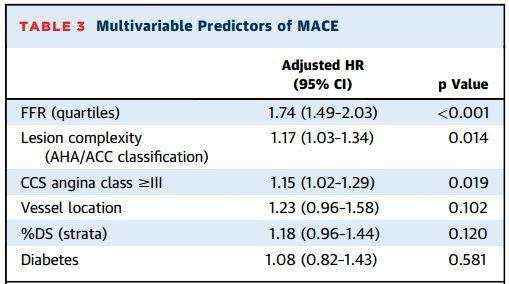
作者:等着日落看日出222 | 来源:互联网 | 2023-09-15 02:40
I need to sort through a large amount of data in multiple 600,000 row csv files of a test I've just conducted.
我需要在我刚刚进行的一个测试的60万行csv文件中对大量数据进行排序。
This is a snippet.
这是一个片段。
Test
测试
Effectively what I'm after is to pick the largest number from column C and and it's correspond row in column B for each test run.
实际上,我所要做的就是从C列中选出最大的数,并在B列对应每一个测试运行。
E.g. I ran "big test" first the largest number in column c is 42.59797 and it's corresponding row is 2045.591 up until small test begins. Then pick the biggest number in column C for "small test" which will be 40.12216 and it's corresponding row will be -2106.67 and repeat all the way down the column. Also the data extracted must be in the order it was extracted in.
我先进行了“大测试”,第一个c列中最大的数是42.59797,对应的行是2045.591,直到小测试开始。然后选择C中最大的“小测试”,它将是40.12216,对应的行是-2106.67,并在列中重复。提取的数据也必须按照提取的顺序进行。
Thanks.
谢谢。
1 个解决方案







 京公网安备 11010802041100号
京公网安备 11010802041100号