paper:PointRend: Image Segmentation as Rendering
code1:https://github.com/facebookresearch/detectron2/tree/main/projects/PointRend
code2:https://github.com/open-mmlab/mmsegmentation/tree/master/configs/point_rend
创新点
本文的中心思想是将图像分割视为一个渲染问题,具体做法是使用subvision策略来自适应地选择一个非均匀的点集来计算标签。说人话就是针对图像分割中边缘分割不准的情况,提出了一种新的优化方法,具体就是选取网络输出特征图上少数难分像素点,这些难分点大概率分布在物体边缘附近,然后加了一个小的子网络去学习这些难分点的特征,最终提升模型在物体轮廓边缘处的分割精度。
方法介绍
PointRend主要包含三个部分
- a point selection strategy
- a point-wise feature representation
- a point head
Point Selection
推理阶段 对于网络的输出特征图,挑选 \(N\) 个最难分最不确定的点(比如对于只有一类前景的分割问题,概率越接近0.5说明越难分),计算这些难分点的point-wise feature representation,然后根据这些特征去预测这些点的类别。这 \(N\) 个点之外的其它易分点就直接以coarset level即模型输出的最小feature map的预测结果为准。然后上采样,重复该步骤。
训练阶段 推理阶段采用的逐步上采样然后每次都选择 \(N\) 个最难分点的方式不适合训练阶段,因此训练阶段采用non-iterative的方法,首先基于均匀分布随机过采样 \(kN(k>1)\) 个点,然后从中选出 \(\beta N(\beta \in[0,1])\) 个最不确定的点,然后再从剩下的点中基于均匀分布挑出 \((1-\beta)N\) 个点,然后接一个point head subnetwork去学习这 \(N\) 个点的特征,point head的预测和损失计算也只针对这 \(N\) 个点。
Point-wise Representation
Fine-grained features. 为了让PointRend学习精细的分割细节,要从CNN的特征图中提取每个采样点的特征向量,并且要采用浅层的分辨率大的包含丰富细节特征的特征图。下面的实现中采用的是neck输出中分辨率最大的特征图。
Coarse prediction features. 细粒度特征包含了丰富的细节特征,但只有细粒度特征还不够,一是因为当一个点被两个物体的bounding box同时覆盖时,这两个物体在这一点有相同的细粒度特征,但这个点只能被预测为其中一个物体,因为对于实例分割,还需要额外的region-specific特征。二是因为细粒度特征只包含了低维信息,更多的上下文和语义特征可能会有帮助,这对实例分割和语义分割都有帮助。下面的实现中采用的是fpn head的最终预测输出。
将fine-grained特征和coarse prediction特征拼接到一起,就得到了这些采样点的最终特征表示。
Point head
在得到了采样点的特征表示后,PointRend采用了一个多层感知器(MLP)来进行点分割预测,预测每个点的分割类别后,根据对应的标签计算损失进行训练。
代码解析
接下来以mmsegmentation中的PointRend实现为例,讲解一下具体实现。
只有一类前景。假设batch_size=4,input_shape=(4, 3, 480, 480)。backbOne=ResNetV1c,backbone的输出为[(4, 256, 120, 120), (4, 512, 60, 60), (4, 1024, 30, 30), (4, 2048, 15, 15)]。neck=FPN,neck后的输出为[(4, 256, 120, 120), (4, 512, 60, 60), (4, 1024, 30, 30), (4, 2048, 15, 15)]。pointrend中有两个head,因此用cascade_encoder_decoder将两个head串联起来。第一个head是FPN head,借鉴了Panoptic Feature Pyramid Networks中的Semantic FPN,这里就不具体介绍了,输出为(4, 2, 120, 120),然后计算这个head的损失,loss采用的交叉熵损失。
第二个head是point_head,point_head的输入包括neck的最大分辨率输出(4, 256, 120, 120),以及FPN head的输出(4, 2, 120, 120)。
选择难分点,这里prev_output是fpn head的输出
with torch.no_grad():points = self.get_points_train(prev_output, calculate_uncertainty, cfg=train_cfg) # (4,2,120,120) -> (4,2048,2)
评价难分程度的函数如下,具体就是计算每个点top1得分和top2得分的差,差越小说明越难分。注意这里计算的是top2-top1,值为负,所以值越大说明越难分。
def calculate_uncertainty(seg_logits):top2_scores = torch.topk(seg_logits, k=2, dim=1)[0] # (4,2,6144) -> (4,2,6144)return (top2_scores[:, 1] - top2_scores[:, 0]).unsqueeze(1) # (4,6144) -> (4,1,6144)
具体选择用于训练的难分点实现如下,其中随机采样是通过mmcv中的函数point_sample实现的,而point_sample中首先将随机采样的坐标point_coords由[0, 1]转化到[-1, 1]区间,然后通过F.grid_sample根据归一化的坐标位置进行插值采样,F.grid_sample的用法见F.grid_sample 用法解读_00000cj的博客-CSDN博客。在训练过程中,如上文所述,point selection阶段 \(N=2048,k=3,\beta =0.75\)。实际挑出训练的点有2048个,首先随机采样3x2048=6144个点,然后挑选出最难分的0.75x2048=1536个点,剩下的2048-1536=512个数随机挑选。
def get_points_train(self, seg_logits, uncertainty_func, cfg):"""Sample points for training.Sample points in [0, 1] x [0, 1] coordinate space based on theiruncertainty. The uncertainties are calculated for each point using&#39;uncertainty_func&#39; function that takes point&#39;s logit prediction asinput.Args:seg_logits (Tensor): Semantic segmentation logits, shape (batch_size, num_classes, height, width).uncertainty_func (func): uncertainty calculation function.cfg (dict): Training config of point head.Returns:point_coords (Tensor): A tensor of shape (batch_size, num_points,2) that contains the coordinates of ``num_points`` sampledpoints."""num_points = cfg.num_points # 2048oversample_ratio = cfg.oversample_ratio # 3importance_sample_ratio = cfg.importance_sample_ratio # 0.75assert oversample_ratio >= 1assert 0 <= importance_sample_ratio <= 1batch_size = seg_logits.shape[0] # (4,2,120,120)num_sampled = int(num_points * oversample_ratio) # 2048x3=6144point_coords = torch.rand(batch_size, num_sampled, 2, device=seg_logits.device) # (4,6144,2)point_logits = point_sample(seg_logits, point_coords) # (4,2,6144)# It is crucial to calculate uncertainty based on the sampled# prediction value for the points. Calculating uncertainties of the# coarse predictions first and sampling them for points leads to# incorrect results. To illustrate this: assume uncertainty func(# logits)=-abs(logits), a sampled point between two coarse# predictions with -1 and 1 logits has 0 logits, and therefore 0# uncertainty value. However, if we calculate uncertainties for the# coarse predictions first, both will have -1 uncertainty,# and sampled point will get -1 uncertainty.point_uncertainties = uncertainty_func(point_logits) # (4,1,6144)num_uncertain_points = int(importance_sample_ratio * num_points) # 0.75x2048=1536num_random_points = num_points - num_uncertain_points # 512idx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1] # (4,1536)shift = num_sampled * torch.arange(batch_size, dtype=torch.long, device=seg_logits.device) # (4,), (0,6144,12288,18432)idx += shift[:, None] # (4,1536) += (4,1) -> (4,1536)# (4,6144,2)->(24576,2)[(4,1536)->(6144), :] -> (6144,2) -> (4,1536,2)point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(batch_size, num_uncertain_points, 2)if num_random_points > 0:rand_point_coords = torch.rand(batch_size, num_random_points, 2, device=seg_logits.device)point_coords = torch.cat((point_coords, rand_point_coords), dim=1) # (4,2048,2)return point_coords
在得到待训练点的坐标后,分别从neck最大分辨率输出(4, 256, 120, 120)和FPN head的预测结果(4, 2, 120, 120)上插值得到对应的fine feature和coarse feature。其中内部实现还是通过point_sample。
fine_grained_point_feats = self._get_fine_grained_point_feats(x, points) # (4,256,2048)
coarse_point_feats = self._get_coarse_point_feats(prev_output, points) # (4,2,2048)
然后将fine feature和coarse feature拼接起来,最终的point head是一个MLP,层数为3,最终再经过一个卷积层得到这2048个点的分类结果。
point_logits = self.forward(fine_grained_point_feats, coarse_point_feats) # (4,2,2048)def forward(self, fine_grained_point_feats, coarse_point_feats):x = torch.cat([fine_grained_point_feats, coarse_point_feats], dim=1) # (4,258,2048)for fc in self.fcs:x = fc(x)if self.coarse_pred_each_layer: # Truex = torch.cat((x, coarse_point_feats), dim=1) # (4,258,2048)return self.cls_seg(x) # (4,2,2048)
在得到难分点的预测结果后,因为采样点的坐标不是整数,特征是从feature map上插值得到的,对应的标签也要插值得到,只不过特征插值时是采用的bilinear,而标签采用的是nearest。point head的loss也是交叉熵损失。
point_label = point_sample(gt_semantic_seg.float(), # (4,1,480,480)points,mode=&#39;nearest&#39;,align_corners=self.align_corners) # (4,1,2048)
point_label = point_label.squeeze(1).long() # (4,2048)
losses = self.losses(point_logits, point_label)
实验结果
下图是一些示例,可以看出PointRend对边缘的分割更加精细。

因为只采样少数难分点,而对于大部分易分点比如远离图像边缘的区域,coarse prediction就足够了,因此增加point head后增加的计算量有限,如下
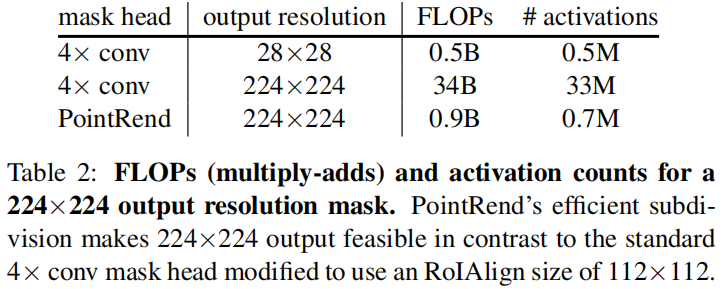
下面分别是在DeeplabV3和SemanticFPN中加入PointRend,精度都得到了提升


分割的标注通常不够精确,因此实际效果的提升可能比上表中的更大。



 京公网安备 11010802041100号
京公网安备 11010802041100号