rate Decay)的方式来实现。
学习率衰减策略可以分为两种:固定策略的学习率衰减和自适应学习率衰减,其中固定学习率衰减包括分段衰减、逆时衰减、指数衰减等,自适应学习率衰减包括AdaGrad、 RMSprop、 AdaDelta等。一般情况,两种策略会结合使用。
| 参数名称 | 参数说明 |
| learning_rate | 初始学习率 |
| global_step | 用于衰减计算的全局步数,非负,用于逐步计算衰减指数 |
| decay_steps | 衰减步数,必须是正值,决定衰减周期 |
| decay_rate | 衰减率 |
| end_learning_rate | 最低的最终学习率 |
| cycle | 学习率下降后是否重新上升 |
| alpha | 最小学习率 |
| num_periods | 衰减余弦部分的周期数 |
| initial_variance | 噪声的初始方差 |
| variance_decay | 衰减噪声的方差 |
| boundaries | 学习率衰减边界 |
| values | 不同阶段对应学习率 |
| staircase | 是否以离散的时间间隔衰减学习率 |
| power | 多项式的幂 |
基本学习率衰减
piecewise decay 分段常数衰减, 在训练过程中不同阶段设置不同的学习率,便于更精细的调参。在目标检测任务如Faster RCNN 和 SSD 的训练中都采用分段常数衰减策略,调整学习率。策略效果如下:
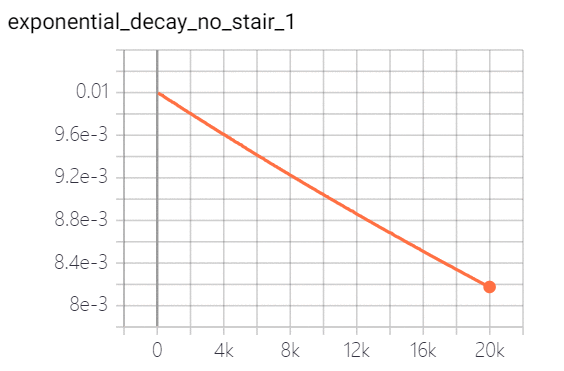
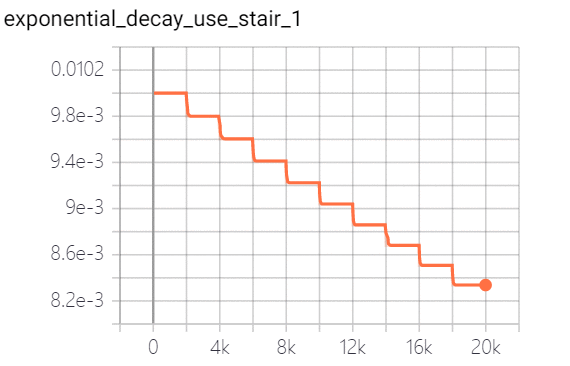
exponential decay 指数衰减:学习率以指数的形式进行衰减,其中指数函数的底为decay_rate, 指数为 global_step / decay_steps。策略效果如下(图一为连续,图二为离散):
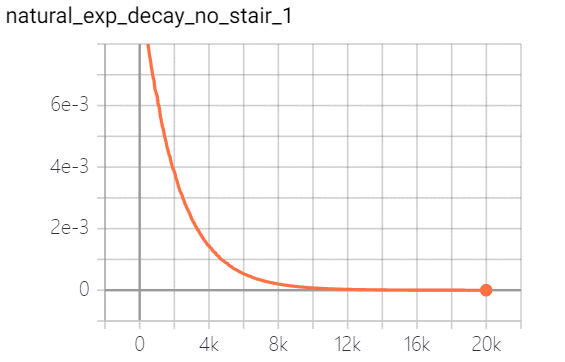
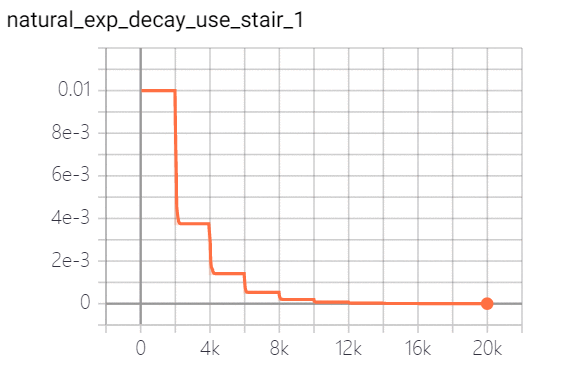
natural exponential decay 自然指数衰减:学习率以自然指数进行衰减,其中指数函数底为自然常数e, 指数为-decay_rate * global_step / decay_step, 相比指数衰减具有更快的衰减速度。策略实现效果如下(图一为连续,图二为离散):
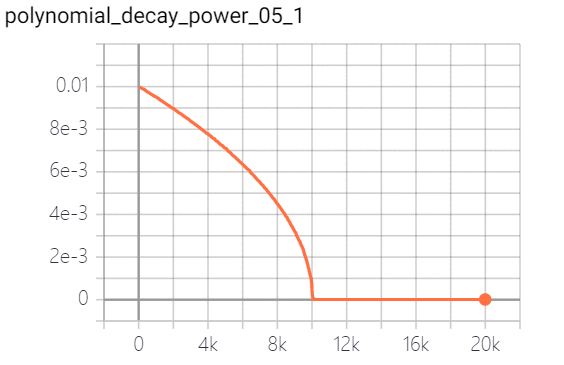
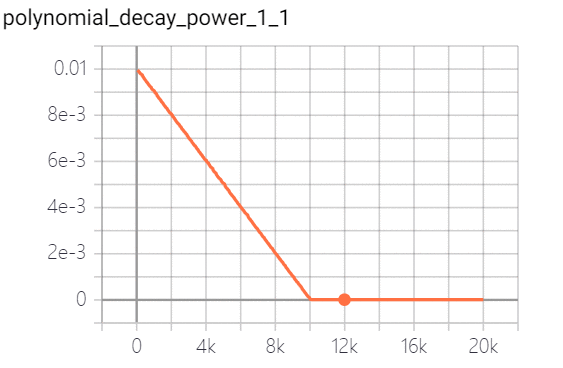
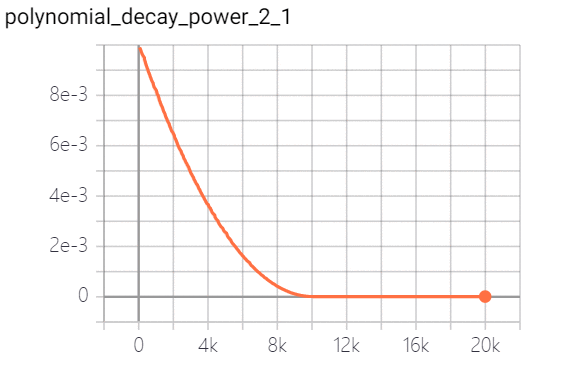
polynomial decay 多项式衰减:调整学习率的衰减轨迹以多项式对应的轨迹进行。其中(1 - global_step / decay_steps) 为幂函数的底; power为指数,控制衰减的轨迹。策略效果实现如下(幂指数分别为0.5、1.0、2.0):
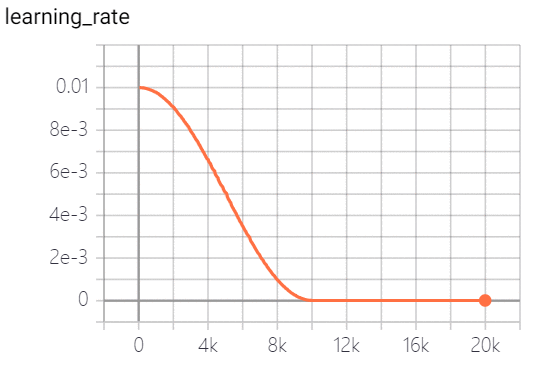
cosine decay 余弦衰减:学习率以cosine 函数曲线进行进行衰减, 其中余弦函数的周期为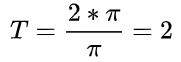 , 自变量为
, 自变量为 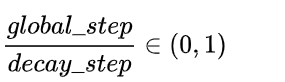
策略效果如下:
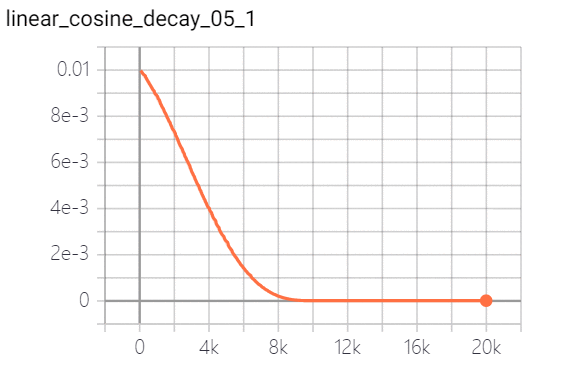
linear cosine decay 线性余弦衰减:动机式在开始的几个周期,执行warm up 操作,线性余弦衰减比余弦衰减更具aggressive,通常可以使用更大的初始学习速率。其中余弦函数的周期为 ,自变量为
,自变量为 。实现效果如下:
。实现效果如下:
它可以分为两个阶段:第一个阶段,学习率从很小的学习率(warm-up learning rate)增加到基学习率(base learning rate),这一阶段也称为warm-up阶段。第二阶段,从基学习开始,执行学习率衰减。
warm-up 动机如下:
对于第一阶段,由于刚开始训练时,模型的权重(weights)是随机初始化的,这时模型对于数据的“分布”理解为零,在初始训练阶段, 每个输入数据对模型来说都是新的, 模型会根据数据对模型权重进行修正。此时若选择一个较大的学习率,如果这时候学习率就很大,极有可能导致模型对开始的数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段(几个epoch)后,模型已经对数据集分布有一定了解,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型跑偏,所以可以适当调大学习率。这个过程就可以看做是warm-up。
对于第二阶段,当模型一定阶段(如十几个epoch)后,模型的分布就已经比较固定了,模型慢慢趋于稳定。这时再执行学习率衰减, 可以使得模型获得更快的收敛速度。warm-up 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳。
带有warm-up的线性学习率衰减——Linear learning rate decay。
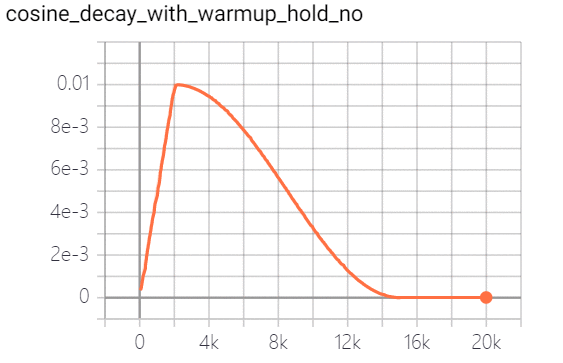
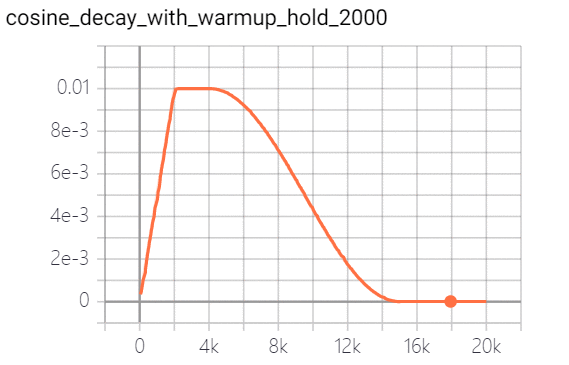
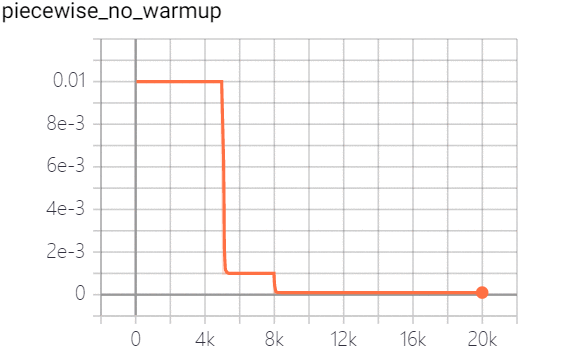
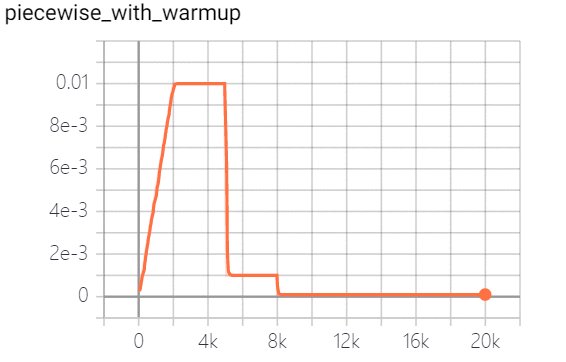
学习率是控制学习速度的超参数。学习率越低,损失值变化越慢。虽然使用较低的学习率可以确保不会错过任何局部最小值,但这也意味着收敛速度较慢。在训练的早期,权值处于随机初始化状态,因此我们可以设置较大的学习率,以更快地收敛。在训练的后期,由于权值接近最优值,所以应该使用较小的学习率。余弦学习速率衰减已成为首选的提高模型精度的学习速率降低策略。在整个训练过程中,余弦学习速率衰减保持较大的学习速率,因此其收敛速度较慢,但最终收敛精度较好。下图是不同的学习速率衰减方式的比较:

代码位置:


主要代码段:
lr_scheduler.py 循环余弦学习率衰减
class CyclicalCosineDecay(LRScheduler):def __init__(self,learning_rate,T_max,cycle=1,last_epoch=-1,eta_min=0.0,verbose=False):"""Cyclical cosine learning rate decay 周期余弦学习率衰减A learning rate which can be referred in https://arxiv.org/pdf/2012.12645.pdfArgs:learning rate(float): learning rateT_max(int): maximum epoch numcycle(int): period of the cosine decaylast_epoch (int, optional): The index of last epoch. Can be set to restart training. Default: -1, means initial learning rate.eta_min(float): minimum learning rate during trainingverbose(bool): whether to print learning rate for each epoch"""super(CyclicalCosineDecay, self).__init__(learning_rate, last_epoch,verbose)self.cycle = cycleself.eta_min = eta_mindef get_lr(self):if self.last_epoch == 0:return self.base_lrreletive_epoch = self.last_epoch % self.cyclelr = self.eta_min + 0.5 * (self.base_lr - self.eta_min) * \(1 + math.cos(math.pi * reletive_epoch / self.cycle))return lr
learning_rate.py 其他学习率衰减
class Linear(object):"""Linear learning rate decay 线性学习率衰减Args:lr (float): The initial learning rate. It is a python float number.epochs(int): The decay step size. It determines the decay cycle.end_lr(float, optional): The minimum final learning rate. Default: 0.0001.power(float, optional): Power of polynomial. Default: 1.0.last_epoch (int, optional): The index of last epoch. Can be set to restart training. Default: -1, means initial learning rate."""def __init__(self,learning_rate,epochs,step_each_epoch,end_lr=0.0,power=1.0,warmup_epoch=0,last_epoch=-1,**kwargs):super(Linear, self).__init__()self.learning_rate = learning_rateself.epochs = epochs * step_each_epochself.end_lr = end_lrself.power = powerself.last_epoch = last_epochself.warmup_epoch = round(warmup_epoch * step_each_epoch)def __call__(self):learning_rate = lr.PolynomialDecay(learning_rate=self.learning_rate,decay_steps=self.epochs,end_lr=self.end_lr,power=self.power,last_epoch=self.last_epoch)if self.warmup_epoch > 0:learning_rate = lr.LinearWarmup(learning_rate=learning_rate,warmup_steps=self.warmup_epoch,start_lr=0.0,end_lr=self.learning_rate,last_epoch=self.last_epoch)return learning_rateclass Cosine(object):"""Cosine learning rate decay 余弦学习率衰减lr = 0.05 * (math.cos(epoch * (math.pi / epochs)) + 1)Args:lr(float): initial learning ratestep_each_epoch(int): steps each epochepochs(int): total training epochslast_epoch (int, optional): The index of last epoch. Can be set to restart training. Default: -1, means initial learning rate."""def __init__(self,learning_rate,step_each_epoch,epochs,warmup_epoch=0,last_epoch=-1,**kwargs):super(Cosine, self).__init__()self.learning_rate = learning_rateself.T_max = step_each_epoch * epochsself.last_epoch = last_epochself.warmup_epoch = round(warmup_epoch * step_each_epoch)def __call__(self):learning_rate = lr.CosineAnnealingDecay(learning_rate=self.learning_rate,T_max=self.T_max,last_epoch=self.last_epoch)if self.warmup_epoch > 0:learning_rate = lr.LinearWarmup(learning_rate=learning_rate,warmup_steps=self.warmup_epoch,start_lr=0.0,end_lr=self.learning_rate,last_epoch=self.last_epoch)return learning_rateclass Step(object):"""Piecewise learning rate decay 分段学习率衰减的分段Args:step_each_epoch(int): steps each epochlearning_rate (float): The initial learning rate. It is a python float number.step_size (int): the interval to update.gamma (float, optional): The Ratio that the learning rate will be reduced. ``new_lr = origin_lr * gamma`` .It should be less than 1.0. Default: 0.1.last_epoch (int, optional): The index of last epoch. Can be set to restart training. Default: -1, means initial learning rate."""def __init__(self,learning_rate,step_size,step_each_epoch,gamma,warmup_epoch=0,last_epoch=-1,**kwargs):super(Step, self).__init__()self.step_size = step_each_epoch * step_sizeself.learning_rate = learning_rateself.gamma = gammaself.last_epoch = last_epochself.warmup_epoch = round(warmup_epoch * step_each_epoch)def __call__(self):learning_rate = lr.StepDecay(learning_rate=self.learning_rate,step_size=self.step_size,gamma=self.gamma,last_epoch=self.last_epoch)if self.warmup_epoch > 0:learning_rate = lr.LinearWarmup(learning_rate=learning_rate,warmup_steps=self.warmup_epoch,start_lr=0.0,end_lr=self.learning_rate,last_epoch=self.last_epoch)return learning_rateclass Piecewise(object):"""Piecewise learning rate decay 分段学习率衰减Args:boundaries(list): A list of steps numbers. The type of element in the list is python int.values(list): A list of learning rate values that will be picked during different epoch boundaries.The type of element in the list is python float.last_epoch (int, optional): The index of last epoch. Can be set to restart training. Default: -1, means initial learning rate."""def __init__(self,step_each_epoch,decay_epochs,values,warmup_epoch=0,last_epoch=-1,**kwargs):super(Piecewise, self).__init__()self.boundaries = [step_each_epoch * e for e in decay_epochs]self.values = valuesself.last_epoch = last_epochself.warmup_epoch = round(warmup_epoch * step_each_epoch)def __call__(self):learning_rate = lr.PiecewiseDecay(boundaries=self.boundaries,values=self.values,last_epoch=self.last_epoch)if self.warmup_epoch > 0:learning_rate = lr.LinearWarmup(learning_rate=learning_rate,warmup_steps=self.warmup_epoch,start_lr=0.0,end_lr=self.values[0],last_epoch=self.last_epoch)return learning_rateclass CyclicalCosine(object):"""Cyclical cosine learning rate decay 循环余弦学习率衰减Args:learning_rate(float): initial learning ratestep_each_epoch(int): steps each epochepochs(int): total training epochscycle(int): period of the cosine learning ratelast_epoch (int, optional): The index of last epoch. Can be set to restart training. Default: -1, means initial learning rate."""def __init__(self,learning_rate,step_each_epoch,epochs,cycle,warmup_epoch=0,last_epoch=-1,**kwargs):super(CyclicalCosine, self).__init__()self.learning_rate = learning_rateself.T_max = step_each_epoch * epochsself.last_epoch = last_epochself.warmup_epoch = round(warmup_epoch * step_each_epoch)self.cycle = round(cycle * step_each_epoch)def __call__(self):learning_rate = CyclicalCosineDecay(learning_rate=self.learning_rate,T_max=self.T_max,cycle=self.cycle,last_epoch=self.last_epoch)if self.warmup_epoch > 0:learning_rate = lr.LinearWarmup(learning_rate=learning_rate,warmup_steps=self.warmup_epoch,start_lr=0.0,end_lr=self.learning_rate,last_epoch=self.last_epoch)return learning_rate
以上是今天PP-OCR文字识别模型的学习率衰减策略的相关介绍。之后将会继续介绍PP-OCR文字识别模型的其他策略。





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 