作者:Huiying_Liu | 来源:互联网 | 2023-05-19 09:00
目录
- GIL
- 什么是GIL锁
- 为什么需要加锁
- 带来的问题
- 如何解决
- 关于性能的讨论
- 计算密集型任务:进程执行更快
- IO密集型:线程执行更快
- 自定义锁与GIL的区别
GIL
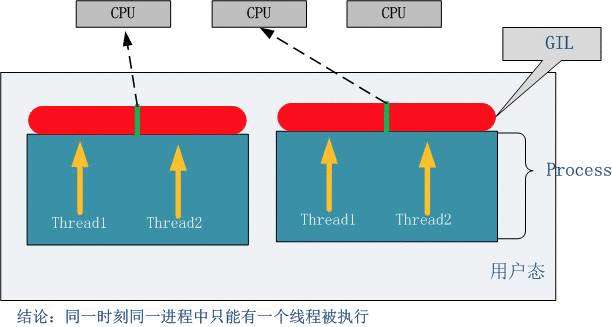
什么是GIL锁
官方解释:
'''
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
释义:
在CPython中,这个全局解释器锁,也称为GIL,是一个互斥锁,防止多个线程在同一时间执行Python字节码,这个锁是非常重要的,因为CPython的内存管理非线程安全的,很多其他的特性依赖于GIL,所以即使它影响了程序效率也无法将其直接去除
总结:
在CPython中,GIL会把线程的并行变成串行,导致效率降低
为什么需要加锁
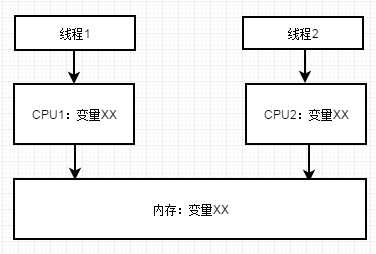
# 线程安全问题具体的表现
# cpython解释器与python程序之间的关系?
python程序本质就是一堆字符串,所有运行一个python程序时,必须要开启一个解释器
但是在一个python程序中解释器只有一个,所有代码都要交给他来解释执行
当有多个线程都要执行代码时,就会产生线程安全问题。
那我们不开启子线程是不是就没有问题了?
答案是:不是。
# Cpython解释器与GC问题
python会自动帮我们处理垃圾,清扫垃圾也是一对代码,也需要开启一个线程来执行
也就是说计算程序没有自己开启线程,内部也有多个线程
GC线程与我们程序中的线程就会产生安全问题
例如:
线程a要定义一个变量
步骤:先申请一块空的内存,在吧数据装进去,最后将引用计数加1
如果在进行到第二部的时候,CPU切换到Gc线程,GC就会把这个值当成垃圾,清理掉
总结:为了解决线程安全问题
带来的问题
GIL是一把互斥锁,互斥锁将导致效率低
具体表现是Cpython中,即便开启了多线程,而且CPU也是多核的,却无法并行执行任务。
因为解释器只有一个,同一时间只能有一个任务在执行
如何解决
没办法解决,只能尽可能的避免GIL锁影响我们的效率
1. 使用多进程能够实现并行,从而更好的利用多核CPU
2. 对任务进行区分
任务可以分为两类
1. 计算密集型,基本没有IO 大部分时间都在计算,例如人脸识别,图像处理
由于多线程不能并行,应该使用多进程,将任务分给不同CPU核心
2. IO密集型,计算任务非常少,大部分时间都在等待IO操作
由于网络IO速度对比CPU处理速度非常慢,多线程并不会造成太大的影响
对于网络IO密集型,因为有大量客户端连接服务,进程根本开不起来,只能多线程
关于性能的讨论
之所以加锁是为了解决线程安全问题
由于有了锁,导致了Cpython中多线程不能并行,只能并发
但是我们不能因此否认python
1. python是一门语言,GIL是Cpython解释器的问题,还有Jpython,pypy
2. 如果是单核CPU GIL不会造成任何影响
3. 由于目前大多数程序都是基于网络的,网络速度对比CPU非常慢,导致即使多核CPU也无法提高效率
4. 对于IO密集型任务,不会有太大的影响
5. 如果没有这把锁,我们程序猿必须自己来解决安全问题
计算密集型任务:进程执行更快
线程:
from multiprocessing import Process
from threading import Thread
import time
# 计算密集型任务
def task():
for i in range(100000000):
1+1
# 进程
if __name__ == '__main__':
strat_time = time.time()
a_list = []
for i in range(5):
# p = Process(target=task)
p = Thread(target=task)
p.start()
a_list.append(p)
for i in a_list:
i.join()
print("共耗时:%s"%(time.time()- strat_time))
共耗时:13.50247573852539
进程:
from multiprocessing import Process
from threading import Thread
import time
# 计算密集型任务
def task():
for i in range(100000000):
1+1
# 进程
if __name__ == '__main__':
strat_time = time.time()
a_list = []
for i in range(5):
p = Process(target=task)
# p = Thread(target=task)
p.start()
a_list.append(p)
for i in a_list:
i.join()
print("共耗时:%s"%(time.time()- strat_time))
共耗时:4.888190746307373
IO密集型:线程执行更快
线程:
from multiprocessing import Process
from threading import Thread
import time
# 计算密集型任务
def task():
for i in range(50):
with open('client_one.py','r',encoding="utf-8")as fr:
fr.read()
# 进程
if __name__ == '__main__':
strat_time = time.time()
a_list = []
for i in range(5):
# p = Process(target=task)
p = Thread(target=task)
p.start()
a_list.append(p)
for i in a_list:
i.join()
print("共耗时:%s"%(time.time()- strat_time))
共耗时:0.019989967346191406
进程:
from multiprocessing import Process
from threading import Thread
import time
# 计算密集型任务
def task():
for i in range(50):
with open('client_one.py','r',encoding="utf-8")as fr:
fr.read()
# 进程
if __name__ == '__main__':
strat_time = time.time()
a_list = []
for i in range(5):
p = Process(target=task)
# p = Thread(target=task)
p.start()
a_list.append(p)
for i in a_list:
i.join()
print("共耗时:%s"%(time.time()- strat_time))
共耗时:0.33380866050720215
自定义锁与GIL的区别
GIL锁住的是解释器级别的数据,比如对象的引用计数,垃圾分代数据等等,具体参考垃圾回收机制详解
自定义锁的是解释器以外的共享资源,例如:硬盘上的文件,控制台
对于程序中自己定义的数据则没有任何的保护效果,这一点在没有介绍GIL前我们就已经知道了,所以当程序中出现了共享自定义的数据时就要自己加锁,如下例:
from threading import Thread,Lock
import time
a = 0
def task():
global a
temp = a
time.sleep(0.01)
a = temp + 1
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
过程分析:
- 线程1获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL
- 线程2获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL
- 线程1睡醒后获得CPU执行权,并获取GIL执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU并释放GIL
- 线程2睡醒后获得CPU执行权,并获取GIL执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU并释放GIL,最后a的值也就是1
之所以出现问题是因为两个线程在并发的执行同一段代码,解决方案就是加锁
from threading import Thread,Lock
import time
lock = Lock()
a = 0
def task():
global a
lock.acquire()
temp = a
time.sleep(0.01)
a = temp + 1
lock.release()
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
过程分析:
- 线程1获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL,不释放lock
- 线程2获得CPU执行权,并获取GIL锁,尝试获取lock失败,无法执行,释放CPU并释放GIL
- 线程1睡醒后获得CPU执行权,并获取GIL继续执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU释放GIL,释放lock,此时a的值为1
- 线程2获得CPU执行权,获取GIL锁,尝试获取lock成功,执行代码,得到a的值为1后进入睡眠,释放CPU并释放GIL,不释放lock
- 线程2睡醒后获得CPU执行权,获取GIL继续执行代码 ,将temp的值1+1后赋给a,执行完毕释放CPU释放GIL,释放lock,此时a的值为2




 京公网安备 11010802041100号
京公网安备 11010802041100号