作者:Sayak Paul
编译:Bot
设想这么一种情况:
你构建了一个非常好的机器学习模型,比方说它可以预测某种交易中是否存在欺诈嫌疑。现在,你的一个朋友正在为某家银行开发Android APP,他希望能把你的模型集成到他们的产品里,因为你的模型太实用了,性能也格外出色。
但是,那个Android APP是用JAVA写的,你的模型是用Python写的。怎么办?难道你还要花时间花精力用JAVA重新写一个?
这时候,你就需要一种秘密武器——API。在实践中,上述情况是把机器学习模型转换成API的常见需求之一,这一点非常重要,因为现在各行各业都在寻找可以把技术用于生产、经营的数据科学家。本文将介绍创建API的具体操作,具体来说,它主要涵盖以下内容:
简单来说,一个API其实就是两个软件之间的(假定)契约,如果面向终端用户的软件能以预定义的格式提供输入,另一个软件就能扩展其功能,并向面向终端用户的软件提供输出结果。——Analytics Vidhya
从本质上讲,API非常类似Web应用程序,但前者往往以标准数据交换格式返回数据(如JSON、XML等)。一旦开发人员拿到了所需的输出,他们就能按照各种需求对它进行设计。现在有很多流行的机器学习API,比如IBM Watson就有以下功能:
Google Vision API也是一个很好的例子,它主要面向计算机视觉任务。
基本上,大多数云服务提供商都会提供一系列大型、综合性的API,而以小规模机器学习为重点的企业则提供即用型API。它们都满足了那些没有太多机器学习专业知识背景的开发人员/企业的需求,方便他们在流程和产品套件中部署机器学习技术。
在Web开发中,一些比较流行的机器学习API有DialogFlow、Microsoft的Cognitive Toolkit、TensorFlow.js等。
要入门Flask,首先我们得知道什么是Web服务。Web服务是API的一种形式,它假定API通过服务器托管,并且可以被调用。Web API/Web Service——这些术语通常可以互换使用。
Flask是一个用Python编写的轻量级Web服务框架,当然,它不是Python中的唯一框架,同类竞品还有Django、Falcon、Hug等。但本文只介绍如何用Flask创建API。
如果你下载了Anaconda版,里面就已经包含了Flask。如果你想用pip:
pip install flask
你会发现它非常小,这也是它深受Python开发人员喜爱的一个原因。而另一个原因就是Flask框架附带内置的轻量级Web服务器,需要的配置少,而且可以用Python代码直接控制。
下面的代码很好地展示了Flask的简约性。它创建一个简单的Web-API,在接收到特定URL时会生成一个特定的输出。
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Welcome to machine learning model APIs!"
if __name__ == '__main__':
app.run(debug=True)
运行后,你可以在终端浏览器中输入这个网址,然后观察结果。
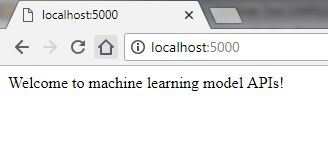
一些要点

app.run(debug=True,port=12345)。
现在我们来看看输入的代码:
test.py和run.py,并且将test.py导入run.py,那么test.py的“name”值就会是test (app = Flask(test))。hello()的定义,可以用@app.route(“/“)。同时,装饰器route()可以告诉Flask什么URL可以触发定义好的hello()。hello()的作用是在使用API时生成输出。在这种情况下,在Web浏览器转到localhost:5000/会产生预期的输出(假设是默认端口)。如果我们想为机器学习模型创建API,下面是一些需要牢记的东西。
在这里,我们以最常规的Scikit-learn模型为例,介绍一下怎么用Flask学习Scikit-learn模型。首先,我们来回顾一下Scikit-learn的常用模块:
对于一般数据,我们在进行发送和接收时会涉及将对象转化为便于传输的格式的操作,它们也被称为对象的序列化(serialization)和反序列化(deserialization)。模型和数据很不一样,但Scikit-learn刚好支持对训练模型的序列化和反序列化,这就为我们节省了重新训练模型的时间。通过使用scikit-learn中的模型序列化副本,我们可以编写Flask API。
同时,Scikit-learn模型的一个要求是数据必需采用数字格式,这就是为什么我们需要把数据集里的分类特征转成数字特征0和1。事实上,除了分类,Scikit-learn的sklearn.preprocessing模块还提供诸如LabelEncoder、OneHotEncoder等编码方法。
此外,对于数据集里的缺失值,Scikit-learn不能自动填充,而是需要我们自己手动处理,然后再输入模型。缺失值和上面提到的特征编码其实都是数据预处理的重要步骤,它们对构建性能良好的机器学习模型非常重要。
为了方便演示,这里我们以Kaggle上最受欢迎的数据集——泰坦尼克为例进行讲解。这个数据集主要是个分类问题,我们的任务是根据表格数据预测乘客的生存概率。为了进一步简化,我们只用四个变量:age(年龄)、sex(性别)、embarked(登船港口:C=Cherbourg, Q=Queenstown, S=Southampton)和survived。其中survived是个类别标签。
# Import dependencies
import pandas as pd
import numpy as np
# Load the dataset in a dataframe object and include only four features as mentioned
url = "http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv"
df = pd.read_csv(url)
include = ['Age', 'Sex', 'Embarked', 'Survived'] # Only four features
df_ = df[include]
“Sex”和“Embarked”是非数字的分类特征,我们需要对它们进行编码;“age”这个特征有不少缺失值,这点可以汇总统计后用中位数或平均数来填充;Scikit-learn不能识别NaN,所以我们还要为此编写一个辅助函数:
categoricals = []
for col, col_type in df_.dtypes.iteritems():
if col_type == 'O':
categoricals.append(col)
else:
df_[col].fillna(0, inplace=True)
上面的代码是为数据集填补缺失值。这里需要注意一点,缺失值对模型性能其实很重要,尤其是当空值过多时,我们用单个值填充要非常谨慎,不然很可能会导致很大的偏差。在这个数据集里,因为有缺失值的列是age,所以我们不应该用0填充NaN。
至于把非数字特征转成数字行驶,你可以用One Hot Encoding,也可以用Pandas提供的get_dummies():
df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)
现在我们已经完成了预处理,可以准备训练机器学习模型了:选择Logistic回归分类器。
from sklearn.linear_model import LogisticRegression
dependent_variable = 'Survived'
x = df_ohe[df_ohe.columns.difference([dependent_variable])]
y = df_ohe[dependent_variable]
lr = LogisticRegression()
lr.fit(x, y)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
有了模型,之后就是保存模型。从技术上讲这里我们应该对模型做序列化,在Python里,这个操作被称为Pickling。
调用sklearn的joblib:
from sklearn.externals import joblib
joblib.dump(lr, 'model.pkl')
['model.pkl']
Logistic回归模型现在保持不变,我们可以用一行代码把它加载到内存中,而把模型加载回工作区的操作就是反序列化。
lr = joblib.load('model.pkl')
要用Flask为模型创建服务器,我们要做两件事:
更具体地说,当你输入以下内容时:
[
{"Age": 85, "Sex": "male", "Embarked": "S"},
{"Age": 24, "Sex": '"female"', "Embarked": "C"},
{"Age": 3, "Sex": "male", "Embarked": "C"},
{"Age": 21, "Sex": "male", "Embarked": "S"}
]
你希望API的输出会是:
{"prediction": [0, 1, 1, 0]}
其中0表示遇难,1表示幸存。这里输入格式是JSON,它是最广泛使用的数据交换格式之一。
要做到上述效果,我们需要先编写一个函数predict(),它的目标如前所述:
我们已经演示了如何加载已有模型,之后是根据接收的输入预测人员生存状态:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
json_ = request.json
query_df = pd.DataFrame(json_)
query = pd.get_dummies(query_df)
prediction = lr.predict(query)
return jsonify({'prediction': list(prediction)})
虽然看起来挺简单,但你可能会在这个步骤遇到一个小问题。
为了让你编写的函数能正常运行,传入请求中必需包含这四个分类变量的所有可能值,这些值可能是实时的,也可能不是。如果传入请求里出现必要值缺失,那么根据当前方法定义的predict()生成的数据列会比分类器里少,模型就会报错。
要解决这个问题,我们需要在模型训练期间把列保留下来,把任何Python对象序列化为.pkl文件。
model_columns = list(x.columns)
joblib.dump(model_columns, 'model_columns.pkl')
['model_columns.pkl']
由于已经保留了列列表,所以你可以在预测时处理缺失值(记得在APP启动前加载模型):
@app.route('/predict', methods=['POST']) # Your API endpoint URL would consist /predict
def predict():
if lr:
try:
json_ = request.json
query = pd.get_dummies(pd.DataFrame(json_))
query = query.reindex(columns=model_columns, fill_value=0)
prediction = list(lr.predict(query))
return jsonify({'prediction': prediction})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print ('Train the model first')
return ('No model here to use')
你已经在“/ predict”API中包含了所有必需元素,现在你只需要编写主类:
if __name__ == '__main__':
try:
port = int(sys.argv[1]) # This is for a command-line argument
except:
port = 12345 # If you don't provide any port then the port will be set to 12345
lr = joblib.load(model_file_name) # Load "model.pkl"
print ('Model loaded')
model_columns = joblib.load(model_columns_file_name) # Load "model_columns.pkl"
print ('Model columns loaded')
app.run(port=port, debug=True)
现在,这个API就全部完成可以托管了。
当然,如果你想把Logistic回归模型代码和Flask API代码分离为单独的.py文件,这其实是一种很好的编程习惯。那么你的model.py代码应该如下所示:
# Import dependencies
import pandas as pd
import numpy as np
# Load the dataset in a dataframe object and include only four features as mentioned
url = "http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv"
df = pd.read_csv(url)
include = ['Age', 'Sex', 'Embarked', 'Survived'] # Only four features
df_ = df[include]
# Data Preprocessing
categoricals = []
for col, col_type in df_.dtypes.iteritems():
if col_type == 'O':
categoricals.append(col)
else:
df_[col].fillna(0, inplace=True)
df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)
# Logistic Regression classifier
from sklearn.linear_model import LogisticRegression
dependent_variable = 'Survived'
x = df_ohe[df_ohe.columns.difference([dependent_variable])]
y = df_ohe[dependent_variable]
lr = LogisticRegression()
lr.fit(x, y)
# Save your model
from sklearn.externals import joblib
joblib.dump(lr, 'model.pkl')
print("Model dumped!")
# Load the model that you just saved
lr = joblib.load('model.pkl')
# Saving the data columns from training
model_columns = list(x.columns)
joblib.dump(model_columns, 'model_columns.pkl')
print("Models columns dumped!")
而api.py则是:
# Dependencies
from flask import Flask, request, jsonify
from sklearn.externals import joblib
import traceback
import pandas as pd
import numpy as np
# Your API definition
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
if lr:
try:
json_ = request.json
print(json_)
query = pd.get_dummies(pd.DataFrame(json_))
query = query.reindex(columns=model_columns, fill_value=0)
prediction = list(lr.predict(query))
return jsonify({'prediction': str(prediction)})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print ('Train the model first')
return ('No model here to use')
if __name__ == '__main__':
try:
port = int(sys.argv[1]) # This is for a command-line input
except:
port = 12345 # If you don't provide any port the port will be set to 12345
lr = joblib.load("model.pkl") # Load "model.pkl"
print ('Model loaded')
model_columns = joblib.load("model_columns.pkl") # Load "model_columns.pkl"
print ('Model columns loaded')
app.run(port=port, debug=True)
现在,你可以在名为Postman的API客户端中测试此API 。只要确保model.py与api.py在同一个目录下,并确保两者都已在测试前编译好了,如下图所示:
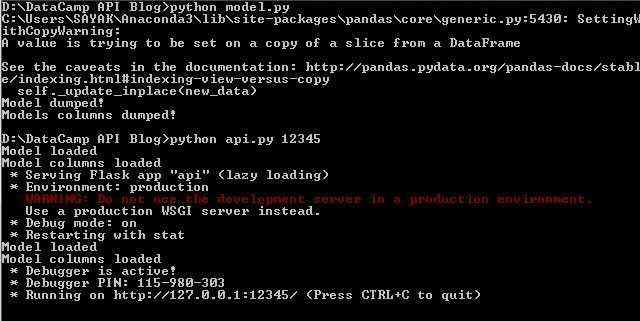
如果所有文件都已成功编译,目录结构应该如下图所示:

注:IPYNB文件是可选的。
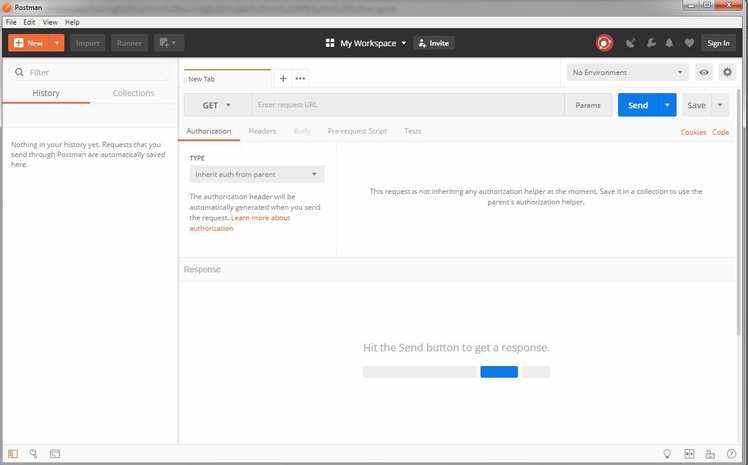
Postman是测试API最好用的工具之一。如果你下载了最新版本,它的界面应该如下所示:
成功启动Flask服务器后,你需要在Postman中输入包含正确端口号的正确URL:
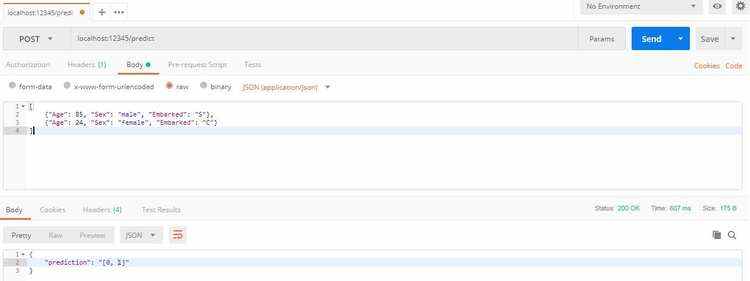
恭喜!你刚刚构建了第一个机器学习API。这是个可以根据泰坦尼克号乘客age、sex和embarked信息预测他们生存状态的API,现在,你的朋友就能用前端代码调用它,输出神奇的结果。




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 