作者:陈凯 GrowingIO 数据开发工程师,主要负责 SaaS 和 OP 产品数据平台的开发和设计,目前专攻于微服务、数仓建设方向。GrowingIO 每天需要处理近千亿的用户行为数据,平台的「事
作者:陈凯
GrowingIO 数据开发工程师,主要负责 SaaS 和 OP 产品数据平台的开发和设计,目前专攻于微服务、数仓建设方向。
GrowingIO 每天需要处理近千亿的用户行为数据,平台的「事件分析」模块是使用比较频繁的功能,简单且强大。在事件分析中,客户可以很灵活地使用多种维度组合去查看某个指标,并且查询的速度也十分可观。
本文抽取 GrowingIO 在事件分析中的通用数据模型,揭晓该功能背后的存储模型和实现原理。
在用户行为的数据分析中,无论是无埋点,还是埋点,对于某一条行为数据的表达形式往往是:「某人」于「某个时间」在「某个维度」下做了「某个动作」「多少次」。
所以在数据统计中,这种表达形式可以拆解成「指标量」和「维度」,指标量可以是用户量、页面浏览量、某个埋点的次数等,维度可以是时间、城市、浏览器、用户属性等。
在海量数据的背景下,如何比较高效地完成指标+维度的计算,一直是大数据分析领域比较热门的话题,下面将讲述在 GrowingIO ,我们是如何高效解决的。
1. 从一个数据需求说起?
假设给定如下一组用户行为的原始数据:
1.1 使用 SQL 分析统计
? 现在业务想计算「过去7天」在「地区」维度下,「设备: Mac」的人数是多少?So Easy,一个 SQL 搞定
使用 GrowingIO 平台的分析工具可以表示如下:

但是通过 SQL 这种现查的方式,随着数据量的越来越大,几十亿或上百亿的时候,对计算所需要的资源和响应时间也会线性地增长,此时客户在使用平台工具最直观的感受就是“菊花”转转转,图表一直加载不出来。
1.2 如何使查询更加高效
1.2.1 堆机器,加资源
最直接粗暴的方式,就是增加更多的计算资源,或者对查询的结果进行缓存、预热。但是对于 SaaS 产品来讲,在查询并发比较高的时候,再多的计算资源也会因为查询排队而遇到性能瓶颈。
1.2.2 数据分层
? 在数仓的分层架构中,对于经常使用的查询结果,我们可以通过离线计算的方式生成了一个结果表「过去7天-地区-设备-指标表」,示例如下:
这样在特性的查询场景中,只需要查询结果表就行,很大的减少了计算量,响应时间也短了不少。
? 但是业务那边的需求往往是千变万化的,然后一堆统计的需求砸到了你的脑袋上
「过去 30 天」的「总用户的量」和「总访问量」是多少?
「昨天」「设备: Windows」的「用户量」是多少?
「获取 30 天」按「平台」拆分的「用户量」是多少?
「11 月- 11 日」来了哪些用户?请导出这个用户列表
其他更多漏斗、留存、画像等数不尽的需求让人头晕目眩。
…
? 你看了看生成结果表,发现并不能完全解决这些问题,你觉得需要生成更多的结果表来满足更多的需求。然而到最后你发现有些表居然仅仅只使用了一次,数仓里面堆了一堆垃圾。
1.2.3 数据预聚合
和数仓分层的理念类似,对数据进行预计算、预聚合,使用空间换时间的思想加快计算。这也是目前一些主流开源框架的解决思路,比如 SparkSQL 的物化视图、Kylin的 Cube、Druid 的 Segment 、Carbondata 的 MV 等。
下面使用一张图展示主要区别:

基于我们所追求的方式,我们首先需要寻找一种高效并且灵活的存储模型。
1.3 优化存储模型
基于上节中数据预聚合的思路,从预聚合的结果中,我们不难发现,其中有几个没有摆脱的点:
多个维度依然是横向存储在一起
维度和指标绑定在一条记录中
因为存在这种局限性,刚好限制了我们灵活进行「维度+指标」的任意组装和扩展
? 如何才能更好的让维度和指标随心所欲地组合呢?我们在预聚合结果的基础之上做了一些改进:
将每个维度纵向存储
将维度和指标分开存储
2. 基于 BitMap 的存储模型 ?
2.1 纵向存储维度(人数)
依然以开篇的那组数据为例,此时将维度进行纵向存储:
此时想取「地区: 北京」和「设备: Mac」的「用户量」

OK!这样可以很灵活的解决各种维度组合起来的问题了,而且连用户的群体也能直接获取。
? 但是从表格中发现,用户存储「用户集合」的数据结构还没有解决。那么既能以类似数组的方式存储整数值,还能使用交集(and)操作,还需要达到更好的数据压缩和计算。
此时你应该想到了 BitMap 这种数据结构
至于为何选用 BitMap 的数据结构,以及 BitMap 的功能和基本使用,这里不再探讨。可以参考 java 的实现 BitSet 以及优化的库 RoaringBitmap。
2.2 存储指标量(次数)
为了解决存储指标次数的存储问题,你需要用一个Map 的结构来存储「总的次数」: Map (其中key为次数,value为符合访问次数的人)

访问量表示: 总共访问「1次」有哪些人,访问「2次」的有哪些人等等。
此时计算「地区: 北京」和「设备: Mac」的「访问量」
2.3 使用更优雅的方式存储次数
在 Map 这个结构中,key 存储的是 10 进制的数字。这就会导致 Map 的 key 变得特别特别多,所以需要有一种方式来优化一下结构。
方式就是用将 10 进制转化为 2 进制的方式去存储次数,此时 Map 的 key 存储是 二进制为 1 的位置:
比如 2 的二进制是: 「10」,从右向左分别表示(下标i从0开始)「第0位是0」,「第1位是1」。所以将key为1的 bitmap 中存储这个人。
比如5的二进制是: 「101」,从右向左分别表示「第0位是1」,「第1位是0」,「第2位是1」。所以将 key 为 0 和 2 的 bitmap 中存储这个人。
然后将上节 2.2 中结果表示如下:

此时计算「地区: 北京」和「设备: Mac」的「访问量」

3. 多维度交叉的问题 ⚔️
理想是美好的,但是现实很残酷。在 2.1 小节的例子中,每个用户的维度组合只有一种,但是现实中往往一个用户行为可能会存在多种维度组合的情况。
那么什么是维度组合: 一条数据中唯一的所有维度值,称为一个组合。
PS: 如果你的系统中某个 ID 的维度组合只有一种。比如某个订单,一旦生成了,他的价格,商品,物流等信息基本都是固定的。那么之前的模型基本都能满足大多场景了。
3.1 面临的问题
? 那么会导致什么问题呢?此时回到起点,又来了一批用户行为的数据如下:

此时多了一个「用户1」在「杭州」使用了「Windows」。如果按照之前的模型存储如下:
此时计算「地区: 北京」的用户:直接返回 [ 1 , 2 , 3 ],问题不大
此时计算「地区: 北京」和「设备: Windows」的用户

❌ 你会发现,得出的结果是错的,应该只有「用户 3 」满足才对。
3.2 使用维度组合编号的方式解决
其实问题出在将维度分开进行存储的时候,丢失了「维度组合关系」这个重要的衡量条件。「用户 1 」虽然在「北京」待过,也使用过「Windows」,但是他却没有同时满足这个条件,这就是问题所在。
所以需要一种方式来存储「维度组合关系」这一重要信息。
将每个人维度组合进行顺序编号,得到如下结果:

注意:编号是对应到每个人的,相同的维度组合,编号是一样的。
此时对应的存储结构也发生了变化:Map( key 代表编号,value 代表人的集合
此时我们再来计算「地区: 北京」和 「设备: Windows」维度的用户
最后得到的结果就是「用户3」,算出来的数据就变准确了。
3.3 多维度情况下计算次数
其实稍微想一下就是两层的 Map 结构:Map>,比如刚刚的那组数据表示如下:
比如「用户1」这个用户,在「编号0」发生的 2 次,在「编号1」发生了 1 次

此时我们来计算「地区: 北京」和 「设备: Mac」维度的访问量

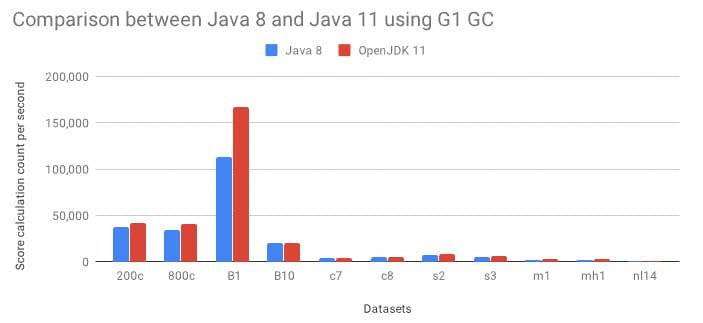
4. 简单的性能对比
环境准备:SparkSQL(local[16], 内存4G), BitMap 单线程计算(内存4G)
场景:简单的 2 ~ 3 个维度组合求人数、次数,按照值的降序取 Top 1000
x轴含义: 数据量/用户量。
y轴含义: 计算时间, 单位毫秒。
可以看到随着数据量的不断递增,SparkSQL 的计算时间也在不断递增,但是 BitMap 的计算时间却相对比较稳定。
5. 总结
BitMap 是一个兼并计算和存储优】势的数据结构,在存储上百万甚至上千万的 ID 时,也能得到很好的计算效果。
并且当你使用 BitMap 存储的时候,就已经天然支持很多的业务场景,比如分群计算、标签计算、漏斗分析、留存分析、用户触达等,因为无需再重新计算人群。
本篇主要揭晓我们是如何基于 BitMap 来作为底层的数据模型,当然在实际应用过程中还有很多的挑战,由于篇幅原因,这里就不展开讲述了。
以下列出一些我们后续的工作内容和攻克方向:
bitmap 是以 int 值进行存储的,但是在实际生产中,你的 ID 数据可能是类似 UUID 的这种字符串,那么需要解决 string 转唯一 int 的问题。
如何使 bitmap 在分布式环境下达到更好的计算效果
如何解决高基维度所带来的挑战
如何在实时、图表分析、分群画像以及更多的业务场景中进行使用
如何设计一个类 SQL 语言来兼容这种数据模型
…
关于GrowingIO
GrowingIO 是基于用户行为数据的增长平台,国内领先的数据运营解决方案供应商。为产品、运营、市场、数据团队及管理者提供客户数据平台、获客分析、产品分析、智能运营等产品和咨询服务,帮助企业在数据化升级的路上,提升数据驱动能力,实现更好的增长。
如果对我们的产品有兴趣,欢迎点击此处,获取15天免费试用!




![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)


 京公网安备 11010802041100号
京公网安备 11010802041100号