作者 | 奇猫
来源 | 51CTO
爬虫是获取数据的一种方式,网络上很多请求都是由爬虫发起的。
说几个爬虫的实际例子:
①想要做舆论分析,分析当前热点话题,可以爬取腾讯新闻,微博,今日头条等主流站点数据,然后进行分析;
②想要做电影推荐或影评分析,可以爬取豆瓣,猫眼等数据进行分析;
③想要做电商销售分析,可以爬取京东,淘宝商家数据进行分析;

当我们使用高并发或者分布式爬虫对这些站点进行抓取时,可能会损害站点利益:
①短时间内大量请求占用站点资源:网络带宽,服务器负载;
②如果我们获取数据,自己获益,可能会损害他人利益;
但是百度,谷歌等搜索引擎厂商无时无刻不在抓取信息,还有很多其他企业和个人也在抓取自己感兴趣信息。如何保护自己利益不受侵犯,企业从制定行业规范与技术两方面做了处理,这也是我们这节主要内容:

1.robots协议:爬虫规范;
2.常见反爬机制;
3.反爬机制应对方式;

<1>
robots协议
robots协议是一个文本文件&#xff0c;通过协议声明站点的哪些信息可以抓取&#xff0c;哪些禁止抓取。
robots协议位置&#xff1a;http://xxxx/robots.txt ;例如&#xff1a;百度https://www.baidu.com/robots.txt &#xff0c;内容如下&#xff1a;
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/ User-agent: Googlebot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
... ...
User-agent: *
Disallow: /
robots协议相关说明如下&#xff1a;
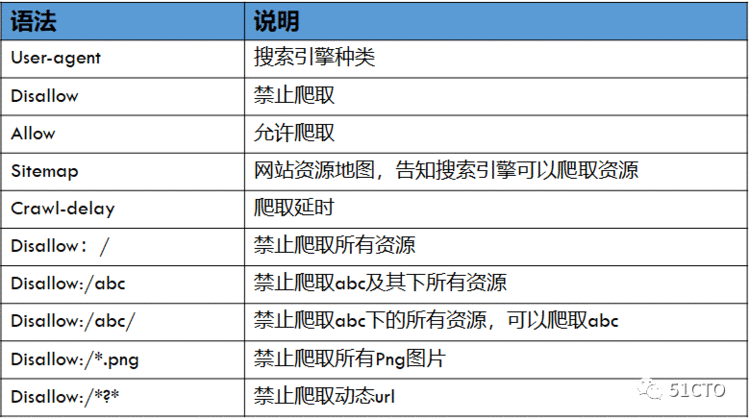
我们来简单分析下百度的robots.txt
①User-agent&#xff1a;Baiduspider&#xff0c; Googlebot...是针对的搜索引擎
②Disallow&#xff1a;/baidu&#xff0c;/s?...禁止这些搜索引擎爬取相应的资源
③User-agent: * Disallow: /&#xff1a;禁止其他搜索引擎爬取任何资源&#xff0c;以上列出的除外&#xff1b;
如果搜索引擎类型没有在百度的robots.txt声明中&#xff0c;禁止该引擎抓取本站的任何资源。
<2>
反爬虫策略与应对方式
robots协议定义了行业规范&#xff0c;但是很多开发者还是会进行暴力爬取&#xff0c;增加服务器负载&#xff0c;占用网络带宽&#xff0c;这就需要制定反爬策略&#xff0c;主要方式有下面几种&#xff1a;
①判断User-Agent&#xff0c;是否为浏览器&#xff1b;
②判断短时间内同一个IP访问次数&#xff1b;
③用户登录后才能访问资源&#xff1b;
④短时间用户使用不同IP访问资源&#xff0c;异常登录&#xff1b;
⑤验证码&#xff0c;滑动点击验证&#xff1b;
⑥数据加解密处理&#xff1b;
对于不同反爬策略&#xff0c;可以使用不同应对方式&#xff1a;
①User-Agent&#xff1a;发起请求时候添加头信息&#xff0c;伪装浏览器&#xff1b;
②短时间内访问次数限制&#xff1a;可以使用代理或者延时爬取&#xff1b;
③登录后访问&#xff1a;模拟登录保存COOKIE,请求时添加COOKIE信息&#xff1b;
④异常登录&#xff1a;准备大量账号&#xff0c;绑定不同代理进行爬取&#xff1b;
⑤验证码&#xff1a;使用Ocr&#xff0c;机器学习进行处理&#xff0c;但是准确率是一个问题&#xff1b;
⑥数据加解密处理&#xff1a;使用对应算法进行破解&#xff0c;或者使用selenium进行抓取&#xff1b;
本文主要解决User-Agent与短时间内访问次数限制。
<3>
例子&#xff1a;伪装浏览器
我们来看一个例子&#xff0c;使用浏览器访问某主页&#xff1a;http://www.xicidaili.com/ &#xff1b;能够正常访问&#xff1b;然后使用urllib请求g该主页&#xff0c;代码如下&#xff1a;
from urllib import request
url&#61; &#39;http://www.xicidaili.com/&#39;
req &#61; request.urlopen(url)
print(req.code)
运行出错&#xff0c;结果如下&#xff1a;
查看浏览器请求头信息与User-Agent&#xff1a;
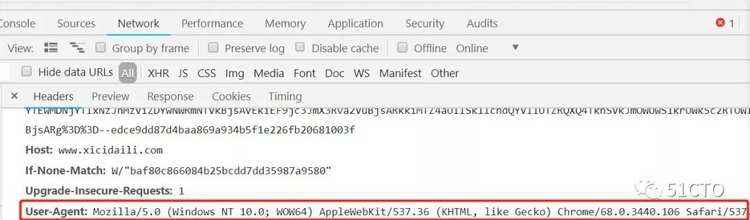
当我们使用urllib请求该主页&#xff0c;服务器检查User-Agent&#xff0c;认为这次请求不是浏览器请求&#xff0c;所以拒绝访问&#xff1b;我们可以在访问时添加请求头信息设置User-Agent&#xff0c;代码实现如下&#xff1a;
from urllib import request
#user-agent
headers &#61; {&#39;User-Agent&#39;:&#39;Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36&#39;}
url&#61; &#39;http://www.xicidaili.com/&#39;
#创建Request对象&#xff0c;添加user-agent,伪装浏览器
reqhd &#61; request.Request(url&#61;url, headers&#61;headers)
req &#61; request.urlopen(reqhd)
print(req.code)
输出结果&#xff1a;200。至此&#xff0c;我们成功解决第一个反爬问题。












 京公网安备 11010802041100号
京公网安备 11010802041100号