作者:yanghuimin | 来源:互联网 | 2023-07-27 17:46
参考http:blog.sina.com.cnsblog_81bdf4030102y4fa.html尝试的linux环境1.安装python3,原先安装了pyth
参考http://blog.sina.com.cn/s/blog_81bdf4030102y4fa.html
尝试的linux环境
1.安装python3,原先安装了python2.7.这里需要ln -s 更改下软连接(改之前移除2.7链接),使得用python命令的时候调用的是python3的而不是python2.7
2.用pip3 安装Crypto 用来解密文件(.ts的视频需要解密,无法直接播放)
3.找到m3u8文件,此步骤需要我们手动操作:
刷新视频页面即可找到index.m3u8文件,然后按f12查看控制台,

找到后右键复制地址到下面代码中的_url变量即可
解释:m3u8文件记录了ts视频的解码KEY地址和各视频切片的文件名,该网址网大的m3u8文件格式如下
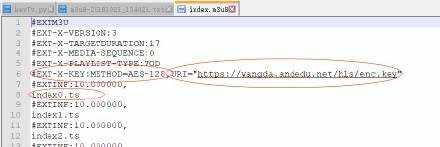
不同网站的m3u8文件格式可能不一样。
此处我们需要提取解码key,并拼接出各个视频文件的地址即可,代码中已经实现,无需操作。
4.视频处理-合并视频
程序将提取到的小切片ts视频,合并成一个大的ts文件。这种格式可以直接使用 windows media player 播放,但是用QQ视频播放的话会没有声音。
再把ts转诚mp4
linux:安装ffmpeg 工具进行转换。
yum安装的时候提示没有这个安装包,需要先安装下epel-release.再用yum 安装就有了。
然后根据上诉逻辑的python代码如下(针对windows的,所以目录还不对)
# -*- coding: UTF-8 -*-
import os
import sys
import requests
import datetime
from Crypto.Cipher import AES
def download(url):
download_path = os.getcwd() + "/download" #os.getcwd()返回当前工作目录
if not os.path.exists(download_path):
os.mkdir(download_path)
#新建日期文件夹
file_time=datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
download_path = os.path.join(download_path, file_time)
#print download_path
os.mkdir(download_path)
all_content = requests.get(url).text # 获取第一层M3U8文件内容
fd = open(download_path+'/indexs.txt', 'w') #把所有的.ts文件名称都放在这个文件。
if "#EXTM3U" not in all_content:
raise BaseException("非M3U8的链接")
if "EXT-X-STREAM-INF" in all_content: # 第一层
file_line = all_content.split("\n")
for line in file_line:
if '.m3u8' in line:
url = url.rsplit("/", 1)[0] + "/" + line # 拼出第二层m3u8的URL
all_content = requests.get(url).text
file_line = all_content.split("\n")
unknow = True
key = ""
for index, line in enumerate(file_line): # 第二层
if "#EXT-X-KEY" in line: # 找解密Key
method_pos = line.find("METHOD")
comma_pos = line.find(",")
method = line[method_pos:comma_pos].split('=')[1]
print ("Decode Method:", method)
uri_pos = line.find("URI")
quotation_mark_pos = line.rfind('"')
key_path = line[uri_pos:quotation_mark_pos].split('"')[1]
print (key_path)
key_url=key_path
res = requests.get(key_url)
key = res.content
print ("key:" , key)
if "EXTINF" in line: # 找ts地址并下载
unknow = False
pd_url = url.rsplit("/", 1)[0] + "/" + file_line[index + 1] # 拼出ts片段的URL
print (pd_url)
res = requests.get(pd_url)
c_fule_name = file_line[index + 1].rsplit("/", 1)[-1]
fd.write('file \''+c_fule_name+'\'\n')
print(c_fule_name)
if len(key): # AES 解密
cryptor = AES.new(key, AES.MODE_CBC, key)
with open(os.path.join(download_path, c_fule_name), 'ab') as f:
f.write(cryptor.decrypt(res.content))
else:
with open(os.path.join(download_path, c_fule_name), 'ab') as f:
f.write(res.content)
f.flush()
if unknow:
raise BaseException("未找到对应的下载链接")
else:
print ("下载完成")
fd.close()
merge_file(download_path)
def merge_file(path):
os.chdir(path) #进入到这个目录
os.system('ffmpeg -f concat -i indexs.txt -c copy new.ts') #把文件合并成一个文件
os.system('ffmpeg -i new.ts -q 1 -c copy output.mp4') #转换ts为mp4格式
os.system('del /Q *.ts')
if __name__ == '__main__':
_url="https://wangda.andedu.net/default/M00/00/61/...../index.m3u8" #这里的链接 需要换成要爬取的m3u8文件地址。
download(_url)
还存在小问题,,,,目前









 京公网安备 11010802041100号
京公网安备 11010802041100号