碰到个全文搜索的需求,鉴于上家公司的业务日志查询用的就是 ELK ,效果还不错,所以用 ElasticSearch 做搜索引擎感觉问题不大。由于是针对业务数据做全文搜索,数据存在数据库里,所以将这些数据同步到 ES ,怎么做呢,无非两种方式:一是通过 ES 的 API 进行增删改查,二是通过中间件进行数据全量、增量的同步。很明显 API 的方式比较麻烦,那就试试第二种吧。中间件的方式总共搜了三种方案:
Mac 平台 数据库:PostgreSQL 9.5.4 数据库客户端:pgAdmin 4 Python 2.7.10
安装并运行 ElasticSearch
官网下载 ElasticSearch ,解压缩,以下命令运行:
bin/elasticsearch 安装 PostgreSQL 插件 multicorn
github下载 Multicorn:
git clone https://github.com/Kozea/Multicorn /tmp/multicorn cd $_
由于 Multicorn 的 master 代码在 OS X 环境有问题,有几个步骤要手工执行: 1.修改文件 Makefile 的93行,将 darwin 的首字母改成大写:Darwin 2.执行 make 3.sudo ARCHFLAGS=”-arch x86_64″ make install 具体原因看这个issue里的解释 4.执行 make install
CREATE TABLE articles ( id serial PRIMARY KEY, title text NOT NULL, content text NOT NULL, created_at timestamp ); 创建外部表
CREATE FOREIGN TABLE articles_es ( id bigint, title text, content text ) SERVER multicorn_es OPTIONS (host '127.0.0.1', port '9200', node 'test', index 'articles');
参数 host 和 port 是 elasticsearch 服务的主机和端口号,参数 node 表示对应的 ES 中的索引名是 test ,参数 index 表示对应的 ES 中的类型名是 articles 。所以对应的 ES 中该表下的数据 url 访问路径是: http://localhost:9200/test/articles/{id}
创建触发器
对实体表,创建触发器函数,在用户对实体表插入,删除,更新时,通过触发器函数自动将数据同步到对应ES的外部表。同步过程调用 FDW 的接口,对 ES 进行索引的建立,更新,删除:
CREATE OR REPLACE FUNCTION index_article() RETURNS trigger AS $def$ BEGIN INSERT INTO articles_es (id, title, content) VALUES (NEW.id, NEW.title, NEW.content); RETURN NEW; END; $def$ LANGUAGE plpgsql; CREATE OR REPLACE FUNCTION reindex_article() RETURNS trigger AS $def$ BEGIN UPDATE articles_es SET title = NEW.title, cOntent= NEW.content WHERE id = NEW.id; RETURN NEW; END; $def$ LANGUAGE plpgsql; CREATE OR REPLACE FUNCTION delete_article() RETURNS trigger AS $def$ BEGIN DELETE FROM articles_es a WHERE a.id = OLD.id; RETURN OLD; END; $def$ LANGUAGE plpgsql; CREATE TRIGGER es_insert_article AFTER INSERT ON articles FOR EACH ROW EXECUTE PROCEDURE index_article(); CREATE TRIGGER es_update_article AFTER UPDATE OF title, content ON articles FOR EACH ROW WHEN (OLD.* IS DISTINCT FROM NEW.*) EXECUTE PROCEDURE reindex_article(); CREATE TRIGGER es_delete_article BEFORE DELETE ON articles FOR EACH ROW EXECUTE PROCEDURE delete_article(); 测试验证
插入一条表记录:
insert into articles(title, content) values ('测试内容1', '测试标题1');
 shell 脚本例子
shell 脚本例子 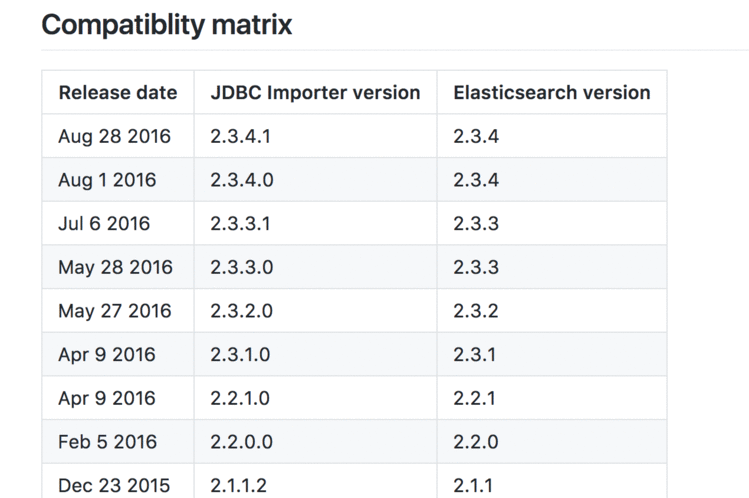 目前最高只兼容Elasticsearch2.3.4
目前最高只兼容Elasticsearch2.3.4 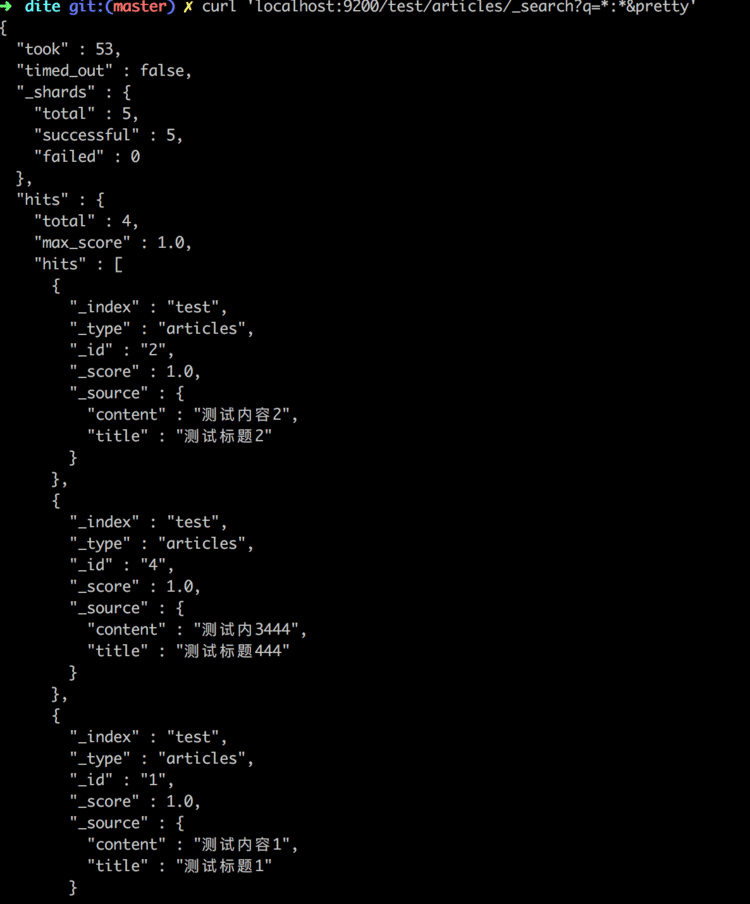 验证同步 ES 的结果
验证同步 ES 的结果






 京公网安备 11010802041100号
京公网安备 11010802041100号