作者:钢铁猪991884679 | 来源:互联网 | 2023-09-23 21:37
抓取分析
首先打开要抓取的目标站点:http://maoyan.com/board/4
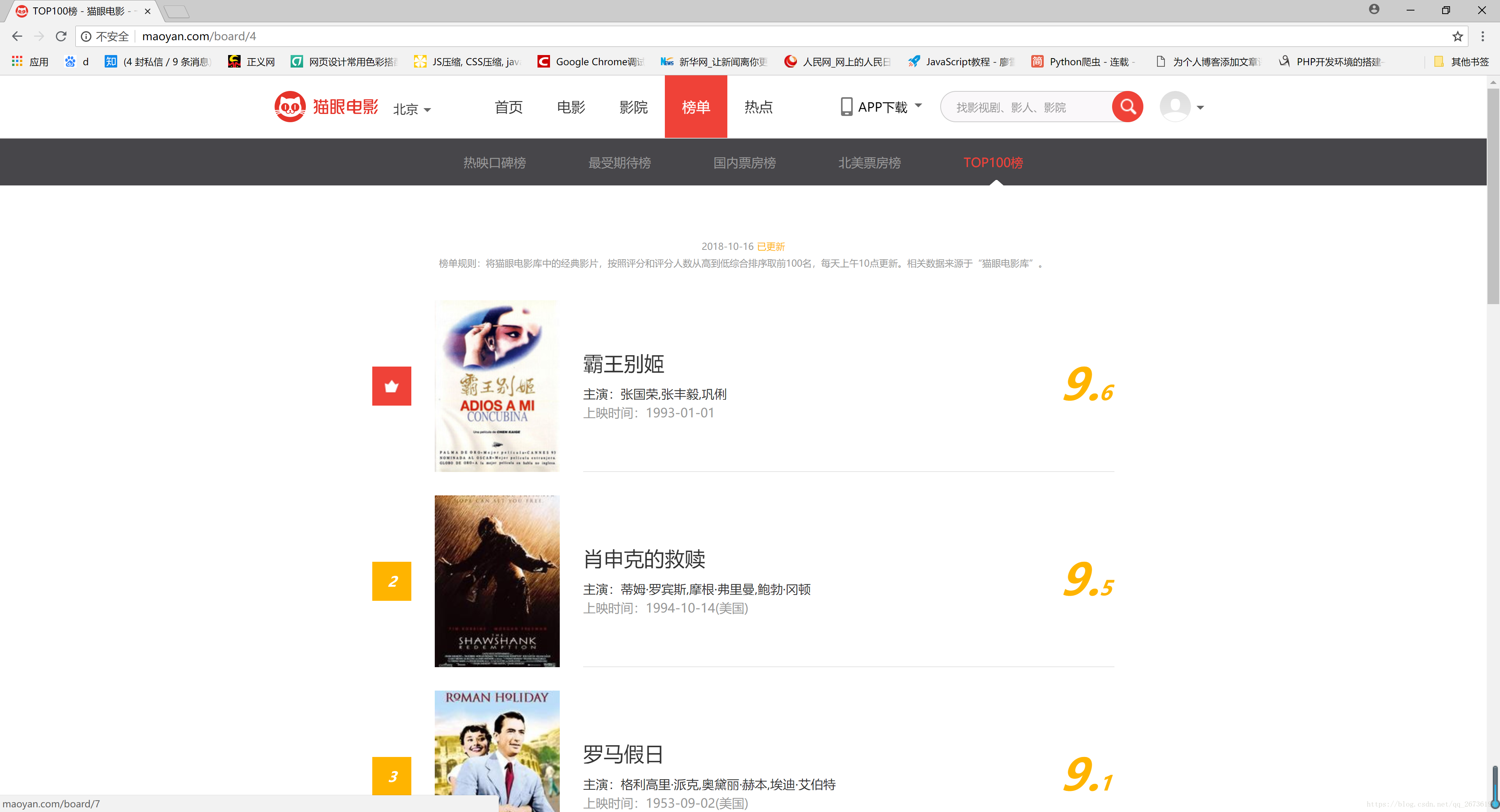
我们需要爬取得实惠电影名称、主演、评分等信息。可以看到在这个页面只有10部影片,而我们需要爬取前100,也就是需要爬取10页。
滚动到最下方分页列表,打开下一页,可以看到页面的URL发生了变化,多了参数offset=10。根据这个规律,我们可以通过改变URL的offset参数请求10次即可。
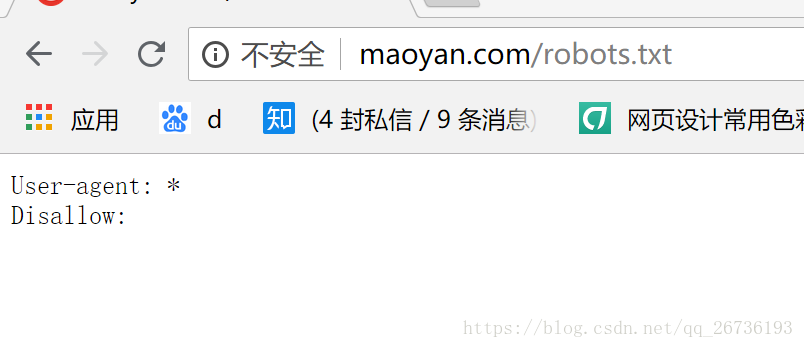
补充:确定一个网站是否可被爬取,可以先在网站根目录下查看Robots协议确定是否可爬:
抓取一页
这里,我们将提取一页的代码用一个函数表示:
def get_one_page(url):headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.17 Safari/537.36',}response = requests.get(url,headers = headers)if response.status_code == 200:return response.textreturn Nonedef main():url = 'http://maoyan.com/board/4'html = get_one_page(url)print(html)main()
这样就可以得到我们的页面源代码。
正则提取
这里,我们要按需进行提取,网页源码信息那么多,但是我们只需要提取我们需求的影片信息。因此,需要对源码进行正则提取,首先就要找到我们需要的信息的源码部分。F12在网页中打开【开发者模式】,在【Network】中左边打开4?offset=0的文件,可以看到源代码。
!注意,不要在【Elements】中直接查看源码,因为【Elements】中的源码可能经过Javascript操作(如果有的话)与原始请求页面不一样。
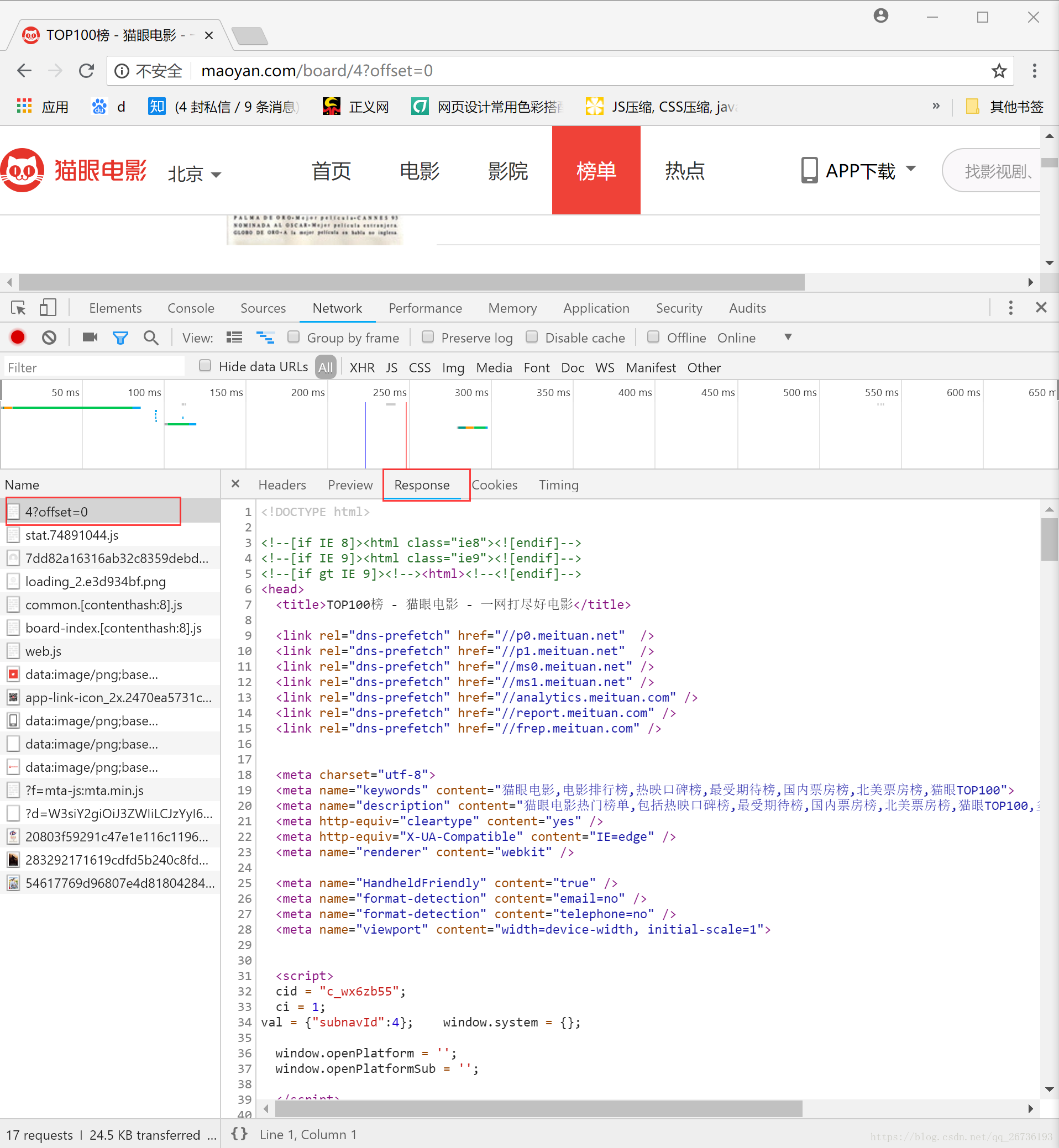

根据我们需要提取的信息构造我们的正则表达式:
#排名信息:
.*?board-index.*?>(.*?) #图片信息:
.*?board-index.*?>(.*?).*?data-src="(.*?)" #名字信息:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?) #主演等等:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star">(.*?).*?releasetime">(.*?).*?integer">(.*?).*?fraction">(.*?).*? def parse_one_page(html):pattern = re.compile('.*?board-index.*?>(.*?)''.*?data-src="(.*?)".*?name.*?a.*?>(.*?)''.*?star">(.*?)
.*?releasetime">(.*?)''.*?integer">(.*?).*?fraction">(.*?).*?', re.S)items = re.findall(pattern,html)print(items) 结果:

完整代码
import reimport requestsimport jsondef get_one_page(url):headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.17 Safari/537.36',}response = requests.get(url,headers = headers)if response.status_code == 200:return response.textreturn Nonedef main(offset):url = 'http://maoyan.com/board/4?offset='+ str(offset)html = get_one_page(url)for item in parse_one_page(html):write_to_file(item)#排名信息:.*?board-index.*?>(.*?)#图片信息:.*?board-index.*?>(.*?).*?data-src="(.*?)"#名字信息:.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)#主演等等综合:.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star">(.*?)
.*?releasetime">(.*?).*?integer">(.*?).*?fraction">(.*?).*?def parse_one_page(html):pattern = re.compile('.*?board-index.*?>(.*?)''.*?data-src="(.*?)".*?name.*?a.*?>(.*?)''.*?star">(.*?).*?releasetime">(.*?)''.*?integer">(.*?).*?fraction">(.*?).*?', re.S)items = re.findall(pattern,html)#整理数据#for item in items:yield{'index': item[0],'image': item[1],'title': item[2].strip(),'actor': item[3].strip()[3:],'time' : item[4].strip()[5:],'score': item[5].strip() + item[6].strip()}print(items)def write_to_file(content): #写入文件with open('result.txt','a',encoding='utf-8') as f:# print(content)f.write(json.dumps(content,ensure_ascii=False)+'\n') #json.dumps()是将dict转化成str格式if __name__ == '__main__': #这里没有这一行也可以for i in range(10):main(offset=i*10) 结果: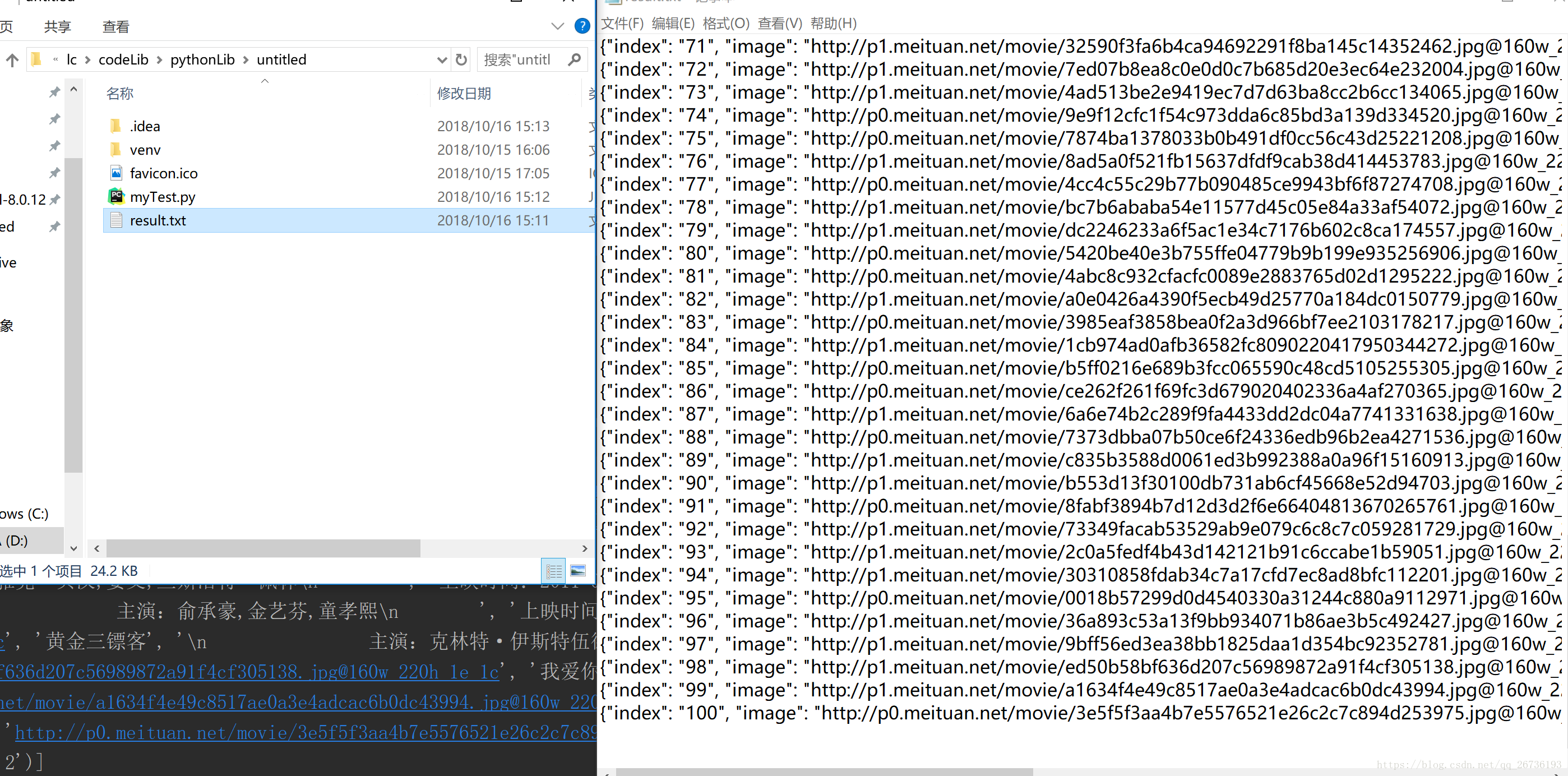
补充: if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
参考见博客:https://blog.csdn.net/yjk13703623757/article/details/77918633









 京公网安备 11010802041100号
京公网安备 11010802041100号