Directives provide a way to describe alternate runtime execution and type validation behavior in a GraphQL document.
In some cases, you need to provide options to alter GraphQL’s execution behavior in ways field arguments will not suffice, such as conditionally including or skipping a field. Directives provide this by describing additional information to the executor.
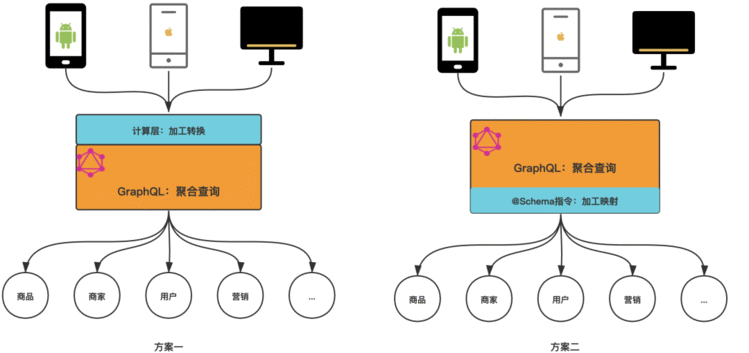


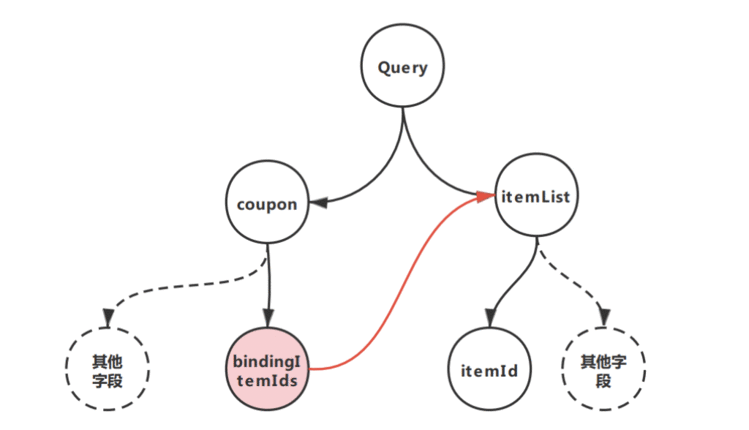



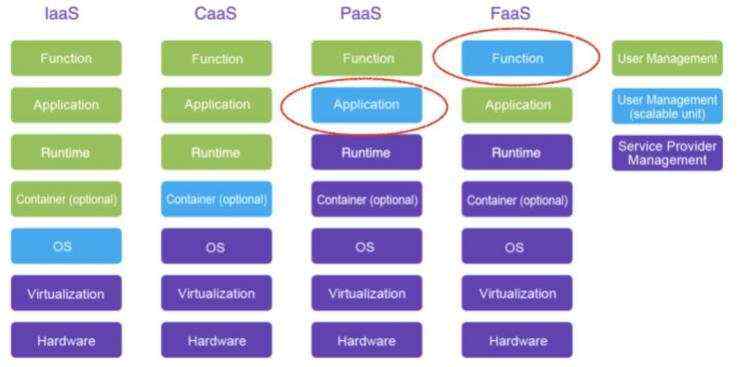
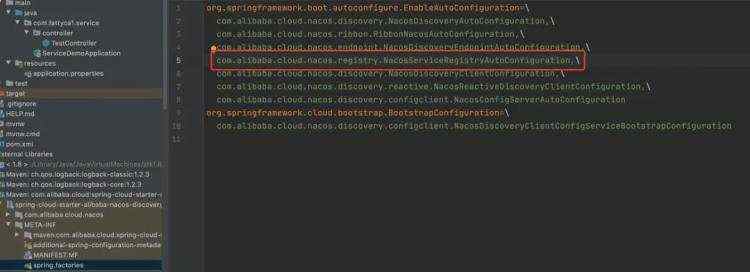

 京公网安备 11010802041100号
京公网安备 11010802041100号