多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3. 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
4. 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍
Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
主线程等待子线程结束
同样是 join方法
无论是进程还是线程,都是:守护xxx会等待主xxx完毕后被销毁
主进程与主线程在什么情况下才算运行完毕
#1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收)。主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,#2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。主线程的结束意味着进程的结束,进程整体的资源都被回收,因而主线程必须在其余非守护线程都运行完毕后才能结束
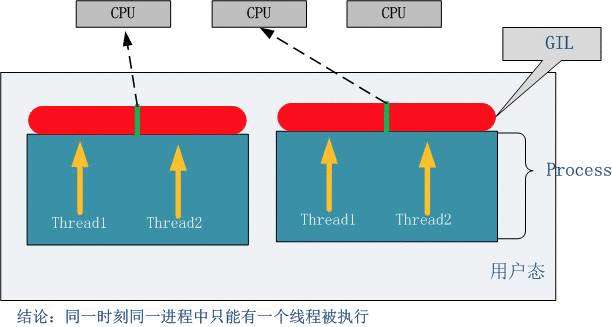
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
GIL
GIL VS Lock
机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限
线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果
既然是串行,那我们执行
t1.start()
t1.join
t2.start()
t2.join()
这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
import threadingR=threading.Lock()R.acquire()'''对公共数据的操作'''R.release()
分析: #1.100个线程去抢GIL锁,即抢执行权限 #2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire() #3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL #4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程




 京公网安备 11010802041100号
京公网安备 11010802041100号