作者:福田商务汽车-日照方傲 | 来源:互联网 | 2024-10-15 03:14
目标站点分析
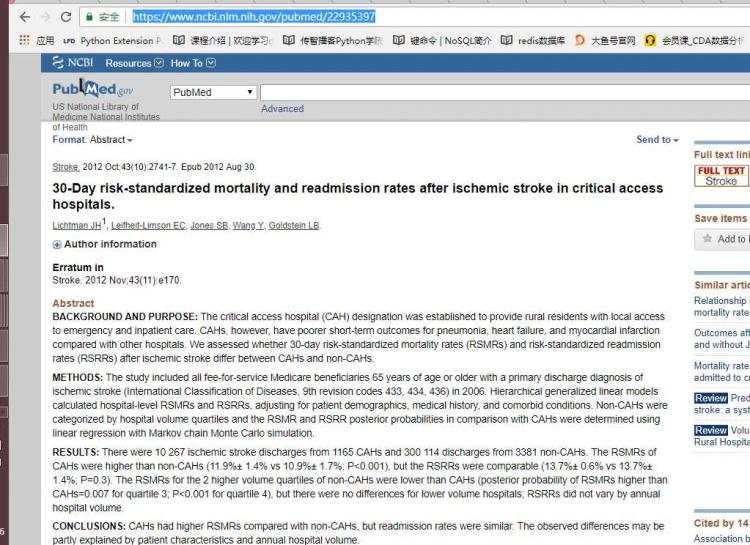
目标:抓取页面中的机构名称,日期,标题,作者, 作者信息, 摘要
程序实现
# -*- coding: utf-8 -*-
"""
@Datetime: 2019/3/6
@Author: Zhang Yafei
"""
import os
import re
import time
from concurrent.futures import ThreadPoolExecutor
import traceback
import pandas as pd
import requests
from pyquery import PyQuery as pq
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36‘}
BASE_DIR = ‘html‘
if not os.path.exists(BASE_DIR):
os.mkdir(BASE_DIR)
class PubMed(object):
def __init__(self, url):
self.url = url
# self.url = ‘https://www.ncbi.nlm.nih.gov/pubmed/{}‘.format(id)
self.retry = 0
def download(self):
try:
respOnse= requests.get(self.url, headers=headers, timeout=20)
if response.status_code == 200:
self.parse(response.content)
except Exception as e:
traceback.print_exc()
print(‘error:‘ + self.url)
while True:
self.retry += 1
if self.retry <5:
try:
respOnse= requests.get(self.url, headers=headers, timeout=15)
if response.status_code == 200:
self.parse(response.content)
return
except Exception as e:
print(e)
time.sleep(10)
else:
print(self.url + ‘下载失败‘)
return
def parse(self, response):
doc = pq(response, parser=‘html‘)
periodical_item = doc(‘.cit‘)
periodical = periodical_item.children().text()
try:
periodical_datetime = re.search(‘(.*?);‘, periodical_item.__str__()).group(1)
except AttributeError:
periodical_datetime = re.search(‘(.*?).‘, periodical_item.__str__()).group(1)
title = doc(‘.rprt_all h1‘).text()
authors_items = doc(‘.auths a‘).items()
authors = ‘,‘.join(list(map(lambda x: x.text(), authors_items)))
author_info = doc(‘.ui-ncbi-toggler-slave dd‘).text()
abstract = doc(‘.abstr‘).text()
data_dict = {‘url‘: [self.url], ‘periodical‘: [periodical], ‘periodical_datetime‘: [periodical_datetime],
‘title‘: [title], ‘authors‘: [authors], ‘author_info‘: [author_info], ‘abstract‘: [abstract]}
self.write_csv(filename=‘pubmed_result.csv‘, data=data_dict)
print(self.url + ‘下载完成‘)
@staticmethod
def write_csv(filename, data=None, columns=None, header=False):
""" 写入 """
if header:
df = pd.DataFrame(columns=columns)
df.to_csv(filename, index=False, mode=‘w‘)
else:
df = pd.DataFrame(data=data)
df.to_csv(filename, index=False, header=False, mode=‘a+‘)
def filter_url_list(urls_list):
df = pd.read_csv(‘pubmed_result.csv‘)
has_urls = df.url.tolist()
url_list = set(urls_list) - set(has_urls)
print(‘共:{} 完成:{} 还剩:{}‘.format(len(urls_list), len(has_urls), len(url_list)))
return list(url_list)
def read_data():
df = pd.read_excel(‘data.xlsx‘, header=None)
return df[0].tolist()
def main(url):
""" 主函数 """
pubmed = PubMed(url=url)
pubmed.download()
if __name__ == ‘__main__‘:
url_list = read_data()
if not os.path.exists(‘pubmed_result.csv‘):
columns = [‘url‘, ‘periodical‘, ‘periodical_datetime‘, ‘title‘, ‘authors‘, ‘author_info‘, ‘abstract‘]
PubMed.write_csv(filename=‘pubmed_result.csv‘, columns=columns, header=True)
else:
url_list = filter_url_list(url_list)
pool = ThreadPoolExecutor()
pool.map(main, url_list)
pool.shutdown()
# 写入excel
df = pd.read_csv(‘pubmed_result.csv‘)
writer = pd.ExcelWriter(‘pubmed_result.xlsx‘)
df.to_excel(writer, ‘table‘, index=False)
writer.save()










 京公网安备 11010802041100号
京公网安备 11010802041100号