Redis是什么
Redis,全称是Remote Dictionary Service,翻译过来就是,远程字典服务。
redis属于nosql非关系型数据库。Nosql常见的数据关系,基本上是以key-value键值对形式存在的。
Key-value: 就像翻阅中文字典或者单词字典,通过指定的需要查询的字或者单词(key),可以查找到字典里面对应的详细内容和介绍(value)
Redis的一些特点:支持数据持久化、支持多种数据结构、支持数据备份、原子性操作等。
原子性:操作不能被中途打断。
Redis的由来
Redis的作者:意大利人 —— Salvatore Sanfilippo,现在至少四十几岁了,还在写代码。
Redis灵感来源:Alessia Merz,意大利一个舞者女郎。Merz在意大利有愚蠢的含义(俚语)。于是,Redis的默认服务端口号6379的来源灵感,来自于Mers这个词,详情可看九宫格输入法:

Redis的安装
Mac系统:brew install redis
Linux系列系统:apt-get install redis 或 yum install redis 或apt-get install redis-server 或 yum install redis-server
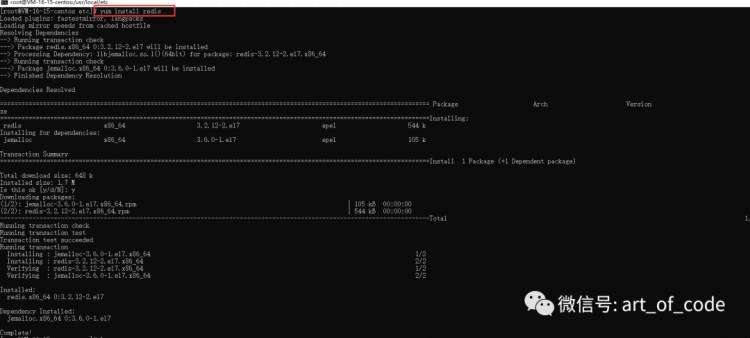
Windows系统:下载地址:https://github.com/tporadowski/redis/releases
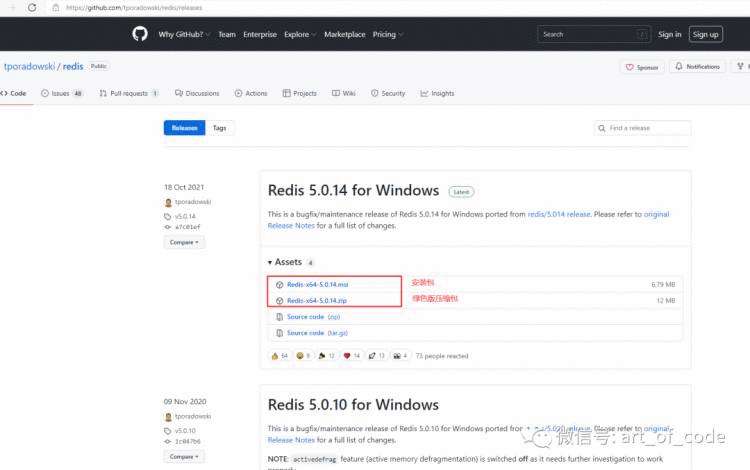
Redis启动方式
Mac/Linux: 启动服务端redis-server 启动客户端:redis-cli
如果需要后台启动,需要修改 redis.conf 文件,设置daemonize 为 yes
然后使用 redis-server /xxx/redis.conf 指定配置文件进行启动。xxx是指定的路径。
以下下载的姿势可能不对,版本有点低,所以后面暂且用windows环境下的进行测试。
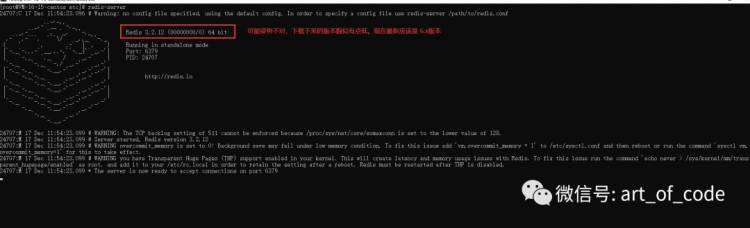
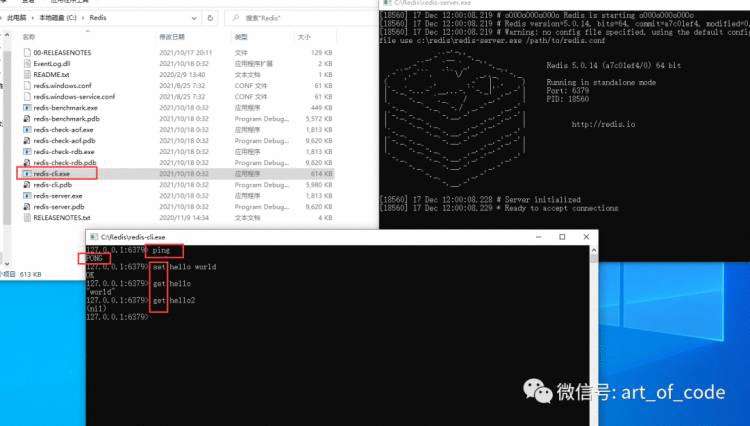
Windows启动方式:双击redis-server.exe文件即可运行
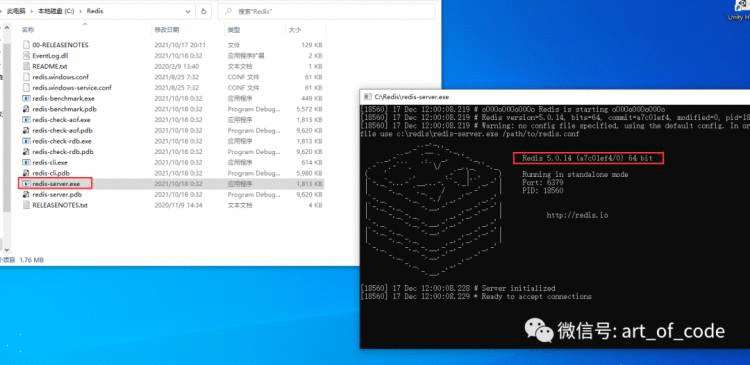
可以点击cli.exe文件,启动客户端。
输入ping,返回pong,代表服务是通的。
通过使用:set key value
可以用来设置一个键值对。
通过:get key
可以获取到key对应的value值。
通过命令创建redis密码:config set requirepass 密码

通过使用 命令:auth 密码
进行redis权限验证。
使用:keys * 可以显示所有当前存在的key

使用命令:select index
可以选择指定的Redis的Index(数据库)。Redis默认有最多16个数据库(或者叫Index),默认从0开始。例如上面设置的默认是0库,选择1库进行查询,就会没有东西。

Redis的数据结构
Redis的数据结构,体现在key-value的value上。Key默认都是字符串,value的基本数据结构包括字符串(string)、列表(list)、哈希(hash)、集合(set)、有序集合(zset)
字符串数据结构
字符串在redis里面是可变的。用一个图来简单说明一下。

字符串存储规则:Redis存储字符串期间,额外的空间分配规则是,当数据小于1MB的时候,每次扩容的空间是成倍增长的。大于1MB的时候,每次扩容的空间是1MB。
上面这段话如果不太理解,可以看Redis源码,源码内容如下。
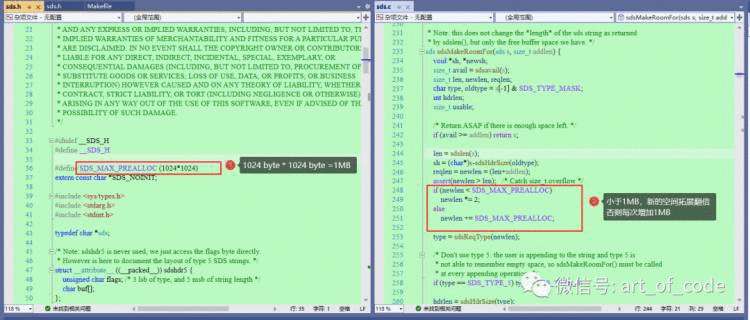
并且String单个数据最大的长度为 2^32-1=512M
关于字符串的其他操作:
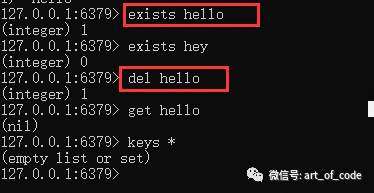
使用命令:exists key
可以查看是否存在该key;
使用命令:del key
可以直接删除指定的key以及对应的value。
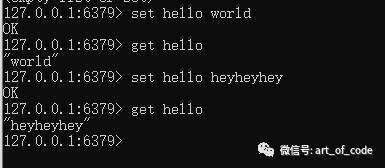
如果已有key,使用:set key xxx
会直接把key原有的值设置为xxx
使用命令: expire key second
可以给指定的key设置过期时间。例如我设置了10s过期,十秒以后,就会被自动销毁了。
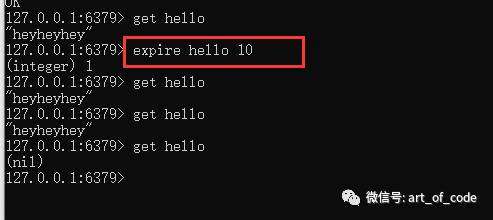
使用命令:setex key second value
可以设置key-value键值对,并且可以同时设置过期时间的秒数。
使用命令: ttl key
可以查看指定的key的剩余的过期时间。

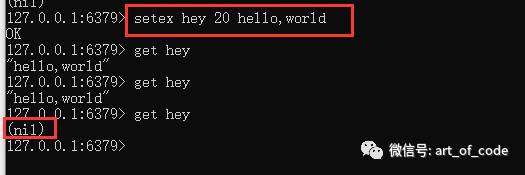
对于数值型的字符串,可以使用命令:incr key 和 decr key 进行自增1和自减1
使用命令:incrby key number 和 decrby key number 进行自增或自减指定的数值。
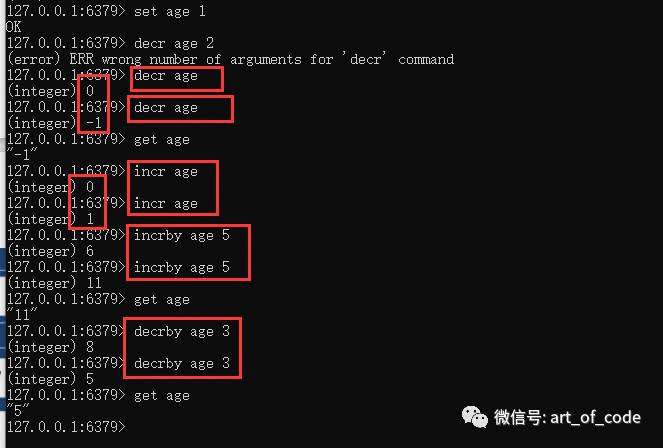
可以通过批量设置命令:mset key value key value……
进行批量设置。
通过:mget key key key……
进行批量读取。不过mget批量读取的结果集是个列表(因为带有序号)
列表数据结构
Redis的列表,最大可以存储40亿+个元素(2^32-1)。
列表的插入速度很快,时间复杂度是O,但是当数据量特别庞大的时候,使用索引进行查询操作会变得很慢,因为通过索引定位查询的时间复杂度为O(n)。
设置列表的key和value命令:lpush key value value value ……
可以设置一个key,带有多个元素的列表。l:left,代表的是左边,相当于每个元素是从左边被写入的(倒序插入)。
使用命令:lpop key
可以取出最左边的元素的值,同时会把该值舍弃掉。
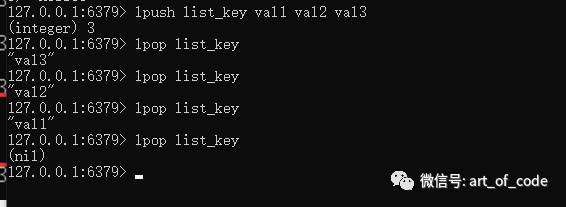
rpush是依次从右边插入(正序插入),rpop是取出最右边的元素的值,然后舍弃掉。r: right,代表右边
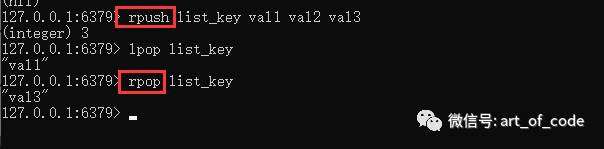
可以使用命令:linsert key before|after 指定的value 要插入的value
进行插入元素。before 会把要插入的元素插入到指定的value的前面;after会把要插入的元素插入到指定的value的后面。
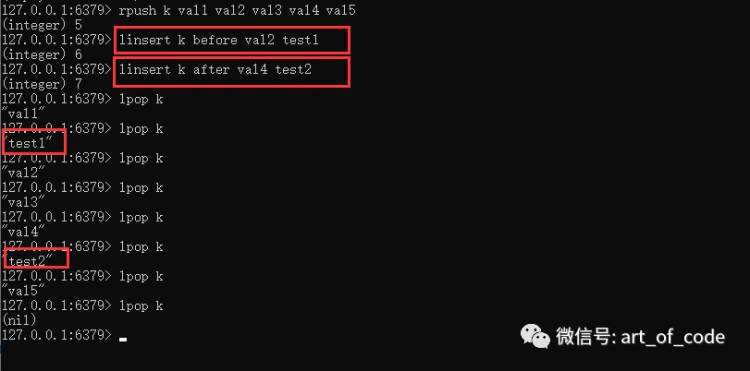
通过使用命令:lset key index 新的value
可以把列表指定的索引对应的值给替换掉。
可以通过命令:lindex key index
获取指定的索引的值,并且不会被舍弃。操作索引期间,需要注意时间复杂度,元素多的情况下慎用。
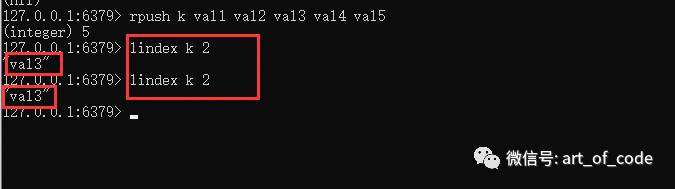
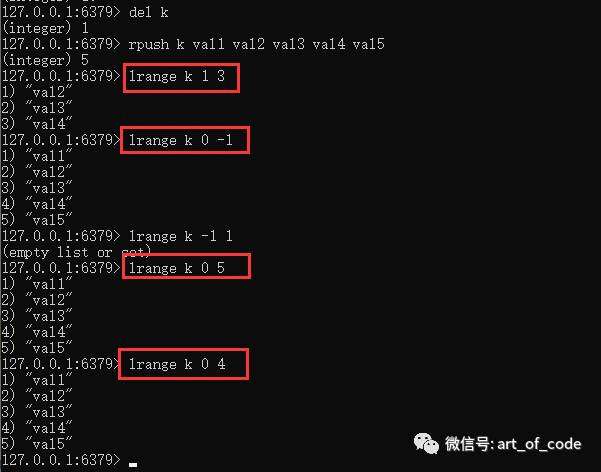
可以使用命令:lrange key 起始索引 结束索引
获取在索引区间的所有元素。元素包含起始索引和结束索引的值。
列表还可以用来当作消息队列使用,因为列表存取的一些方式,可以用来先进先出、先进后出等堆栈操作,先进先出与消息队列机制雷同。
哈希数据结构
哈希数据结构,可以当作是字典(key-value)里面嵌套了个字典(value数据类型又是一个 key-value的结构)。类似Json,或者类似俄罗斯套娃,例如:
person:{
“Name”:”wesky”,
“age”:18
}
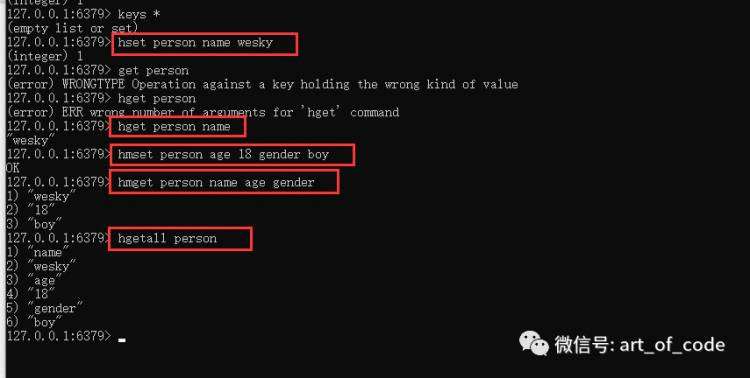
使用命令:hset key field value
可以设置哈希数据结构的key,以及一个属性和属性对应的值。
使用命令:hget key field
可以获取指定哈希数据的key对应的属性的值。
使用命令:hmset key field value field value ……
可以批量设置哈希数据指定key的多个属性和值。
使用命令:hmget key field1 field2 ……
可以批量获取指定的key下指定的多个属性的值。
使用命令:hgetall key
可以获取指定的哈希数据的key下的所有属性和值的列表。如下图所示。
使用命令:hkeys key
可以获取哈希数据指定key的所有属性名称的列表;
使用命令:hvals key
可以获取哈希数据指定key的所有属性的值的列表;
使用命令:hlen key
可以获取到哈希数据里面指定key的属性个数。

集合数据结构
集合结构也可以看成是一个没有属性值的哈希数据结构,并且属性不能重复且无序的。
类似于:
Person{
“name”,
“age”
}
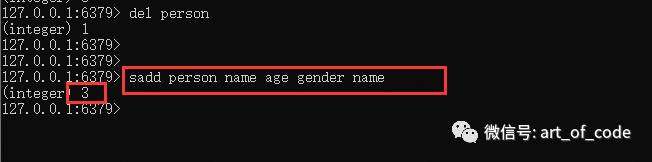
使用命令:sadd key field1 field2……
可以设置集合的key和元素集。由于集合是不可重复的,所以重复新增的元素会被自动剔除。
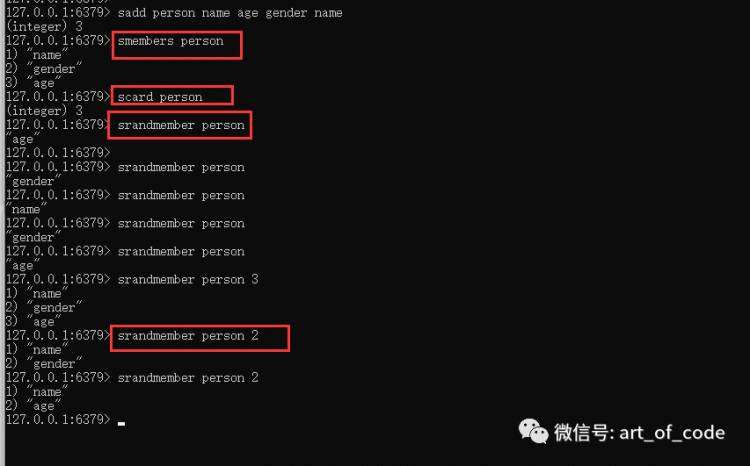
使用命令:smembers key
可以返回指定集合的所有元素;
使用命令:scard key
可以查询集合元素的个数;
使用命令:srandmember key (number:可选)
可以随机返回指定集合的一个或多个元素。不指定个数,即返回一个。
集合数据,可以进行一些集合运算操作。
命令:sdiff key1 key2
可以比较集合key1和集合key2的差集,差集结果为写在前面的集合元素减去后面集合的元素;
命令:sinter key1 key2
可以获取到集合key1和集合key2的交集。
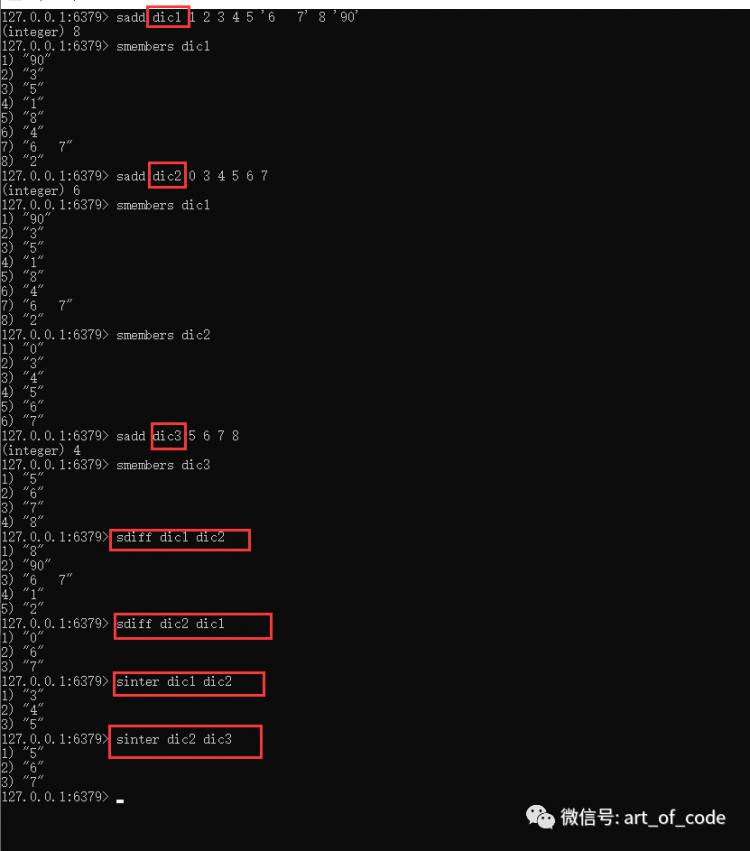
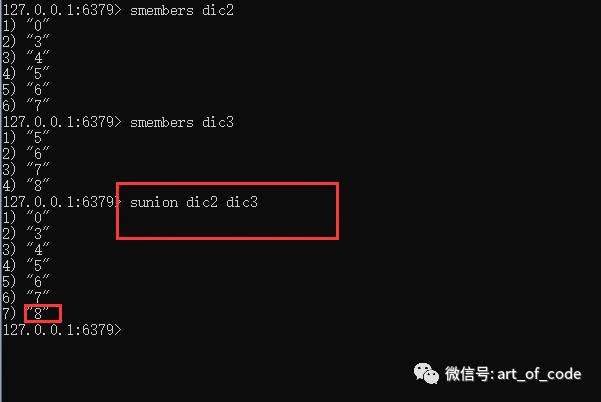
命令:sunion key1 key2
可以获取集合key1和集合key2的并集。
有序集合
有序集合比较常见的一个场景,是用来做排行榜。
命令:zadd key score1(分数,用于排行的值) member1(集合的元素) score2(分数,用于排行的值) member2(集合的元素) ……
可以用来新增有序集合。其中,分数代表权重,值越低,排越前。
命令:zrange key 起始索引 结束索引
可以查询指定集合索引区间的所有元素的属性。
命令:zincrby key 增加权重值 menber
可以对有序集合指定的元素进行增加权重(对分数进行增加指定的值)

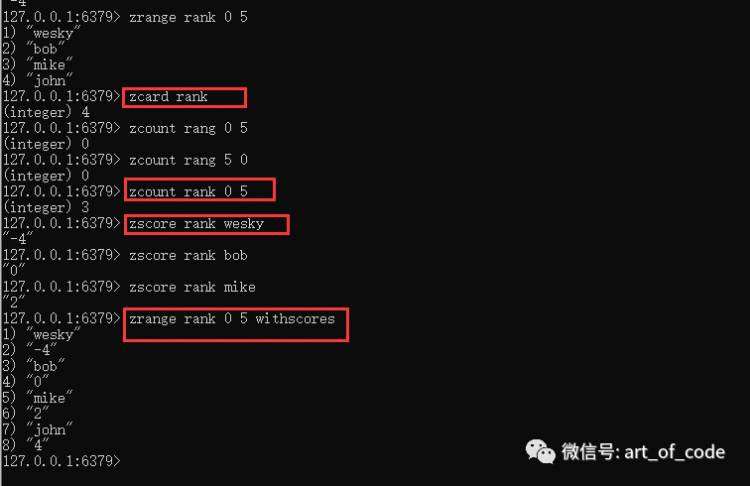
命令:zcard key
可以获取有序集合的个数;
命令:zcount key 最小分数 最大分数
可以获取到有序集合在指定的分数区间的所有元素;
命令:zcount key member
可以获取有序集合里面指定的元素当前的分数;
命令:zrange key 起始索引 结束索引 withscores
可以获取到有序索引里面指定的索引区间内所有的元素以及元素对应的分数。
备注:以上五种数据结构,都属于容器型,它们的特点是,当没有元素的时候,会被自动释放掉。
Redis分布式锁
Redis的操作是原子性的,如果存在多客户端同时操作的情况下,会发生一些干扰问题。原子性指的是,redis在进行读写期间是不会被打断的,会一直进行到底。下面用一个图片进行说明。
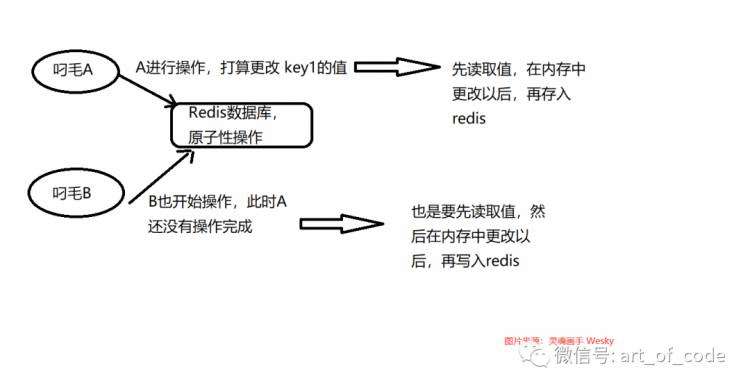
如上图所示,A和B同时都要操作Redis数据库里面的Key1。假设此刻Key1存储的是银行的存款,然后在A的地方消费掉了,此刻A触发了扣减余额的操作。这个时候,修改redis的值是通过先读取值出来到内存里面,然后进行扣减的;读取出来的时候,还没扣减完成,这个时候B(比如说是信用卡自动还款扣钱)也要扣减Key1的余额,也要进行先读取出来,然后才进行扣减。由于Redis是原子性操作,所以A的步骤不会被打断,B也不会被打断。这个时候,A扣减完成了,例如原本余额是100元,扣减了10元,A更改完毕以后,值变成了90元。此刻,B也要扣减,例如扣减20元,但是读取的是A改完之前的值,所以改完以后是80元。以上就产生了冲突,于是就有了Redis的分布式锁用来避免这个问题。
通过命令:set key value ex second nx
可以设置一个锁,key代表锁的名称,value是值;second是锁的超时时间。
如下图所示,我开了两个客户端,并且标注了我的操作顺序号。
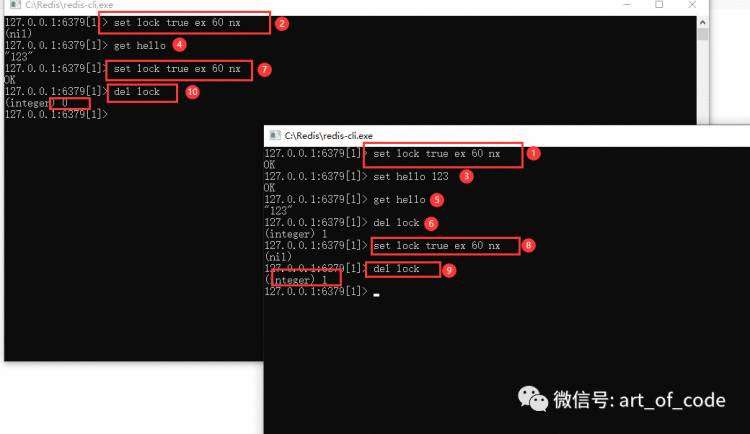
锁如果没有过期或删除,其他客户端创建锁会失败;但是其他客户端也可以删除锁,所以具有一定风险。建议可以对锁设置不同客户端所需要的不同的值用来区分。然后把需要操作的地方,放到锁里面操作,来避免产生的同时操作产生的问题。
例如伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | If(exists(lock)) { return false; // 存在锁,修改失败 } Else
{ Set lock true ex 5 nx; Set key1 100; del lock; Return true; // 修改成功 } |
Redis位图
位图的最小单位是bit,每个bit的值只能是0和1,位图的应用场景一般用于一些签到记录,例如打卡等。
场景举例: 例如某APP要存储用户的打卡记录,如果按照正常的思路来做,可能是用户每天是否打卡的记录都单独设置一个key-value键值对来存储,这样的话,每个用户每天都需要耗费一个键值对空间。而如果是位图,就可以很方便地通过位图来进行记录,例如如下图:

位图不算基础数据结构或者特殊数据结构,其本质上还是字符串。由于每个bit代表一个数据,所以还可以当作是bit数组来看待。
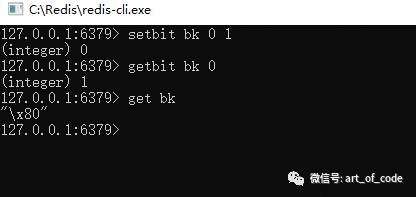
可以通过命令:
setbit key 偏移量(索引位) value(0/1,默认是0)
进行设置对应位置的位图数据。
通过命令:
getbit key 偏移量
可以获取到对应的位图索引数据。
也可以通过:
get key
来获取位图对应的字符串信息。
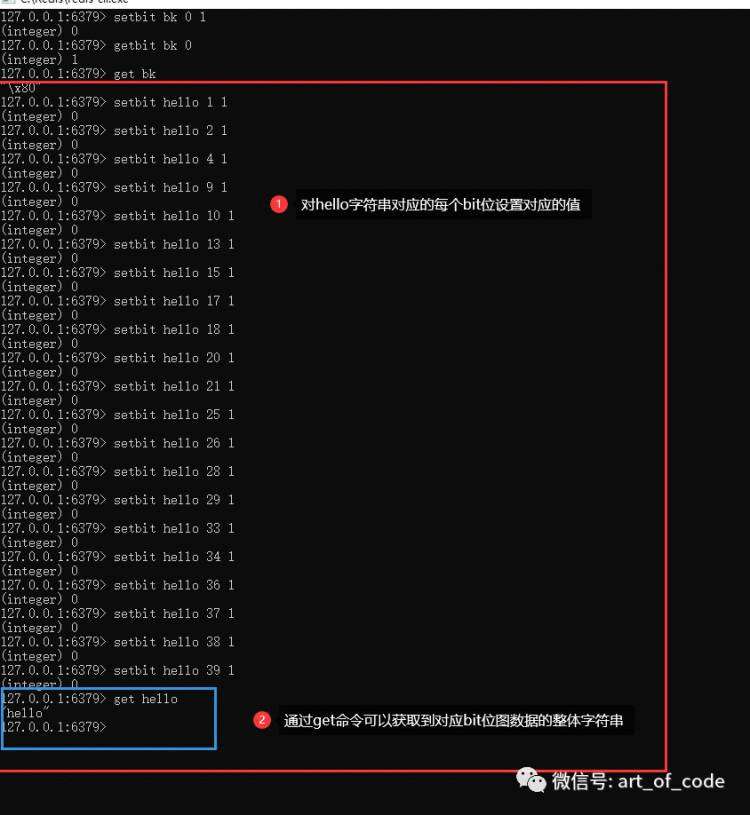
例如hello字符串的ascii码对应的二进制,分别是:
h: 01101000
e: 01100101
l: 01101100
l: 01101100
o: 01101111
以下设置字符串hello的位图操作,如图所示,字符串对应二进制数拼接起来的二进制,值为1所在的bit索引位(offset),使用:
setbit key offset 1
进行设置1即可。
setbit/gitbit 和 set/get 实际上是可以互相转换的,只是一种是操作bit位,一种是操作直接的值。同时可以互相交叉操作使用,例如setbit存储,get读取;set 存储,getbit读取等等。
可以通过命令: bitcount key 起始字符索引 结束字符索引
对指定key里面的数据,指定的字符索引区间内,获取到对应的位图数据是1的个数。如果不指定,则会获取到全部字符串对应位图的1的个数。如下图所示,结合以上二进制数据可知,h字符有3个1,o字符有6个1。
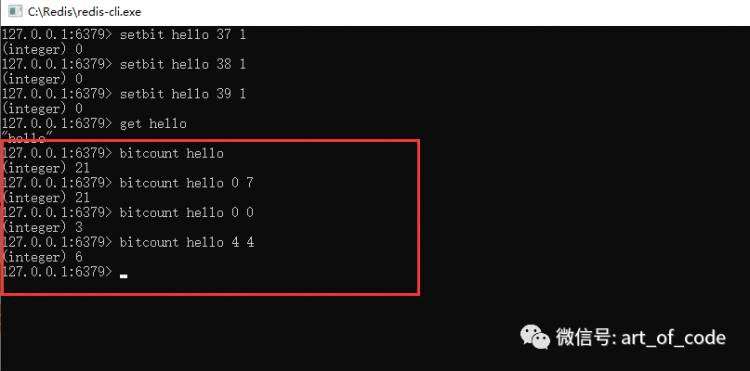
以上指令操作可以适用于在类似打卡天数统计上使用,可以快速统计出区间内为1的数据个数。
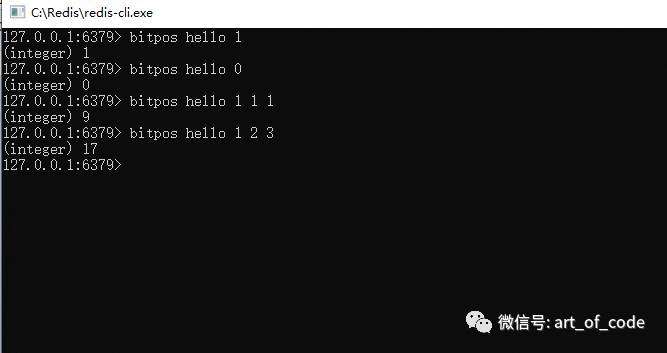
通过命令:bitops key bit值(0/1) 起始字符索引 结束字符索引
可以获取到指定的区间内,第一次出现指定的bit值(0或1)所在的位图索引。如果不指定区间,默认代表字符串全部区间。如下图所示,hello里面,第一次出现1是在位图的第一个索引位置;第一次出现0是在第0个位图索引位;字符索引位为1代表第二个字符,第一次出现的值为1的位图索引位置为9。
注意: 字符串的索引,0到N,0代表第一个字符,例如’h’。位图的索引,也是0到N,0代表位图上面第一个bit位,值为0或者1,例如h的位图索引位置是0的值是0 (01101000)
可以通过命令:
bitfield key get 类型 位图索引
来获取指定类型数据的ascii码。
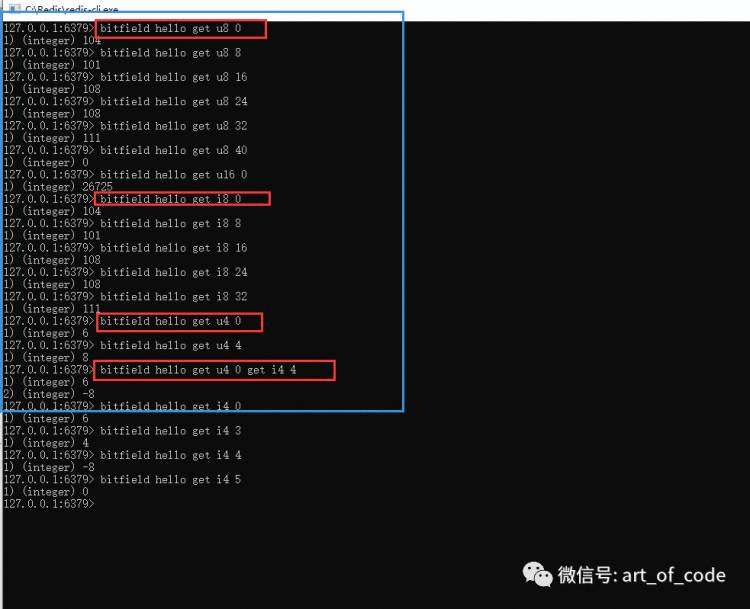
例如,以下截图中,命令:
bitfield hello get u8 0
其中,u8代表类型,u开头代表无符号数据,8代表获取8个bit位。如果是有符号的数据,是以i开头的。最后面的0,代表要获取的起始位图下标索引,此处是第0个索引。
hello五个字符,对应的ascii码分别为:104,101,108,108,111
如果以上命令的类型 u8 换成 u4 ,则获取到的值是0110,对应的值是6;以此类推。
也可以并列get获取,例如:
bitfield key get type1 offset1 type2 offset2 ……
其他玩法,大佬们可以自己尝试。我这边有关操作可以参考如下截图所示内容。
通过命令:
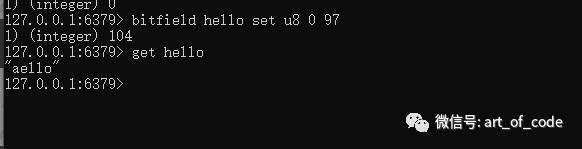
bitfield key set type 位图索引 ascii码
可以把对应的ascii码根据类型写入到指定的索引中,并且会返回原来索引被替换的ascii码值。
例如下图所示操作,位图索引从0开始,代表第一个字符h所在位置。97代表a的ascii码,执行以后,返回104(h的ascii码),并且通过get命令可以查看到字符串已经被替换了。
可以使用命令:
bitfield key incrby type 索引 自增值
对指定类型和索引区间的值进行累加 ,如下图所示。h通过 u8 类型自增1,即h+1=i
注意:对于累加的数据不能超出指定类型的最大值,例如 u4 最大值是15,累加到15以后会自动折返为0。
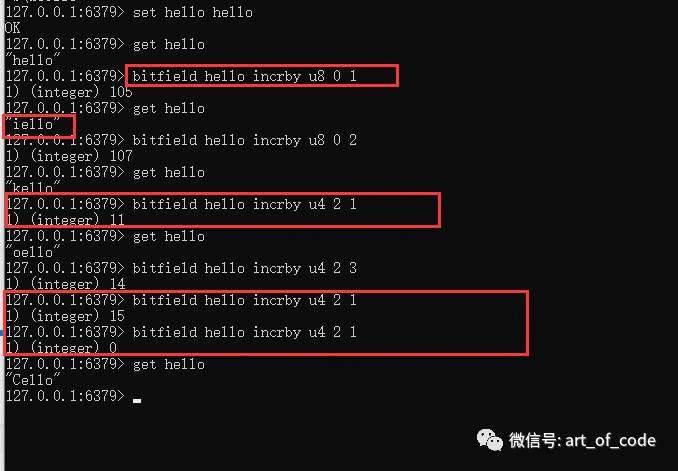
针对以上会出现折返的情况,可以使用溢出报错或者保持最大或最小值的方式来避免折返的情况。
使用命令:
Bitfield key overflow fail incrby type offset value
可以实现溢出的时候,会返回nil;
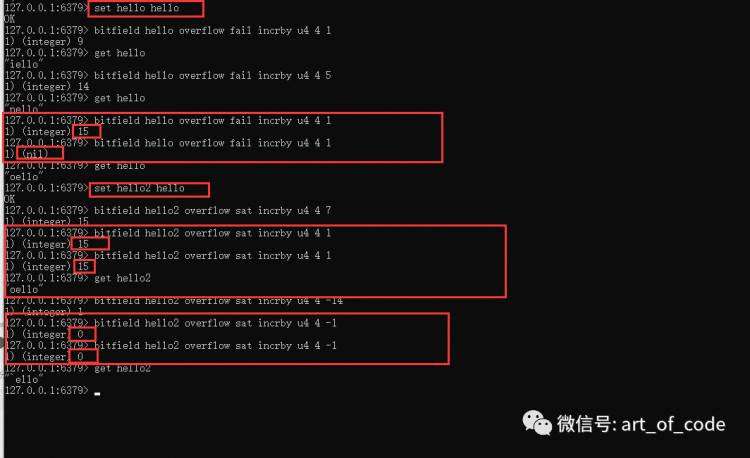
使用命令:
Bitfield key overflow sat incrby type offset value
可以实现当要溢出的时候,还是会返回当前的最大值或最小值。如下图所示。
HyperLogLog
HyperLogLog是一种可以快速去重的数据结构。但是有一定的误差率,大概在0.81%左右。应用场景一般是在需要针对一些大数据量的情况下进行去重计算大概的统计值使用,例如网站的PV量等等。
使用命令:
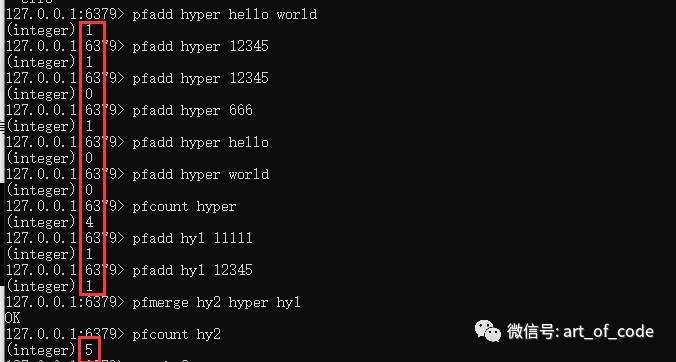
pfadd key value1 value2 ……
可以添加对应的多个数据集到指定的key里面去。
如果添加已经存在的数据,会被自动去重。
使用命令:pfcount key
可以统计数据集的个数。
使用命令:pfmerge 目标key 源key1 源key2 ……
可以对多个不同的key进行数据合并,并且数据集重复的会自动排重。
使用HyperLogLog的用途,是在针对大数据量的情况下,在允许一定的容错率的情况下,用它可以节约资源并且快速地进行排重。例如使用set来设置数据,资源损耗肯定是巨大的;但是使用hyperloglog来处理,资源损耗是固定的12kb,可以处理的数据量大约是2^64个数据。
冷门科普:命令是pf开头,是为了纪念HyperLogLog的作者——Philippe Flajolet
布隆过滤器
布隆过滤器,最常见的场景是商品推荐业务。例如购物时候浏览的信息被记录以后,可以进行推荐其他同类型的其他商品。推荐的其他商品不会和浏览过的商品重复(去重),但是也存在一定的误差。
布隆过滤器源码地址链接:
https://github.com/RedisBloom/RedisBloom
先进行下载,下载方式可以按照自己喜欢的方式下载。例如此处我下载到d目录下的wesky/bloom文件夹下。
然后进入到文件夹内,使用make命令进行编译。编译成功的话,会产生一个 redisbloom.so的文件。如下,我也很尴尬,没成功,就暂且到这里吧。
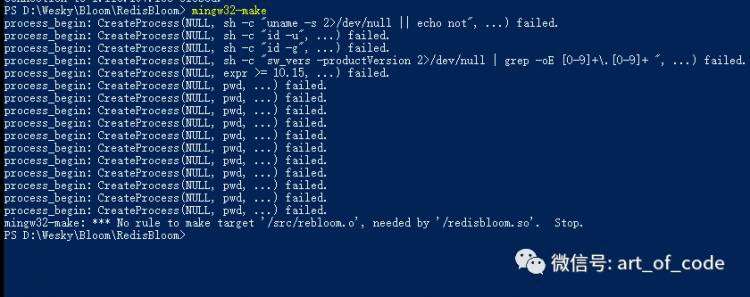
假如上面配置成功的话,启动redis服务的时候,可以把.so文件配置到redis.conf配置文件下,例如我上面所在的位置,新增的样式如下:
loadmodule D:/Wesky/Bloom/RedisBloom/redisbloom.so
或者使用命令启动的时候,使用命令进行指定:
redis-server --loadmodule D:/Wesky/Bloom/RedisBloom/redisbloom.so
由于当前我本机无法编译布隆过滤器源码,所以就暂且到这吧,请见谅。
布隆过滤器下,会有一些命令,供参考,大家可以根据自己情况,进行自己尝试,当作是留个悬念了。
命令:
bf.add key xxx
bf.madd key 数据1 数据2 ……
bf.exists key 数据
bf.mexists key 数据1 数据2 ……
……







 京公网安备 11010802041100号
京公网安备 11010802041100号