
欢迎来到 Python 进阶课程的第四部分——Pandas 高级应用。本系列课程包括 NumPy 和 Pandas 的上下两部分,旨在深化您的 Python 编程技能。以下是本系列的课程大纲:
- NumPy 基础
- NumPy 高级功能
- Pandas 基础
- Pandas 高级应用
在此之前,我们已经完成了基础版的 11 节课程,涵盖了 Python 编程的核心概念和技术,包括但不限于编程基础、数据类型、控制结构、函数设计、面向对象编程、字符串操作、表达式解析、迭代器与生成器以及装饰器等。
本课程将重点探讨如何利用 Pandas 进行高效的数据分析、可视化和预处理:
数据分析
Pandas 是数据科学家手中不可或缺的利器,它提供了强大的数据操作功能。我们将从以下几个方面深入学习 Pandas 的数据分析能力:
- 单变量分析:通过聚合函数对单一特征进行统计分析。
- 多变量分组分析:基于一个或多个特征进行分组,并对各组内的其他特征进行统计。
- 多变量透视分析:利用透视表技术,根据多个维度对数据进行复杂聚合。
- 多变量交叉分析:通过交叉表技术,实现特定维度上的数据聚合与比较。
通过示意图,我们可以直观地理解透视表(pivot_table)和交叉表(crosstab)的工作原理:
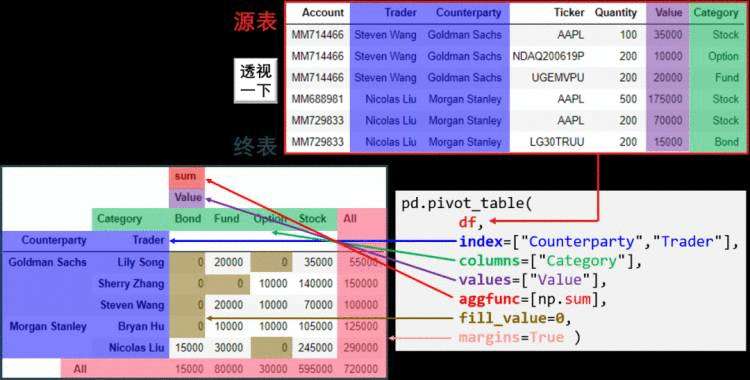
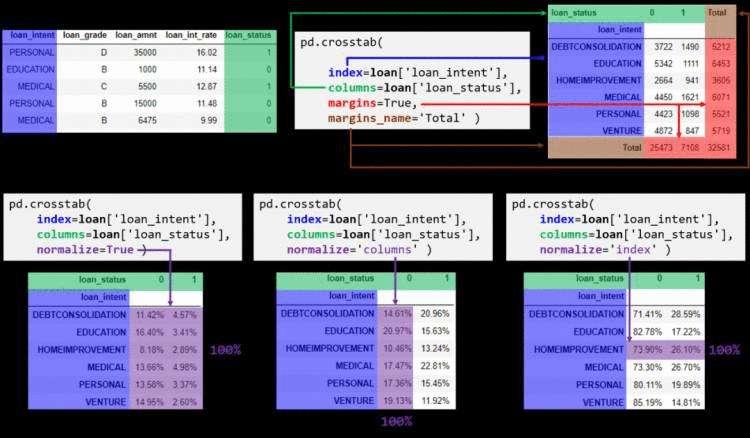
数据可视化
数据可视化是数据科学的重要组成部分。虽然 matplotlib 和 seaborn 是常用的绘图库,但 Pandas 自身也提供了简便的绘图方法,如 Series.plot() 和 DataFrame.plot(),能够快速生成基本图表。这些图表虽然简单,但足以揭示数据的关键特征。对于更复杂的图形需求,我们还可以结合 matplotlib、seaborn 以及其他高级可视化工具如 bokeh、plotly、pyecharts 和 altair 来实现。
数据预处理
数据预处理是数据分析前必不可少的步骤。在实际工作中,原始数据往往存在各种问题,需要通过数据清洗和转换来提高数据质量。本课程将介绍如何使用 Pandas 进行有效的数据清洗和转换:
- 数据清洗:处理缺失值、异常值等。
- 数据转换:编码转换、数据分组等。
付费用户(买一赠一)将获得以下资源:
- 课程视频(98 分钟)
- Python 代码示例(Jupyter Notebook 格式)








 京公网安备 11010802041100号
京公网安备 11010802041100号