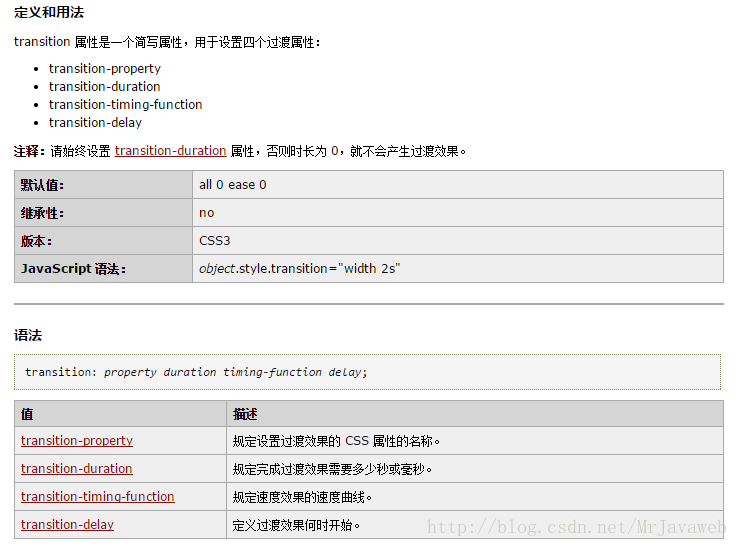
今天练习了用爬虫批量爬取网站文件。练习对象是一个妹子图片网站,网址在代码里有哈哈哈,最后实现了将妹子的大图批量下载到电脑里,好爽嘿嘿嘿。收获如下:
将远程文件下载到本地用的是urlretrieve方法,他主要有两个参数:文件的网址和要存储的文件名。其中第二个参数要特别注意:要到文件名才行,不能只是路径。而文件名的构造采用了如下的代码,暂时还不太懂,但是先学会再说:
x =0
for item in imgurl:urlretrieve(item,'/Users/zengyichao/Desktop/工作零碎文件/2.21/test4/'+'%s.jpg'%x)x+=1
import requests
from bs4 import BeautifulSoup
import time
from urllib.request import urlretrieve
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}imgurl = []def get_img(url):res = requests.get(url, headers = headers)res.encoding = 'utf-8'soup = BeautifulSoup(res.text,'html.parser')imgs = soup.select('#big-pic > p > a > img')for img in imgs:href = img.get('src')imgurl.append(href)#
# url = 'http://www.mmonly.cc/mmtp/xgmn/198663.html'
# get_img(url)urls = ['http://www.mmonly.cc/mmtp/xgmn/100306_{}.html'.format(str(i)) for i in range(2,31)]
for url in urls:get_img(url)x =0
for item in imgurl:urlretrieve(item,'/Users/zengyichao/Desktop/工作零碎文件/2.21/test4/'+'%s.jpg'%x)x+=1print(imgurl)







 京公网安备 11010802041100号
京公网安备 11010802041100号