作者:zeng-abee | 来源:互联网 | 2023-07-31 17:12
本文转载自经管之家论坛, R语言中的Softmax Regression建模 (MNIST 手写体识别和文档多分类应用)
R中的softmaxreg包,发自2016-09-09,链接:https://cran.r-project.org/web/packages/softmaxreg/index.html
——————————————————————————————————————————————————————————————————
一、介绍
Softmax Regression模型本质还是一个多分类模型,对Logistic Regression 逻辑回归的拓展。如果将Softmax Regression模型和神经网络隐含层结合起来,可以进一步提升模型的性能,构成包含多个隐含层和最后一个Softmax层的多层神经网络模型。之前发现R里面没有特别适合的方法支持多层的Softmax 模型,于是就想直接用R语言写一个softmaxreg 包。可以支持大部分的多分类问题,其中的两个示例:MNIST手写体识别和多文档分类(Multi-Class DocumentClassification) 的文档如下
二、示例文档
2.1 MNIST手写体识别数据集
MNIST手写体识别的数据集是图像识别领域一个基本数据集,很多模型诸如CNN卷积神经网络等模型都经常在这个数据集上测试都能够达到97%以上的准确率。 这里想比较一下包含隐含层的softmaxreg模型,测试结果显示模型的准确率能达到93% 左右。
Part1、下载和Load数据
MNIST手写体识别的数据集可以直接从网站下载http://yann.lecun.com/exdb/mnist/,一共四个文件,分别下载下来并解压。文件格式比较特殊,可以用softmaxreg 包中的load_image_file 和load_label_file 两个函数读取。
训练集有60000幅图片,每个图片都是由16*16个像素构成,代表了0-9中的某一个数字,比如下图。
利用softmaxreg 包训练一个10分类的MNIST手写体识别的模型,用load_image_file 和load_label_file 来分别读取训练集的图像数据和标签的数据 (Reference: brendano'connor - gist.github.com/39760的读取方法)
- library(softmaxreg)
- path= "D: \\DeepLearning\\MNIST\\"
- #10-classclassification, Digit 0-9
- x= load_image_file(paste(path,'train-images-idx3-ubyte', sep=""))
- y= load_label_file(paste(path,'train-labels-idx1-ubyte', sep=""))
- xTest= load_image_file(paste(path,'t10k-images-idx3-ubyte',sep=""))
- yTest= load_label_file(paste(path,'t10k-labels-idx1-ubyte', sep=""))
可以用show_digit函数来看一个数字的图像,比如查看某一个图片,比如第2副
Part2、训练模型
利用softmaxReg函数,训练集输入和标签分别为为x和y,maxit 设置最多多少个Epoch, algorithm为优化的算法,rate为学习率,batch参数为SGD随机梯度下降每个Mini-Batch的样本个数。 收敛后用predict方法来看看测试集Test的准确率怎么样
- ## Normalize Input Data
- x = x/255
- xTest = xTest/255
- model1= softmaxReg(x, y, hidden = c(), funName = 'sigmoid', maxit = 15, rang = 0.1,type = "class", algorithm = "sgd", rate = 0.01, batch = 1000)
- loss1= model1$loss
- #Test Accuracy
- yFit= predict(model1, newdata = x)
- table(y,yFit)
Part3、比较不同优化算法的收敛速度
- model2= softmaxReg(x, y, hidden = c(), funName = 'sigmoid', maxit = 15, rang = 0.1,type = "class", algorithm = "adagrad", rate = 0.01, batch =1000)
- loss2= model2$loss
- model3= softmaxReg(x, y, hidden = c(), funName = 'sigmoid', maxit = 15, rang = 0.1,type = "class", algorithm = "rmsprop", rate = 0.01, batch =1000)
- loss3= model3$loss
- model4= softmaxReg(x, y, hidden = c(), funName = 'sigmoid', maxit = 15, rang = 0.1,type = "class", algorithm = "momentum", rate = 0.01, batch= 1000)
- loss4= model4$loss
- model5= softmaxReg(x, y, hidden = c(), funName = 'sigmoid', maxit = 15, rang = 0.1,type = "class", algorithm = "nag", rate = 0.01, batch = 1000)
- loss5= model5$loss
- #plot the loss convergence
- iteration= c(1:length(loss1))
- myplot= plot(iteration, loss1, xlab = "iteration", ylab = "loss",ylim = c(0, max(loss1,loss2,loss3,loss4,loss5) + 0.01),
- type = "p", col ="black", cex = 0.7)
- title("ConvergenceComparision Between Learning Algorithms")
- points(iteration,loss2, col = "red", pch = 2, cex = 0.7)
- points(iteration,loss3, col = "blue", pch = 3, cex = 0.7)
- points(iteration,loss4, col = "green", pch = 4, cex = 0.7)
- points(iteration,loss5, col = "magenta", pch = 5, cex = 0.7)
- legend("topright",c("SGD", "Adagrad", "RMSprop","Momentum", "NAG"),
- col = c("black", "red","blue", "green", "magenta"),pch = c(1,2,3,4,5))
- save.image()
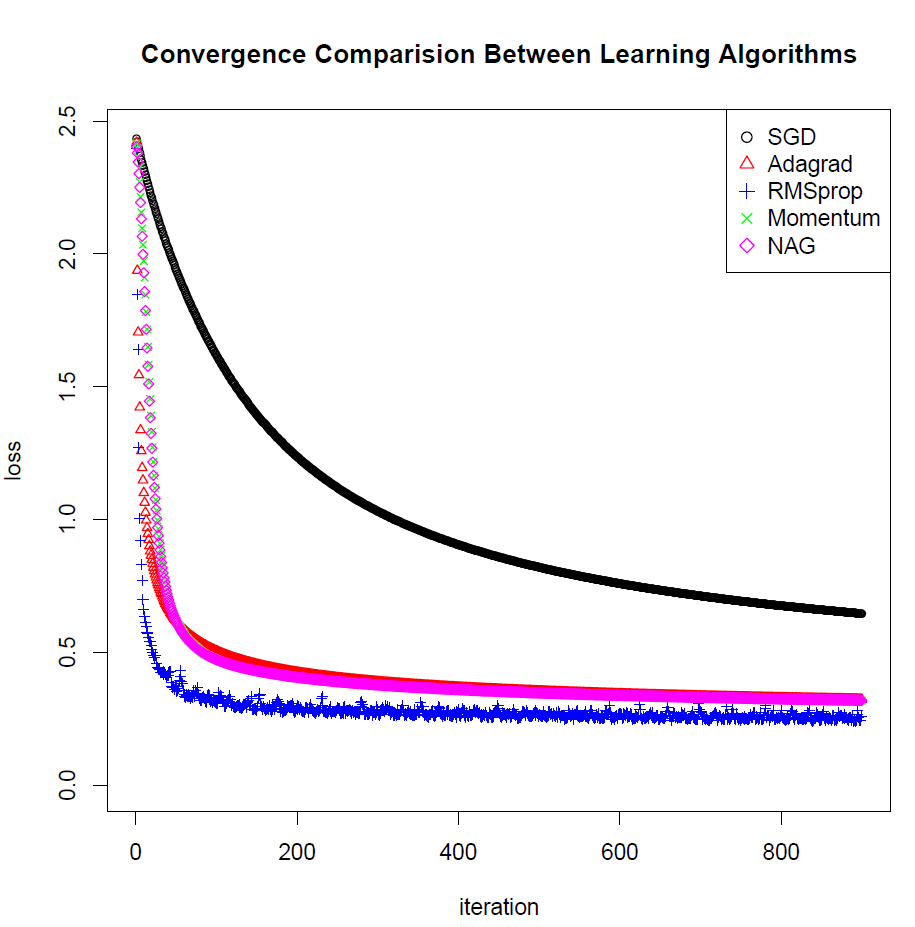
如果maxit 迭代次数过大,模型运行时间较长,可以保存图像,最后可以看到AdaGrad, rmsprop,momentum, nag 和标准SGD这几种优化算法的收敛速度的比较效果。关于优化算法这个帖子有很好的总结:
http://cs231n.github.io/neural-networks-3/
2.2 多类别的文档分类
Softmax regression模型的每个输入为一个文档,用一个字符串表示。其中每个词word都可以用一个word2vec模型训练的word Embedding低维度的实数词向量表示。在softmaxreg包中有一个预先训练好的模型:长度为20维的英文词向量的字典,直接用data(word2vec) 调用就可以了。
假设我们需要对UCI的C50新闻数据集进行分类,数据集包含多个作者写的新闻报道,每个作者的新闻文件都在一个单独的文件夹中。 我们假设挑选5个作者的文章进行训练softmax regression 模型,然后在测试集中预测任意文档属于哪一个作者,这就构成了一个5分类的问题。
Part1, 载入预先训练好的 英文word2vec 字典表
- library(softmaxreg)
- data(word2vec) # default 20 dimension word2vec dataset
- #### Reuter 50 DataSet UCI Archived Dataset from
Part2,利用loadURLData函数从网址下载数据并且解压到folder目录
- ## URL: "http://archive.ics.uci.edu/ml/machine-learning-databases/00217/C50.zip"
- URL = "http://archive.ics.uci.edu/ml/machine-learning-databases/00217/C50.zip"
- folder = getwd()
- loadURLData(URL, folder, unzip = TRUE)
Part3,利用wordEmbed() 函数作为lookup table,从默认的word2vec数据集中查找每个单词的向量表示,默认20维度,可以自己训练自己的字典数据集来替换。
- ##Training Data
- subFoler = c('AaronPressman', 'AlanCrosby', 'AlexanderSmith', 'BenjaminKangLim', 'BernardHickey')
- docTrain = document(path = paste(folder, "/C50train/",subFoler, sep = ""), pattern = 'txt')
- xTrain = wordEmbed(docTrain, dictionary = word2vec)
- yTrain = c(rep(1,50), rep(2,50), rep(3,50), rep(4,50), rep(5,50))
- # Assign labels to 5 different authors
- ##Testing Data
- docTest = document(path = paste(folder, "/C50test/",subFoler, sep = ""), pattern = 'txt')
- xTest = wordEmbed(docTest, dictionary = word2vec)
- yTest = c(rep(1,50), rep(2,50), rep(3,50), rep(4,50), rep(5,50))
- samp = sample(250, 50)
- xTest = xTest[samp,]
- yTest = yTest[samp]
Part4,训练模型,构建一个结构为20-10-5的模型,输入层为20维,即词向量的维度,隐含层的节点数为10,最后softmax层输出节点个数为5.
- ## Train Softmax Classification Model, 20-10-5
- softmax_model = softmaxReg(xTrain, yTrain, hidden = c(10), maxit = 500, type = "class",
- algorithm = "nag", rate = 0.05, batch = 10, L2 = TRUE)
- summary(softmax_model)
- yFit = predict(softmax_model, newdata = xTrain)
- table(yTrain, yFit)
- ## Testing
- yPred = predict(softmax_model, newdata = xTest)
- table(yTest, yPred)
关于Stanford的中英文
http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
softmaxregR包的下载地址:
https://cran.r-project.org/web/packages/softmaxreg/index.html






![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)




 京公网安备 11010802041100号
京公网安备 11010802041100号