作者:张芬921_162 | 来源:互联网 | 2023-09-03 10:23
PaddlePaddle(中文名:飞桨,PArallel Distributed Deep LEarning 并行分布式深度学习)是一个深度学习平台,具有易用、高效、灵活和可伸缩等特点,它是中国第一个开源深度学习开发框架。
飞桨框架的核心技术,主要包括前端语言、组网编程范式、核心架构、算子库以及高效率计算核心五部分。下边分别分析这几部分。
核心架构
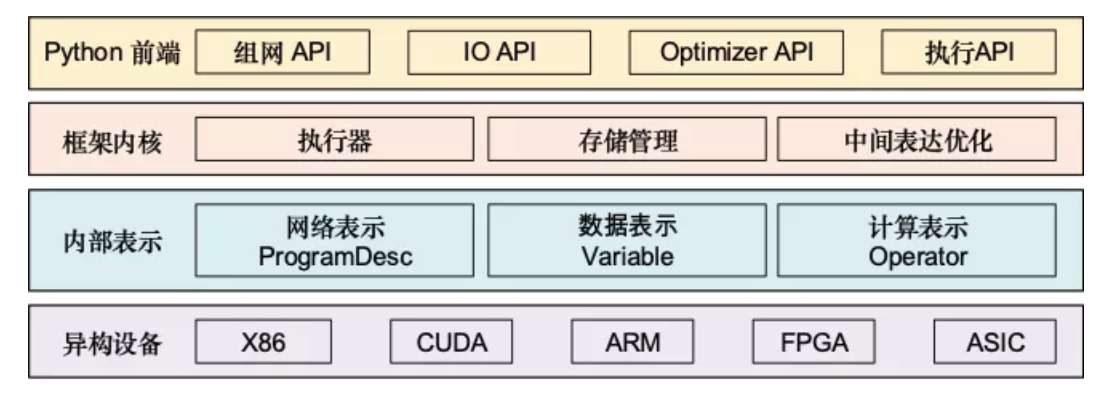
飞桨核心架构采用分层设计,如下图所示,前端应用层考虑灵活性,采用Python实现,包括了组网 API、IO API、OptimizerAPI和执行 API等完备的开发接口;框架底层充分考虑性能,采用C++来实现。
框架内核部分,主要包含执行器、存储管理和中间表达优化;内部表示方面,包含网络表示(ProgramDesc)、数据表示(Variable)和计算表示(Operator)几个层面。框架向下对接各种芯片架构,可以支持深度学习模型在不同异构设备上的高效运行。
前端语言
为了方便用户使用,飞桨选择Python作为模型开发和执行调用的主要前端语言,并提供了丰富的编程接口API。Python作为一种解释型编程语言,代码修改不需要重新编译就可以直接运行,使用和调试非常方便,并且拥有丰富的第三方库和语法糖,拥有众多的用户群体。
同时为了保证框架的执行效率,飞桨底层实现采用C++。对于预测推理,为方便部署应用,则同时提供了C++和Java API。
组网编程范式
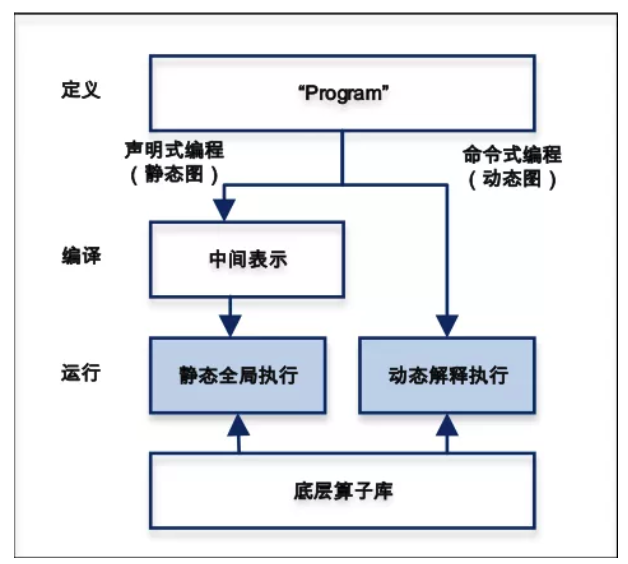
飞桨中同时兼容命令式编程(动态图)与声明式编程(静态图)两种编程范式,以程序化“Program”的形式动态描述神经网络模型计算过程,并提供对顺序、分支和循环三种执行结构的支持,可以组合描述任意复杂的模型,并可在内部自动转化为中间表示的描述语言。
“Program”的定义过程就像在写一段通用程序,使用声明式编程时,相当于将“Program”先编译再执行,可类比静态图模式。
首先根据网络定义代码构造“Program”,然后将“Program”编译优化,最后通过执行器执行“Program”,具备高效性能;同时由于存在静态的网络结构信息,能够方便地完成模型的部署上线。
而命令式编程,相当于将“Program”解释执行,可视为动态图模式,更加符合用户的编程习惯,代码编写和调试也更加方便。
飞桨后面会增强静态图模式下的调试功能,方便开发调试;同时提升动态图模式的运行效率,加强动态图自动转静态图的能力,快速完成部署上线;同时更加完善接口的设计和功能,整体提升框架易用性。
显存管理
飞桨为用户提供简单易用、兼顾显存回收与复用的显存优化策略,在很多模型上的表现优异。
显存分配机制
原生的CUDA系统调用(cudaMalloc)和释放(cudaFree)均是同步操作,非常耗时。为了加速显存分配,飞桨实现了显存预分配的策略,具体方式如下图所示。
设置一个显存池chunk,定义其大小为chunk_size。若分配需求requested_size不超过chunk_size,则框架会预先分配chunk_size大小的显存池chunk,并从中分出requested_size大小的块返回。
之后每次申请显存都会从chunk中分配。若requested_size大于chunk_size,则框架会调用cudaMalloc分配requested_size大小的显存。chunk_size一般依据初始可用显存大小按比例确定。
同时飞桨也支持按实际显存占用大小的动态自增长的显存分配方式,可以更精准地控制显存使用,以节省对显存占用量,方便多任务同时运行。

显存垃圾及时回收机制
显存垃圾及时回收机制GC(Garbage Collection)的原理是在网络运行阶段释放无用变量的显存空间,达到节省显存的目的。
GC策略会积攒一定大小的显存垃圾后再统一释放。GC内部会根据变量占用的显存大小,对变量进行降序排列,且仅回收前面满足占用大小阈值以上的变量显存。GC策略默认生效于使用Executor或Parallel Executor做模型训练预测时。
Operator内部显存复用机制
Operator内部显存复用机制(Inplace)的原理是Operator的输出复用Operator输入的显存空间。例如,数据整形(reshape)操作的输出和输入可复用同一片显存空间。
Inplace策略可通过构建策略(BuildStrategy)设置生效于Parallel Executor的执行过程中。
算子库
飞桨算子库目前提供了500余个算子,并在持续增加,能够有效支持自然语言处理、计算机视觉、语音等各个方向模型的快速构建。同时提供了高质量的中英文文档,更方便国内外开发者学习使用。文档中对每个算子都进行了详细描述,包括原理介绍、计算公式、论文出处,详细的参数说明和完整的代码调用示例。
飞桨的算子库覆盖了深度学习相关的广泛的计算单元类型。比如提供了多种循环神经网络(Recurrent Neural Network,RNN),多种卷积神经网络(Convolutional Neural Networks, CNN)及相关操作,如深度可分离卷积(Depthwise Deparable Convolution)、空洞卷积(Dilated Convolution)、可变形卷积(Deformable Convolution)、池化兴趣区域池化及其各种扩展、分组归一化、多设备同步的批归一化。
另外涵盖多种损失函数和数值优化算法,可以很好地支持自然语言处理的语言模型、阅读理解、对话模型、视觉的分类、检测、分割、生成、光学字符识别(Optical Character Recognition,OCR)、OCR检测、姿态估计、度量学习、人脸识别、人脸检测等各类模型。
飞桨的算子库除了在数量上进行扩充之外,还在功能性、易用性、便捷开发上持续增强。
例如针对图像生成任务,支持生成算法中的梯度惩罚功能,即支持算子的二次反向能力;而对于复杂网络的搭建,将会提供更高级的模块化算子,使模型构建更加简单的同时也能获得更好的性能;对于创新型网络结构的需求,将会进一步简化算子的自定义实现方式,支持Python算子实现,对性能要求高的算子提供更方便的、与框架解耦的C++实现方式,可使得开发者快速实现自定义的算子,验证算法。
高效率计算核心
飞桨对核心计算的优化,主要体现在以下两个层面。
Operator粒度层面
飞桨提供了大量不同粒度的Operator(Op)实现。细粒度的Op能够提供更好的灵活性,而粗粒度的Op则能提供更好的计算性能。
飞桨提供了诸如softmax_with_cross_entropy等组合功能Op,也提供了像fusion_conv_inception、fused_elemwise_activation等融合类Operator。
其中大部分普通Op,用户可以直接通过Python API配置使用,而很多融合的Op,执行器在计算图优化的时候将会自动进行子图匹配和替换。
核函数实现层面
飞桨主要通过两种方式来实现对不同硬件的支持:人工调优的核函数实现和集成供应商优化库。
针对CPU平台,飞桨一方面提供了使用指令Intrinsic函数和借助于xbyak JIT汇编器实现的原生Operator,深入挖掘编译时和运行时性能。
另一方面,飞桨通过引入OpenBLAS、Intel® MKL、Intel® MKL-DNN 和nGraph,对Intel CXL等新型芯片提供了性能保证。
针对GPU平台,飞桨既为大部分Operator用CUDA C实现了经过人工精心优化的核函数,也集成了cuBLAS、cuDNN等供应商库的新接口、新特性。





 京公网安备 11010802041100号
京公网安备 11010802041100号