作者:飞轶尘埃_130 | 来源:互联网 | 2023-09-10 16:42
之前我们爬取的实习僧、糗事百科、网易新闻都是不需要登陆,不需要你去做账号、Cookies、Session等等,顶多只需要一个headers(请求头),但还有一类是需要:你(注册)账
 摘要: 之前我们爬取的实习僧、糗事百科、网易新闻都是不需要登陆,不需要你去做账号、COOKIEs、Session等等,顶多只需要一个 headers (请求头),但还有一类是需要:你(注册)账号登陆才能进行后续的操作。
摘要: 之前我们爬取的实习僧、糗事百科、网易新闻都是不需要登陆,不需要你去做账号、COOKIEs、Session等等,顶多只需要一个 headers (请求头),但还有一类是需要:你(注册)账号登陆才能进行后续的操作。
例如:淘宝、知乎、豆瓣之类的需要你登陆的。
我们之前又整合一些 requests 库 提供 http 的所有基本请求方式:

回顾:
1.GET请求
可利用params参数

输出结果:
 2.POST请求
2.POST请求
利用data参数 为POST添加参数:

上传文件的方式:
方法一:

方法二:
我个人更习惯或者说更 Python 的操作,是方法二:

步入正题:
个人目前知道有以下几种操作方法:
POST 请求方法:需要在后台获取登录的 URL并填写请求体参数,然后 POST 请求登录,相对麻烦;
添加 COOKIEs 方法:先登录然后,将获取到的 COOKIEs 加入 Headers 中,最后用 GET 方法请求登录,这种最为方便;(个人比较喜欢这个方法)
Selenium 模拟登录:代替手工操作,自动完成账号和密码的输入,简单但速度比较慢。
下面用代码分别实现这三种方法。
1. 目标网页
这是我们要爬取的目标网页:
URL:https://www.itjuzi.com/investevent
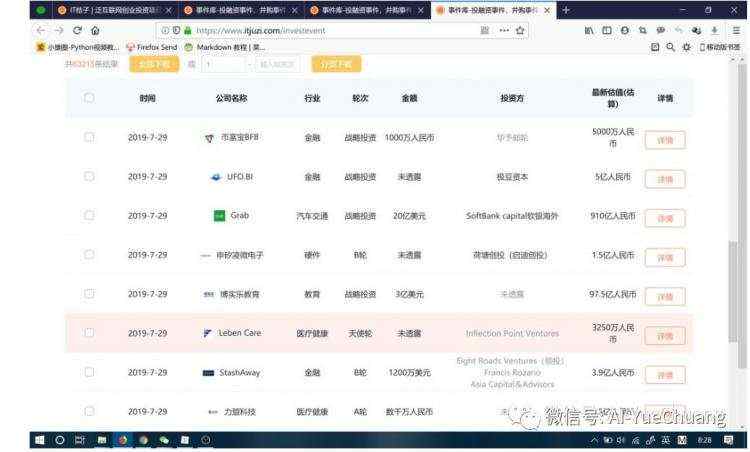
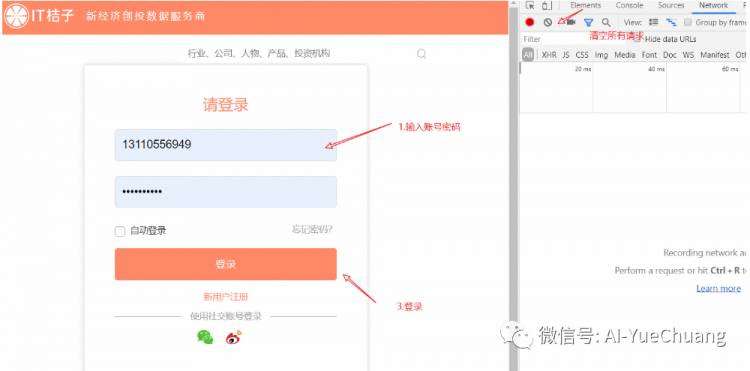
该网页需要先登录才能看到数据信息,登录界面如下:
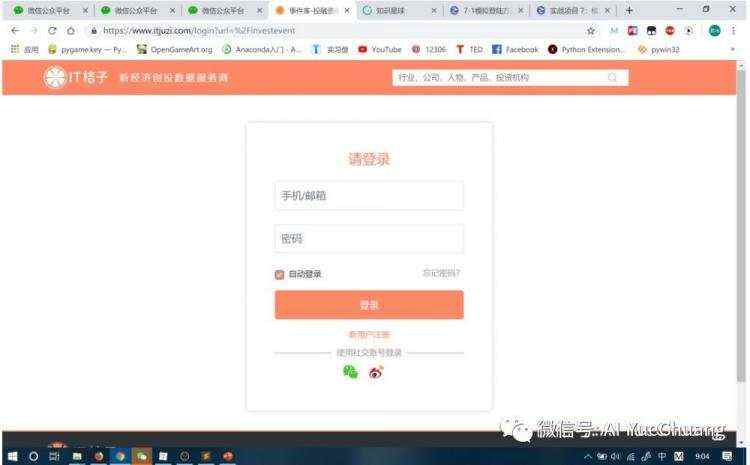
可以看到,只需要输入账号和密码就可以登录,不用输验证码,比较简单。下面利用我个人的账号实现,来实现模拟登录。
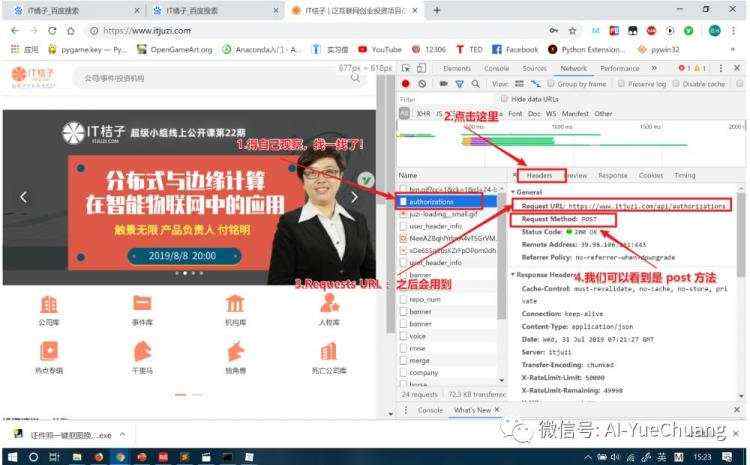
首先,我们要找到 POST 请求的 URL。
有两种方法,第一种是在直接右键在开发者工具中查看(在浏览器当中按 :F12 ),第二种是在 Fiddler 软件中查看。
我们在调出开发者工具的时候,如果把控制台放在地下,会出现如下测试了火狐浏览器和谷歌浏览皆为如此:
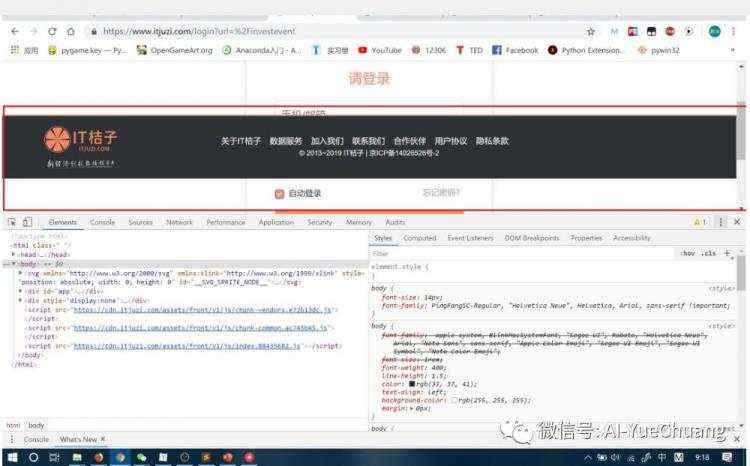
所以,需要把开发者工具放在别的方向,例如:
先说第一种方法。
在登录界面输入账号密码;
并打开开发者工具,清空所有请求;
接着点击登录按钮,这时便会看到有大量请求产生
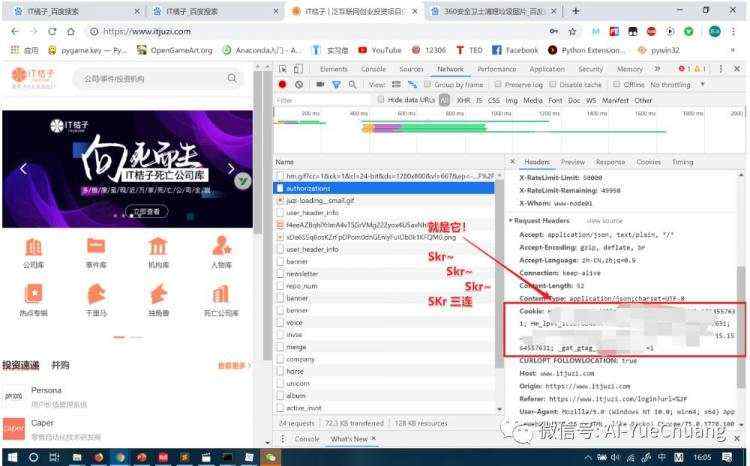
这个需要一点经验,因为是登录,所以可以尝试点击带有 「login」字眼的请求。可是,之后我们会发现,IT橘子里面似乎找不到 [login] 字眼,但可以找到 POST 请求。
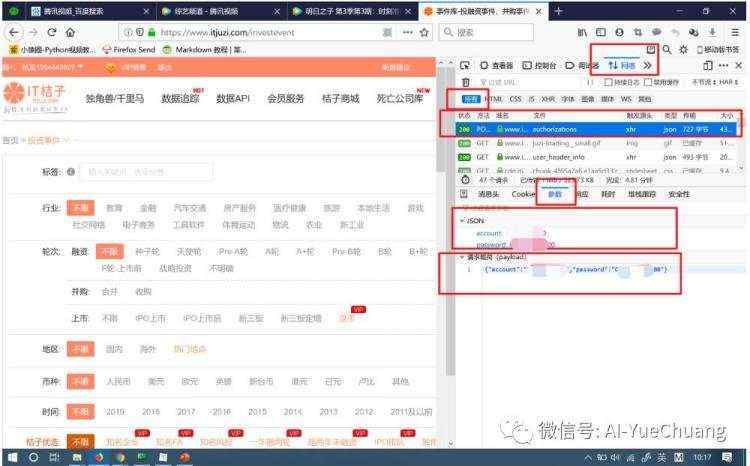
这里我选择其中的POST类型的请求,在右侧 Headers 中可以看到请求的 URL,请求方式是 POST类型,说明 URL 找对了。
这里我用的是火狐和谷歌浏览器:
火狐:
谷歌:
接着,我们下拉到 Requests Payload
注意:
每个网站有点不太一样,有一些是:*** Form Data***

2.包括 identify 和 password
这里有几个参数,包括 account 和 password,这两个参数正是我们登录时需要输入的账号和密码,也就是 POST 请求需要携带的参数。
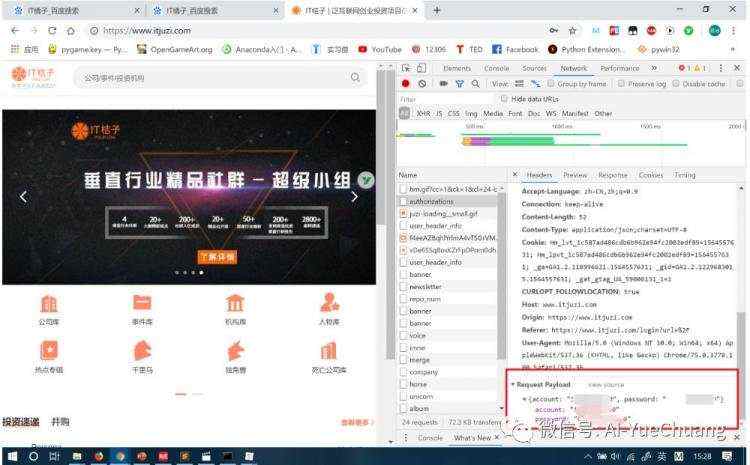
参数构造非常简单,接下来只需要利用 Requests.post 方法请求登录网站,然后就可以爬取内容了。
当然,我们还能用 Fiddler 获取 POST 请求。这里不做详细示例,如果有兴趣,后台留言:Fiddler文章,之后会专门分享给大家,看大家的热情啦嘿嘿~
简单介绍:
Fiddler 是位于客户端和服务器端的 HTTP 代理,也是目前最常用的 HTTP 抓包工具之一 。它能够记录客户端和服务器之间的所有 HTTP 请求,可以针对特定的 HTTP 请求,分析请求数据、设置断点、调试 web 应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 web 调试的利器。
Fiddler 下载地址:
https://www.telerik.com/download/fiddler
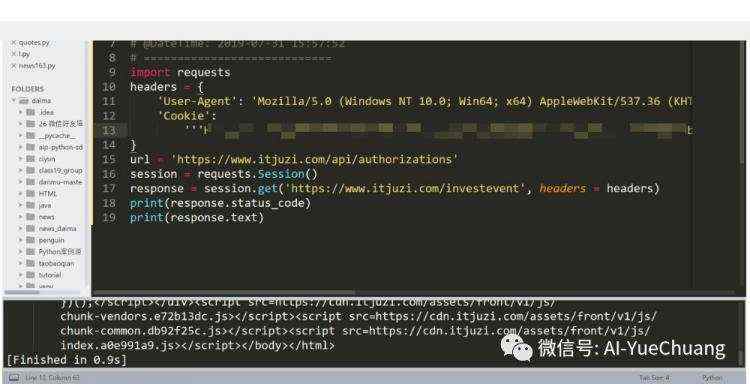
获取到 Request URL 和请求体参数 Requests Payload 之后,下面就可以开始用 Requests.post 方法模拟登录了。
代码如下:
# ============================
# -*8 coding: utf-8 -*-
# @Author: 黄家宝
# @Corporation: AI悦创
# @Version: 1.0
# @Function: 功能
# @DateTime: 2019-07-31 15:57:52
# ============================
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
data = {
"account":"你刚刚查到的账号",
"password":"你的密码"
}
url ='https://www.itjuzi.com/api/authorizations'
session = requests.Session()
session.post(url, headers = headers, data = data)
# 登录后,我们需要获取另一个网页中的内容
respOnse= session.get('https://www.itjuzi.com/investevent',headers = headers)
print(response.status_code)
print(response.text)
使用 session.post 方法提交登录请求,然后用 session.get 方法请求目标网页,并输出 HTML代码。可以看到,成功获取到了网页内容。
上面一种方法,我们需要去后台获取 POST 请求链接和参数,还要在众多的请求当中去找,比较麻烦。
下面,我们可以尝试先登录,获取 COOKIE,然后将该 COOKIE 添加到 Headers 中去,然后用 GET 方法请求即可,过程简单很多。
首先,需要先了解两个知识点:Session 和 COOKIEs。
Session 在服务端,也就是网站的服务器,用来保存用户的会话信息;
COOKIEs 在客户端,也可以理解为浏览器端,有了 COOKIEs,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 COOKIEs 并鉴定出是哪个用户,然后再判断用户是否是登录状态,然后返回对应的 Response。
所以我们可以理解为 COOKIEs 里面保存了登录的凭证,有了它我们只需要在下次请求携带 COOKIEs 发送 Request 而不必重新输入用户名、密码等信息重新登录了。因此在爬虫中,有时候处理需要登录才能访问的页面时,我们一般会直接将登录成功后获取的 COOKIEs 放在 Request Headers 里面直接请求。
假如你用过 360安全卫士清理软件、或者其他清理软件:火绒(我用的是火绒)在清理垃圾的时候你会发现其中有一项垃圾是:清理COOKIEs(图片来源网络)

当然你也可以在浏览器当中清理数据时可以看见:
可见,COOKIEs 是在本地的;
浏览器当中 COOKIEs:
 代码如下:
代码如下:
# ============================
# -*8 coding: utf-8 -*-
# @Author: 黄家宝
# @Corporation: AI悦创
# @Version: 1.0
# @Function: 功能
# @DateTime: 2019-07-31 15:57:52
# ============================
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'COOKIE': '你的COOKIE',
}
url = 'https://www.itjuzi.com/api/authorizations'
session = requests.Session()
respOnse= session.get('https://www.itjuzi.com/investevent', headers = headers)
print(response.status_code)
print(response.text)
可以看到,添加了 COOKIE 后就不用再 POST 请求了,直接 GET 请求目标网页即可。可以看到,也能成功获取到网页内容。
这个方法很直接,利用 Selenium 代替手动方法去自动输入账号密码然后登录就行了。
因为本文过长,Selenium 部分将在另一篇推文展现,可以直接在公众号后台回复关键词:Selenium模拟登陆
来源:AI悦创
封图来源:网络
投稿邮箱:cleland2018@gmail.com
1374284093@qq.com
本期编辑:AI悦创、陈不成
那么,今天的AI悦创小课堂就到这里了,各位小朋友你们学会了吗?
我是AI悦创,依然不会定时给你们分享一些有趣好玩实用的东西,欢迎关注~
警察蜀黍!就是这个人!脑子简直有泡!还不赶紧关注一下!







![微信商户扫码支付 java开发 [从零开发]](https://img8.php1.cn/3cdc5/1ea6b/a6e/077c0283247408a9.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号