作者:喏焿你一辈子_997 | 来源:互联网 | 2023-07-23 20:03
编辑导读:AppleSiri、天猫精灵等智能对话产品如今越来越多出现在大众视野,也获得了人们的喜爱,其对话系统也引起了人们的注意。本文将围绕任务驱动型人机对话系统,对其设计展开六方
Apple Siri、天猫精灵等智能对话产品现在越来越出现在大众的视野中,得到了人们的喜爱,其对话系统也引起了人们的关注。 本文以任务驱动的人机交互系统为中心,对其设计展开了六个方面的分析,希望对你有所帮助。

近年来,随着NLP技术的进一步发展,越来越多的智能对话产品进入了大众的视野。 在方便我们生活的同时,如Apple Siri、亚马逊Echo、谷歌之家、天猫精灵等,对话系统也逐渐开始受到关注。
本文结合工作实践,对目前主流的对话系统进行了介绍,包括对话系统的组成、设计原理、应用实践及其重要难点。
一、对话机器人类型及应用会话机器人目前根据应用场景和功能功能,主要分为三种类型。 问答机器人、任务机器人、闲谈机器人。
问答游戏; a机器人:问答游戏; a机器人主要依靠强大的知识库,可以对用户的提问给出特定的回答。 要求对回复内容有正确性,但仅限于一问一答的一次对话交流,不支持上下文信息,目前多用于客服领域。
任务机器人:机器人通过多次对话以交互方式满足用户的特定任务需求。 对任务完成度要求较高,其中机器人主要通过对话状态的跟踪、提问、澄清等了解用户意图,然后以回复或调用API的形式完成用户的任务需求。 例如,进行订票、吃饭预约等任务。
闲谈机器人:机器人与用户互动开放,用户没有明确的目的,机器人的回复也没有标准答案。 不要求回复内容的准确性,主要以趣味性和个性化的回复来满足用户的情感需求。
另一方面,在集成式对话机器人中,多为上述交互组合,如上述天猫精灵、百度小度等智能扬声器产品,可以同时满足用户的问答、任务、闲聊等多种需求。
下面,将聚焦任务机器人的中心对话系统的设计进行详细叙述。
二、任务机器人对话系统实现方式任务型交互系统目前主要有两种实现技术。 一种是基于流水线的实现方式,另一种是端到端的实现方式。
2.1 流水线(pipeline)

。
上图是基于流水线实现的对话系统的典型结构图,也称为规则对话系统。
整个系统有四个核心模块,分别是由NLU、DST、DPL和NLG依次串联组成的一条流水线,各个模块可以独立设计,模块之间合作完成任务型对话。
自然语言理解(NLU ) )主要对人机交互过程中产生的对话进行语义理解; 对话状况跟踪器(DST ) )管理包括历史状态记录和当前状态输出在内的各对话状况; 交互策略(DPL )根据当前交互情况执行的下一个系统响应策略; 将自然语言生成(NLG )对话策略输出的含义转换为自然语言。
2.2 端到端(end-to-end)

。
端到端(end-to-end )对话系统主要组合了深度学习技术。 是利用数据模型驱动,通过大量数据训练,挖掘用户从自然语言输入到系统自然语言输出的整体映射关系,忽视中间过程的一种方法。
目前,对于整个工业界的应用,端到端方法的灵活性和可扩展性较高,但对数据质量和数量的要求也较高,存在不可控性和不可解释性等问题,因此工业界的对话系统目前多采用基于规则的流水线实现方式。
笔者结合自己的工作实践,重点为大家分析基于规则的对话系统是如何设计和运营的。
三、基于规则的对话系统设计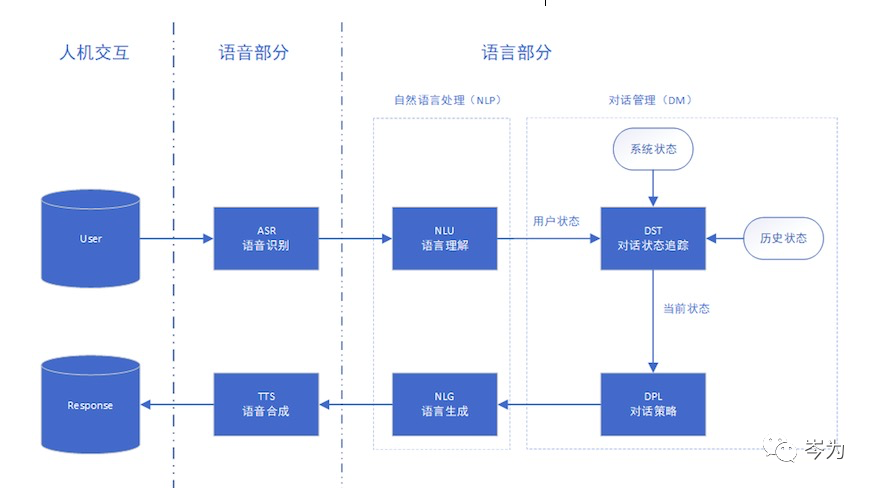 。
。
上图为基于规则的对话系统架构,主要由语音识别(ASR )、自然语言理解) NLU )、对话管理) DM )、自然语言生成) NLG )、语言合成) TTS )五个模块组成。 各模块之间相互合作,共同完成对话任务。
其中,ASR和TTS主要由语音机器人运用,但目前国内的这项技术比较熟练,一般可以直接采用AlibabaCloud (阿里巴巴云)、科大讯飞等供应商的服务。 下面重点对NLU、DM、NLG三个核心模块进行详细分析。
3.1 自然语言理解模块(NLU)
自然语言理解(NLU )模块,主要通过意图识别和插槽识别)信息提取),理解会话中用户语句的含义。
意图识别(Intent Prediction )的目的是理解用户表达的意图,核心其实是处理分类问题,将用户的语言分类为预先定义的意图类别。 目前,主要基于深度学习的方法,利用卷积神经网络(CNN )进行query的特征提取和意图分类,同样的方法也适用于领域的分类。
槽填充(Slot Filling )提取会话中的重要信息,本质上是给文中的词加上语义标签(上图的Slots日期、
地点),具体方法有CRF(条件随机场)、Deep Brief Network(深度信念网络)以及RNN(循环神经网络)等。
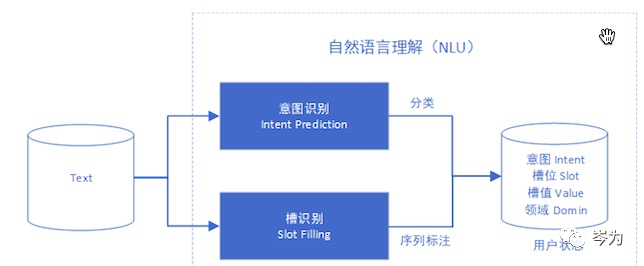
NLU的结果(intent和slot)会作为用户状态输入到对话管理模块,应用于对话状态的更新和维护。
3.2 对话管理模块(DM)

对话系统中对话管理(DM)模块由对话状态跟踪器(DST)和对话策略(DPL)构成,此模块就相当于任务型机器人的大脑,是很重要的决策模块。
常见的DM实现方式有多种:基于规则的有限状态机,基于统计的方法,基于神经网络的方法。
几种方法各有利弊,但基于通用性、可控性和数据成本等考量,目前工业应用还是以有限状态机为主流,根据多维状态的组合输出对应策略,规则简单也比较适用于冷启动。

对话状态追踪(DST):每一轮对话中估计用户的目标,常用的状态结构是槽填充(slot filling)或语义框架(semantic frame)。参照上图,对每一轮对话进行状态的记录和更新,主要通过记录历史状态、用户状态(槽位&意图等信息)和系统状态(初始信息&配置信息),来更新当前对话状态。
对话策略学习(DPL):根据当前对话的状态,产生系统下一步执行动作(回答、澄清、动作执行等),对话策略的设计也与任务场景强相关。可以使用监督学习和强化学习的方法,不过目前工业上多采用规则的方法,事先定义好state对应的action。
3.3 自然语言生成模块(NLG)
自然语言生成主要是将策略模块生成的抽象系统动作转化为自然语言形式的浅层表达,输出到用户端。目前有三种方法:基于话术模版、基于知识库检索、基于深度模型。模版与知识库主要是基于规则的策略,深度模型可以用如LSTM,seq2seq等网络生成自然语言。
基于规则的方法虽简单易用,但适应不了更开放的场景,当场景复杂动作较多时,策略规则的制定也会耗费大量的精力。一旦规则确定,回复基本固定,灵活性较差,多样性不足,造成体验感不高。
而好的NLG需具备4个特性:恰当、流畅、易读、灵活,即回复的自然语言不仅要精确表达出策略动作的语义,还要具备一定的“类人性”,让人机对话尽可能靠近人与人之间的对话,这也是后续NLG模块需要持续探索与改良的核心关键点。
四、应用案例
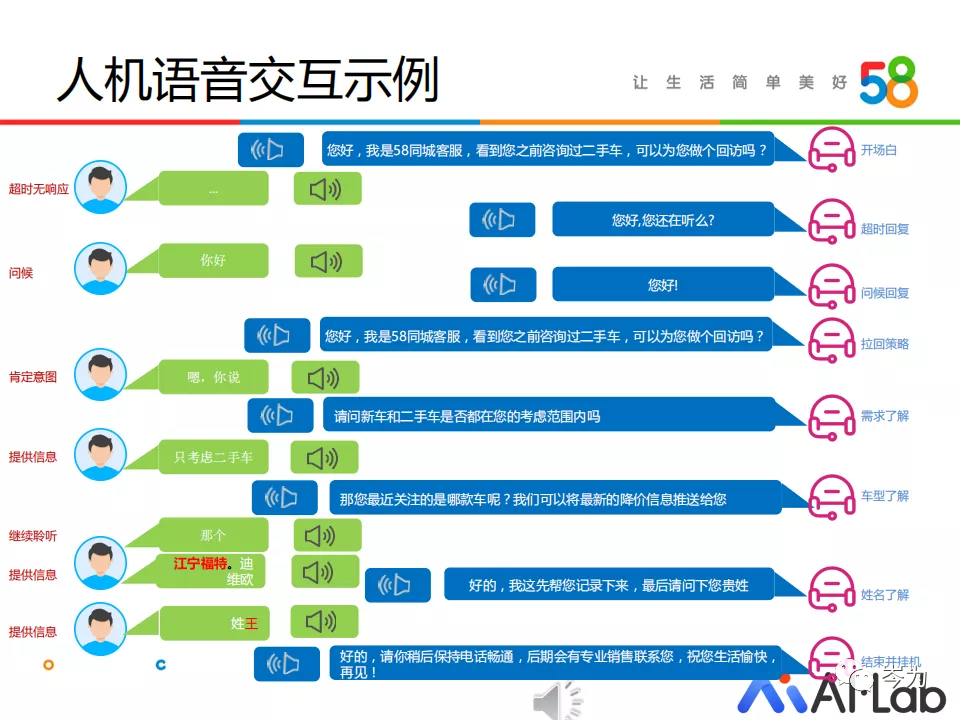
我们以58一个二手车回访真实场景的人机语音交互对话为例,阐述下对话系统各模块间是如何协同运作的。
我们从第四轮对话开始切入:当机器人第一次执行问槽策略时,槽位名称”需求了解“,执行话术“请问新车和二手车是否都在您的考虑范围内?”
4.1 语言理解
此刻当用户回复”只考虑二手车“时,用户的话会做前处理经ASR转译成文本,后将文本输入到语言理解(NLU)模块。
意图识别:NLU模块一般会优先匹配预设QA,若无QA能匹配上,则进入深度意图模型进行意图识别,此刻识别意图为”提供信息“。槽识别:同时进行NLU模块的另一任务”槽识别“,我们也称这一过程为填槽(Slot Filling),本轮“需求了解”的槽值(Slot Value)识别为“二手车”。
4.2 对话管理
对话状态:然后NLU模块的意图和槽位信息作为用户状态输入DM状态模块,状态模块结合系统状态、用户状态、历史状态,更新当前状态:当前匹配QA:“None”;当前意图:“提供信息”;当前槽位名称&槽值:“需求了解”&“二手车”;是否还有需要询问的槽位;对话策略:根据当前对话状态,设计好的策略中系统应执行的下步策略:继续询问“车型了解”槽位,更精准定位用户需求。
4.3 自然语言生成
随后在自然语言合成模块(NLG)根据设定好的策略规则确定输出话术,机器人执行问槽回复“那您最近在关注哪款车呢?我们可以将最新的降价信息推送给您。”
至此,对话系统从用户输入到机器人输出,完成了一轮完整的对话流程。后续就是进行重复的对话流程循环,由此对话持续一轮一轮进行下去,直到机器人任务主动或被动结束。
五、任务型对话机器人难点问题
要想任务型对话机器人在应用中真正表现出色,体验感好,各个模块也都有自己需解决的重难点问题。
如意图模块,如何降低ASR误差带来的影响,解决语言的多样性和歧义性问题,槽位模块中如何提高抽取模型的复用性,解决实体消歧问题。整体上看自然语言处理(NLP)领域,还存在上下文理解、语义推理、场景可移植性等亟需研究突破的问题。
以上基于规则的任务对话系统,虽然简单易用,但其缺点也是显而易见的:对话管理模块中状态策略的定义与规则都高度依赖于人工设计,复杂的场景下状态和策略维度多起来的时候,就会耗费大量的设计与维护成本。同时用户的反馈数据难以传给模型再学习,各模块间的依赖和影响也比较高。
如何在简单任务下,提高DM模块的可复用性,降低机器人生产和更新成本,是快速商业化落地的关键点。目前业内很多公司已自行开发机器人工厂,将机器人生产的各环节模块化、抽样化、流程化、提升其通用性和兼容性,在尽可能多的任务场景下,实现机器人快速复制、设计、生产、上线的能力。
六、结语
对话机器人的能力成长依赖于NLP领域的技术进步,目前更多的应用落地还只是在特定场景下的简单任务。由此,对话机器人未来的发展也必定会倾向于更大的知识体系 ,更强的自然语言理解能力、逻辑推理能力及情绪交互能力,实现Bot进一步的智能化和人性化。
以上内容基于笔者结合学习和工作实践的思考,若有理解不到位之处,还望大家指正,更希望通过这篇文章能与各位多多交流。
本文由 @岑为 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议






 京公网安备 11010802041100号
京公网安备 11010802041100号