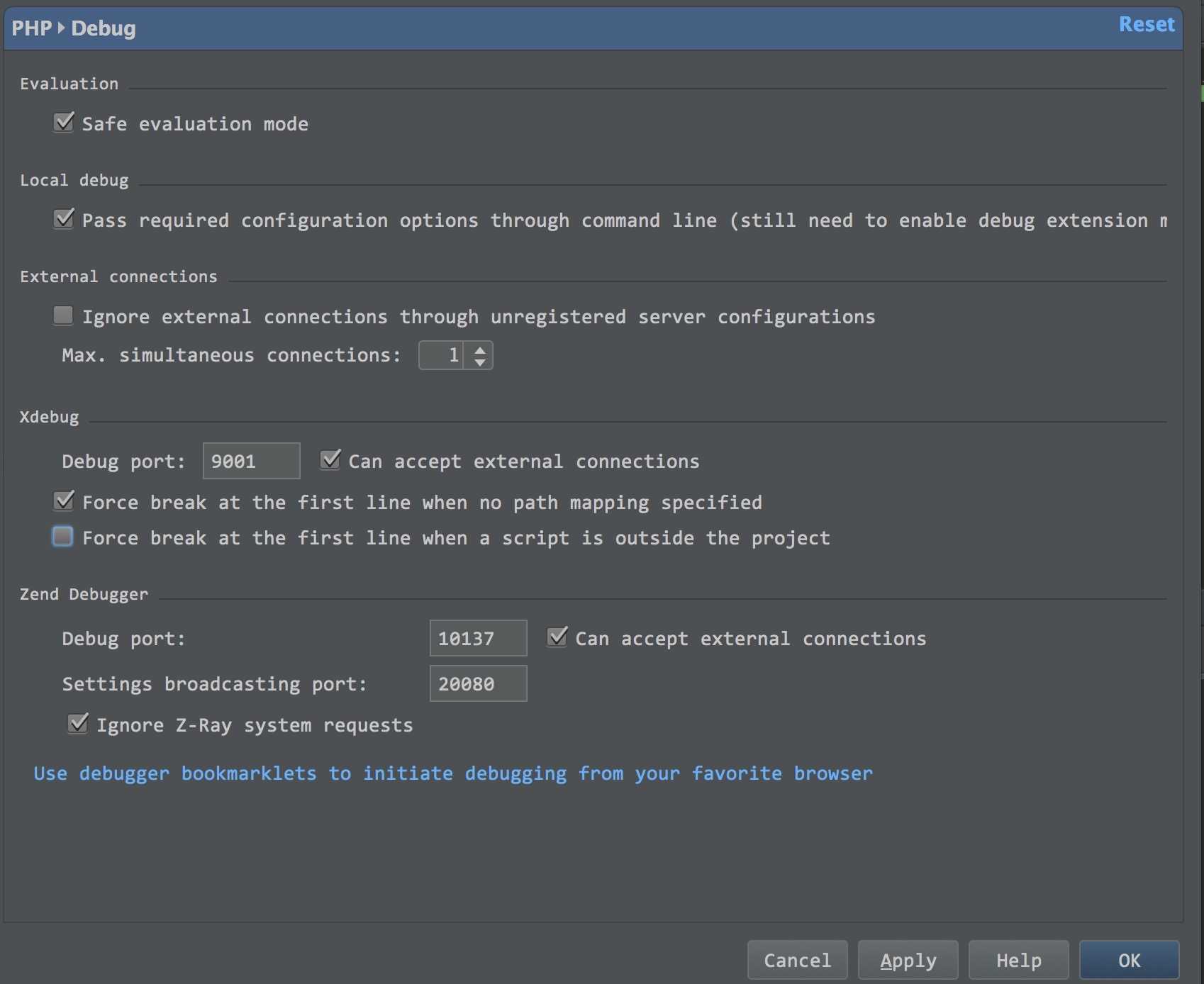
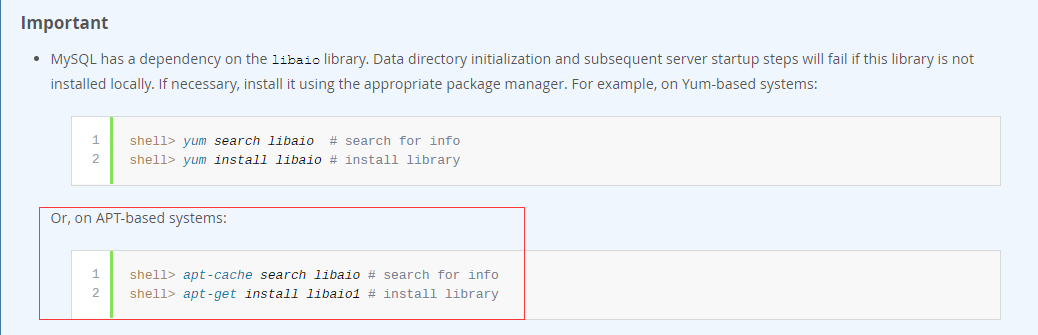
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- 集群配置 ----------------------------------- # # Use a descriptive name for your cluster: #配置集群名字,集群名字默认为elasticsearch, #elasticsearch会自动发现在同一网段下的elasticsearch节点。 #读者在第一次启动elasticsearch时,在浏览器中输入http://localhost:9200, #在返回的数据中,就有集群名字,默认即为elasticsearch。 #cluster.name: my-application # # ------------------------------------ 节点配置 ------------------------------------ # # Use a descriptive name for the node: #配置节点名称 #node.name: node-1 # # Add custom attributes to the node: #给节点添加自定义属性 #node.attr.rack: r1 # # ----------------------------------- 路径配置 ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): #数据存放目录,默认是elasticsearch下的data目录,可以指定多个目录,用,隔开,如: #path.data:/path/data1,/path/data2 #path.data:/path/to/data # # Path to log files: #日志存放目录,默认为elasticsearch下的logs目录 #path.logs:/path/to/logs # # ----------------------------------- 内存配置 ----------------------------------- # # Lock the memory on startup: #配置是否锁住内存。当jvm开始swapping时,elasticsearch的效率降低,为了避免这种情况,可以设置为true。 #bootstrap.memory_lock:true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- 网络配置 ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): #设置绑定的ip地址 #network.host:192.168.0.1 # # Set a custom port for HTTP: #配置对外提供服务的http端口号 #http.port:9200 # # For more information, consult the network module documentation. # # --------------------------------- 集群节点发现参数 ---------------------------------- # # Pass an initial list of hosts to perform discovery when newnode is started: # The default list of hosts is ["127.0.0.1","[::1]"] #设置集群中master节点的初始列表,通过这个配置可以发现新加入的集群的节点。 #discovery.zen.ping.unicast.hosts:["host1","host2"] # # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes /2+1): #保证集群中的节点可以知道其他n个有master资格的节点,防止出现split brain,默认为1 #discovery.zen.minimum_master_nodes: # # For more information, consult the zen discovery module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: #当n个节点启动后,再开始集群的恢复 #gateway.recover_after_nodes:3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name:true






 京公网安备 11010802041100号
京公网安备 11010802041100号