作者:小白学习 | 来源:互联网 | 2023-09-07 16:23
这期内容当中小编将会给大家带来有关如何进行spark join的源码分析,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object JoinDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val random = scala.util.Random
val col1 = Range(1, 50).map(idx => (random.nextInt(10), s"user$idx"))
val col2 = Array((0, "BJ"), (1, "SH"), (2, "GZ"), (3, "SZ"), (4, "TJ"), (5, "CQ"), (6, "HZ"), (7, "NJ"), (8, "WH"), (0, "CD"))
val rdd1: RDD[(Int, String)] = sc.makeRDD(col1)
val rdd2: RDD[(Int, String)] = sc.makeRDD(col2)
val rdd3: RDD[(Int, (String, String))] = rdd1.join(rdd2)
println (rdd3.dependencies)
val rdd4: RDD[(Int, (String, String))] = rdd1.partitionBy(new HashPartitioner(3)).join(rdd2.partitionBy(newHashPartitioner(3)))
println(rdd4.dependencies)
sc.stop()
}
}1.两个打印语句:
List(org.apache.spark.OneToOneDependency@63acf8f6)
List(org.apache.spark.OneToOneDependency@d9a498)
对应的依赖:
rdd3对应的是宽依赖,rdd4对应的是窄依赖
原因:
1)参考webUI
由DAG图可以看出,第一个join和之前的清晰划分成单独的Satge。可以看出这个是宽依赖。第二个join,partitionBy之后再进行join并没有单独划分成一个stage,由此可见是一个窄依赖。
rdd3的join 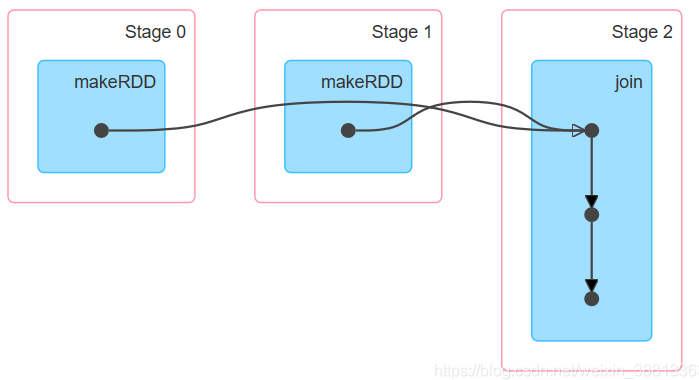
rdd4的join 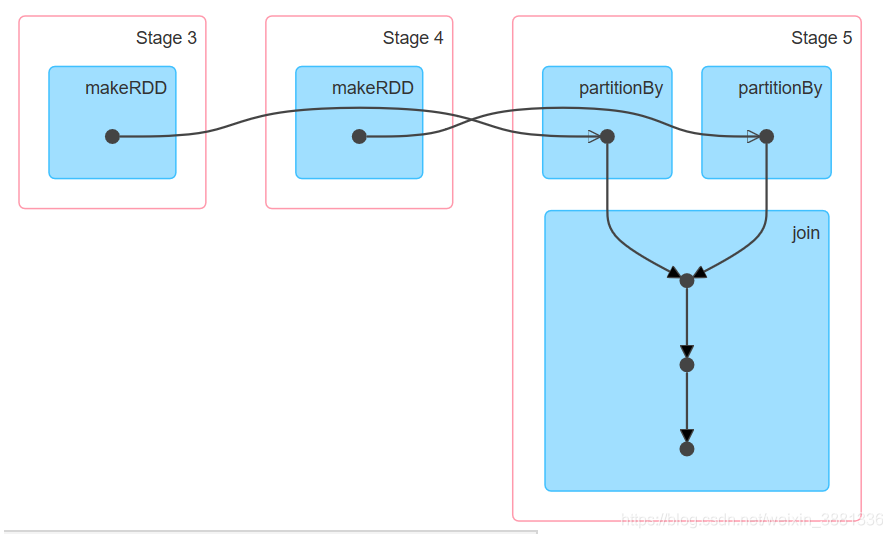
2)代码解析: a.首先是默认的join方法,这里使用了一个默认分区器
/**
* Return an RDD containing all pairs of elements with matching keys in `this` and `other`. Each
* pair of elements will be returned as a (k, (v1, v2)) tuple, where (k, v1) is in `this` and
* (k, v2) is in `other`. Performs a hash join across the cluster.
*/
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] = self.withScope {
join(other, defaultPartitioner(self, other))
}b.默认分区器,对于第一个join会返回一个以电脑core总数为分区数量的HashPartitioner.第二个join会返回我们设定的HashPartitioner(分区数目3)
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
val rdds = (Seq(rdd) ++ others)
val hasPartitioner = rdds.filter(_.partitioner.exists(_.numPartitions > 0))
val hasMaxPartitioner: Option[RDD[_]] = if (hasPartitioner.nonEmpty) {
Some(hasPartitioner.maxBy(_.partitions.length))
} else {
None
}
val defaultNumPartitions = if (rdd.context.conf.contains("spark.default.parallelism")) {
rdd.context.defaultParallelism
} else {
rdds.map(_.partitions.length).max
}
// If the existing max partitioner is an eligible one, or its partitions number is larger
// than the default number of partitions, use the existing partitioner.
if (hasMaxPartitioner.nonEmpty && (isEligiblePartitioner(hasMaxPartitioner.get, rdds) ||
defaultNumPartitions < hasMaxPartitioner.get.getNumPartitions)) {
hasMaxPartitioner.get.partitioner.get
} else {
new HashPartitioner(defaultNumPartitions)
}
}c.走到了实际执行的join方法,里面flatMapValues是一个窄依赖,所以说如果有宽依赖应该在cogroup算子中
/**
* Return an RDD containing all pairs of elements with matching keys in `this` and `other`. Each
* pair of elements will be returned as a (k, (v1, v2)) tuple, where (k, v1) is in `this` and
* (k, v2) is in `other`. Uses the given Partitioner to partition the output RDD.
*/
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}d.进入cogroup方法中,核心是CoGroupedRDD,根据两个需要join的rdd和一个分区器。由于第一个join的时候,两个rdd都没有分区器,所以在这一步,两个rdd需要先根据传入的分区器进行一次shuffle,因此第一个join是宽依赖。第二个join此时已经分好区了,不需要再再进行shuffle了。所以第二个是窄依赖
/**
* For each key k in `this` or `other`, return a resulting RDD that contains a tuple with the
* list of values for that key in `this` as well as `other`.
*/
def cogroup[W](other: RDD[(K, W)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other), partitioner)
cg.mapValues { case Array(vs, w1s) =>
(vs.asInstanceOf[Iterable[V]], w1s.asInstanceOf[Iterable[W]])
}
}e.两个都打印出OneToOneDependency,是因为在CoGroupedRDD里面,getDependencies方法里面,如果rdd有partitioner就都会返回OneToOneDependency(rdd)。
override def getDependencies: Seq[Dependency[_]] = {
rdds.map { rdd: RDD[_] =>
if (rdd.partitioner == Some(part)) {
logDebug("Adding one-to-one dependency with " + rdd)
new OneToOneDependency(rdd)
} else {
logDebug("Adding shuffle dependency with " + rdd)
new ShuffleDependency[K, Any, CoGroupCombiner](
rdd.asInstanceOf[RDD[_ <: Product2[K, _]]], part, serializer)
}
}
}join什么时候是宽依赖什么时候是窄依赖?
由上述分析可以知道,如果需要join的两个表,本身已经有分区器,且分区的数目相同,此时,相同的key在同一个分区内。就是窄依赖。反之,如果两个需要join的表中没有分区器或者分区数量不同,在join的时候需要shuffle,那么就是宽依赖
上述就是小编为大家分享的如何进行spark join的源码分析了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注编程笔记行业资讯频道。




![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号