作者:176精品传奇双线 | 来源:互联网 | 2023-09-09 11:40
一、前言 做大数据分析及应用过程中,时常需要面对海量的数据存储及计算,传统的服务器已经很难再满足一些运算需求,基于hadoopspark的大数据处理平台得到广泛的应用。本文介
一、前言
做大数据分析及应用过程中,时常需要面对海量的数据存储及计算,传统的服务器已经很难再满足一些运算需求,基于hadoop/spark的大数据处理平台得到广泛的应用。本文介绍用python读取hive数据库的方式,其中还是存在一些坑,这里我也把自己遇到的进行分享交流。
基本情况
集团有20台服务器(其中1台采集主节点,1台大数据监控平台,1台集群主节点,17台集群节点),65THDFS的磁盘资源,3.5T的yarn内存,等等。项目目前需要对集团的家庭画像数据分析,通过其楼盘,收视节目偏好,家庭收入等数据进行区域性的分析;同时对节目画像及楼盘详细数据进行判断分析。本人习惯使用R语言和Python来分析,故采用了本次分享的数据获取部分的想法。
二、Python连接hive
1、pyhive方式连接hive数据库
首先是配置相关的环境及使用的库。sasl、thrift、thrift_sasl、pyhive。
其中sasl是采用0.2.1版本的,选择适合自己的即可。下载网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#sasl
pip install sasl-0.2.1-cp36-cp36m-win_amd64.whl
pip install thrift -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install thrift_sasl==0.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyhive -i https://pypi.tuna.tsinghua.edu.cn/simple
下载好相关库后,我们直接上代码。
from pyhive import hive
import pandas as pd
# 读取数据
def select_pyhive(sql):
# 创建hive连接
cOnn= hive.Connection(host='10.16.15.2', port=10000, username='hive', database='user')
cur = conn.cursor()
try:
#c = cur.fetchall()
df = pd.read_sql(sql, conn)
return df
finally:
if conn:
conn.close()
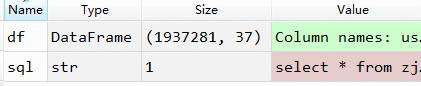
sql = "select * from user_huaxiang_wide_table"
df = select_pyhive(sql)
获取到hive数据库中约193W的家庭画像数据,37个字段。

可以看出代码并不是很复杂,但是大家在测试时可能会出现以下两种常见的问题。
问题一:
‘TSaslClientTransport’ object has no attribute ‘readAll’
解决一:
pip install thrift_sasl==0.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple,更新依赖thrift_sasl包到0.3.0即可
问题二:Could not start SASL: Error in sasl_client_start (-4) SASL(-4)
解决二:
1.寻找到sasl的安装位置,一般来说是如下位置:
C:\Users\你计算机的用户名字\AppData\Local\Programs\Python\Python37-32\Lib\site-packages\sasl\sasl2
2. C盘新建文件夹 C:\CMU\bin\sasl2
3. 将第一步中的saslPLAIN.dll拷贝至第二步新建的文件夹中
2、impala方式连接hive数据库
impala方式连接hive数据库,但是数据量过大会导致python卡死,目前还未找到合适方式解决。
首先是配置相关的环境及使用的库。sasl、thrift、thrift_sasl、impala。
其中sasl是采用0.2.1版本的,选择适合自己的即可。下载网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#sasl
pip install sasl-0.2.1-cp36-cp36m-win_amd64.whl
pip install thrift -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install thrift_sasl==0.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install impala -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install thriftpy -i https://pypi.tuna.tsinghua.edu.cn/simple
下载好相关库后,我们直接上代码。
from impala.dbapi import connect
from impala.util import as_pandas
import pandas as pd
# 获取数据
def select_hive(sql):
# 创建hive连接
cOnn= connect(host='10.16.15.2', port=10000, auth_mechanism='PLAIN',user='hive', password='user@123', database='user')
cur = conn.cursor()
try:
#cur.execute(sql)
c = cur.fetchall()
df = as_pandas(cur)
return df
finally:
if conn:
conn.close()
data = select_hive(sql = 'select * from user_huaxiang_wide_table limit 100')
这个impala方式也是很方便,但是当数据量到达一定程度,则就会在fetchall处一直处于运行状态,几个小时也没有响应。
文章未经博主同意,禁止转载!







 京公网安备 11010802041100号
京公网安备 11010802041100号