分享一篇使用部分爬虫技术简单实现对媒体类网页按需求爬取文章并保存到本地指定文件夹的案例,仅供相关学习者参考,学习过程切勿对网站频繁访问而造成网页瘫痪,量力而为!!!
BeautifulSoup的简单使用:https://inganxu.blog.csdn.net/article/details/122783587
爬取地址:建筑档案-建筑行业全产业链内容共建平台
爬取涉及技术:Requests(访问)、BeautifulSoup、Re(解析)、Pandas(保存)
爬取目的:仅用于练习巩固爬虫技术
爬取目标:
发起首页网页请求,获取响应内容
解析首页网页数据,获取文章的标题、作者、发布时间、文章链接信息
汇总网站首页信息,保存到excel中
发起文章网页请求,获取响应内容
解析文章网页数据,获取文章的文本、图片链接信息
保存文章内容到指定文档中
发起图片网页请求,获取响应内容
保存图片到指定文件夹中
下面以爬虫思路的顺序讲解每个步骤的实现方式以及注意事项
import requests # 用于发起网页请求,返回响应内容
import pandas as pd # 生成二维数据,保存到excel中
import os # 文件保存
import time # 减慢爬虫速度
import re # 提取解析内容
from bs4 import BeautifulSoup # 对响应内容解析数据
没有相关的库就自行安装
win键+r,调出CMD窗口,输入以下代码
pip install 欠缺的库名
"""
记录爬虫时间
设置访问网页基础信息
"""
start_time = time.time()
start_url = "https://www.jzda001.com"
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'}
hearder:表头,自己复制浏览器的表头,实在不会找就直接复制我的用
response = requests.get(url=start_url, headers=header) # 发起请求
html = response.text # 提取响应内容
soup = BeautifulSoup(html, 'lxml') # 解析响应内容
content = soup.find_all('div', attrs={'class': 'content-left'})[0] # 筛选并提取仅需爬虫的内容# 使用列表来装载爬虫信息
item = {}
href_list = []
title_list = []
author_list = []
releasetime_list = []# 获取文章链接
for href in content.find_all('a', href=re.compile('^/index/index/details')):if href['href'] not in href_list:href_list.append(href['href'])# 获取文章标题
for title in content.find_all('p', class_=re.compile('(twoline|sub oneline|oneline)'))[:-1]:title_list.append(title.text)# 获取文章作者和发布时间
for author_time in content.find_all(&#39;p&#39;, attrs&#61;{&#39;class&#39;: &#39;name&#39;}):if len(author_list) <20:author &#61; re.findall(r&#39;(?<&#61;\s)\D&#43;(?&#61;\s\.)&#39;, author_time.text)[0]author_list.append(author.replace(&#39; &#39;, &#39;&#39;))if len(releasetime_list) <20:time &#61; re.findall(r&#39;\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}&#39;, author_time.text)releasetime_list.append(time[0])
解析过程发现获取的内容头部或尾部有不需要的信息&#xff0c;因此使用列表切片方式将元素剔除掉
# 主页面数据清洗
author_clear &#61; []
for i in author_list:if i !&#61; &#39;.&#39;:author_clear.append(i.replace(&#39;\n&#39;, &#39;&#39;).replace(&#39; &#39;, &#39;&#39;))
author_list &#61; author_clear
time_clear &#61; []
for j in releasetime_list:time_clear.append(j.replace(&#39;\n&#39;, &#39;&#39;).replace(&#39; &#39;, &#39;&#39;).replace(&#39;:&#39;, &#39;&#39;))
releasetime_list &#61; time_clear
title_clear &#61; []
for n in title_list:title_clear.append(n.replace(&#39;&#xff1a;&#39;, &#39; &#39;).replace(&#39;&#xff01;&#39;, &#39; &#39;).replace(&#39;|&#39;, &#39; &#39;).replace(&#39;/&#39;, &#39; &#39;).replace(&#39; &#39;, &#39; &#39;))
title_list &#61; title_clear
查看网页结构&#xff0c;可以看到标题、作者、发布时间都有一些系统敏感字符&#xff08;影响后续无法创建文件夹&#xff09;
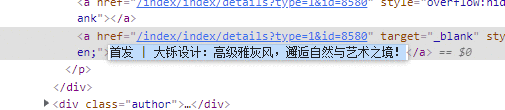
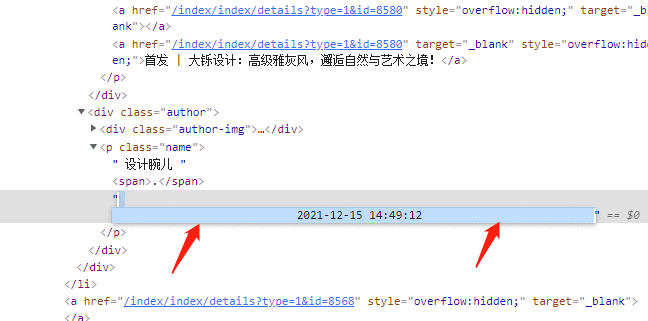
所以&#xff0c;需要把解析到的数据作数据清洗后才能使用
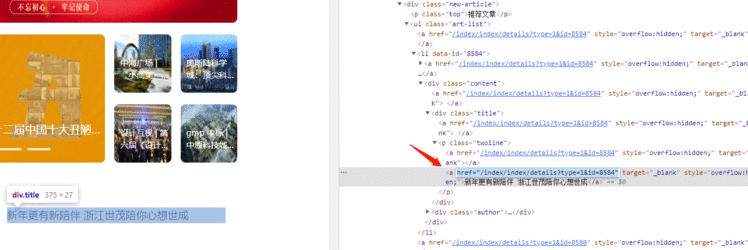
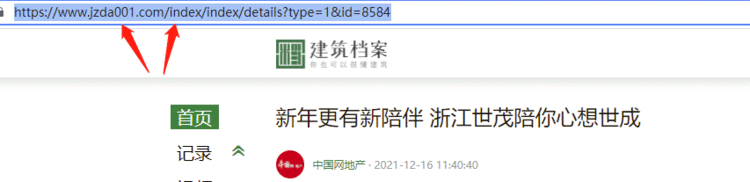
通过对比网页结构的&#64;href属性链接和文章的真实链接&#xff0c;可知解析到的url需要拼接网址首页进去
# 访问文章并保存文本信息和图片到指定文件夹
for nums in range(20):text_list &#61; []img_url_list &#61; []article_url &#61; start_url &#43; href_list[nums]response_url &#61; requests.get(article_url, headers&#61;header, timeout&#61;1)html_text &#61; response_url.textsoup_article &#61; BeautifulSoup(html_text, &#39;lxml&#39;)# 获取子页面文本&#xff08;用find_all方法&#xff09;content_article &#61; soup_article.find_all(&#39;div&#39;, attrs&#61;{&#39;class&#39;: &#39;content&#39;})[-1]text &#61; &#39;&#39;for i in content_article:text &#61; text &#43; i.texttext_list.append(text)# 获取子页面图片链接&#xff08;用select方法&#xff09;soup_article_url &#61; content_article.select(&#39;.pgc-img > img&#39;)for url in soup_article_url:img_url_list.append(url[&#39;src&#39;])
拼接文本内容是因为获取到的文本信息是一段一段分开的&#xff0c;需要拼接在一起&#xff0c;才是完整的文章文本信息

新建多层文件夹file_name &#61; "建筑档案爬虫文件夹" # 文件夹名称path &#61; r&#39;d:/&#39; &#43; file_nameurl_path_file &#61; path &#43; &#39;/&#39; &#43; title_list[nums] &#43; &#39;/&#39; # 拼接文件夹地址if not os.path.exists(url_path_file):os.makedirs(url_path_file)
因为创建的文件夹是&#xff1a;“./爬虫文件夹名称/文章标题名称/”&#xff0c;所以需要用os.makedirs来创建多层文件夹
注意文件名称最后带 “/”
当建立好文件夹后&#xff0c;就开始访问每个文章的图片链接&#xff0c;并且保存下来
# 保存子页面图片for index, img_url in enumerate(img_url_list):img_rep &#61; requests.get(img_url, headers&#61;header, timeout&#61;5) # 设置超时时间index &#43;&#61; 1 # 每保存图片一次&#xff0c;显示数量&#43;1img_name &#61; title_list[nums] &#43; &#39; 图片&#39; &#43; &#39;{}&#39;.format(index) # 图片名称img_path &#61; url_path_file &#43; img_name &#43; &#39;.png&#39; # 图片地址with open(img_path, &#39;wb&#39;) as f:f.write(img_rep.content) # 以二进制的方式写入f.close()
先保存文本再保存图片也可以&#xff0c;需要注意两者的写入方式
# 保存网页文本txt_name &#61; str(title_list[nums] &#43; &#39; &#39; &#43; author_list[nums] &#43; &#39; &#39; &#43; releasetime_list[nums]) # 文本名称txt_path &#61; url_path_file &#43; &#39;/&#39; &#43; txt_name &#43; &#39;.txt&#39; # 文本地址with open(txt_path, &#39;w&#39;, encoding&#61;&#39;utf-8&#39;) as f:f.write(str(text_list[0]))f.close()
将网站首页的所有文章标题、作者、发布时间、文章链接都保存到一个excel文件夹中
# 主页面信息保存
data &#61; pd.DataFrame({&#39;title&#39;: title_list,&#39;author&#39;: author_list,&#39;time&#39;: releasetime_list,&#39;url&#39;: href_list})
data.to_excel(&#39;{}./data.xls&#39;.format(path), index&#61;False)
# &#xff01;/usr/bin/python3.9
# -*- coding:utf-8 -*-
# &#64;author:inganxu
# CSDN:inganxu.blog.csdn.net
# &#64;Date:2022年2月3日import requests # 用于发起网页请求&#xff0c;返回响应内容
import pandas as pd # 生成二维数据&#xff0c;保存到excel中
import os # 文件保存
import time # 减慢爬虫速度
import re # 提取解析内容
from bs4 import BeautifulSoup # 对响应内容解析数据start_time &#61; time.time()start_url &#61; "https://www.jzda001.com"
header &#61; {&#39;user-agent&#39;: &#39;Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36&#39;}response &#61; requests.get(url&#61;start_url, headers&#61;header) # 发起请求
html &#61; response.text # 提取响应内容
soup &#61; BeautifulSoup(html, &#39;lxml&#39;) # 解析响应内容
content &#61; soup.find_all(&#39;div&#39;, attrs&#61;{&#39;class&#39;: &#39;content-left&#39;})[0] # 筛选并提取仅需爬虫的内容# 使用列表来装载爬虫信息
item &#61; {}
href_list &#61; []
title_list &#61; []
author_list &#61; []
releasetime_list &#61; []# 获取文章链接
for href in content.find_all(&#39;a&#39;, href&#61;re.compile(&#39;^/index/index/details&#39;)):if href[&#39;href&#39;] not in href_list:href_list.append(href[&#39;href&#39;])# 获取文章标题
for title in content.find_all(&#39;p&#39;, class_&#61;re.compile(&#39;(twoline|sub oneline|oneline)&#39;))[:-1]:title_list.append(title.text)# 获取文章作者和发布时间
for author_time in content.find_all(&#39;p&#39;, attrs&#61;{&#39;class&#39;: &#39;name&#39;}):if len(author_list) <20:author &#61; re.findall(r&#39;(?<&#61;\s)\D&#43;(?&#61;\s\.)&#39;, author_time.text)[0]author_list.append(author.replace(&#39; &#39;, &#39;&#39;))if len(releasetime_list) <20:time &#61; re.findall(r&#39;\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}&#39;, author_time.text)releasetime_list.append(time[0])# 主页面数据清洗
author_clear &#61; []
for i in author_list:if i !&#61; &#39;.&#39;:author_clear.append(i.replace(&#39;\n&#39;, &#39;&#39;).replace(&#39; &#39;, &#39;&#39;))
author_list &#61; author_clear
time_clear &#61; []
for j in releasetime_list:time_clear.append(j.replace(&#39;\n&#39;, &#39;&#39;).replace(&#39; &#39;, &#39;&#39;).replace(&#39;:&#39;, &#39;&#39;))
releasetime_list &#61; time_clear
title_clear &#61; []
for n in title_list:title_clear.append(n.replace(&#39;&#xff1a;&#39;, &#39; &#39;).replace(&#39;&#xff01;&#39;, &#39; &#39;).replace(&#39;|&#39;, &#39; &#39;).replace(&#39;/&#39;, &#39; &#39;).replace(&#39; &#39;, &#39; &#39;))
title_list &#61; title_clear# 访问文章并保存文本信息和图片到指定文件夹
for nums in range(20):text_list &#61; []img_url_list &#61; []article_url &#61; start_url &#43; href_list[nums]response_url &#61; requests.get(article_url, headers&#61;header, timeout&#61;1)html_text &#61; response_url.textsoup_article &#61; BeautifulSoup(html_text, &#39;lxml&#39;)print("正在爬取第{}个页面&#xff01;&#xff01;&#xff01;".format(nums &#43; 1))# 获取子页面文本&#xff08;用find_all方法&#xff09;content_article &#61; soup_article.find_all(&#39;div&#39;, attrs&#61;{&#39;class&#39;: &#39;content&#39;})[-1]text &#61; &#39;&#39;for i in content_article:text &#61; text &#43; i.texttext_list.append(text)# 获取子页面图片链接&#xff08;用select方法&#xff09;soup_article_url &#61; content_article.select(&#39;.pgc-img > img&#39;)for url in soup_article_url:img_url_list.append(url[&#39;src&#39;])# 新建多层文件夹file_name &#61; "建筑档案爬虫文件夹" # 文件夹名称path &#61; r&#39;d:/&#39; &#43; file_nameurl_path_file &#61; path &#43; &#39;/&#39; &#43; title_list[nums] &#43; &#39;/&#39; # 拼接文件夹地址if not os.path.exists(url_path_file):os.makedirs(url_path_file)# 保存子页面图片for index, img_url in enumerate(img_url_list):img_rep &#61; requests.get(img_url, headers&#61;header, timeout&#61;5) # 设置超时时间index &#43;&#61; 1 # 每保存图片一次&#xff0c;显示数量&#43;1img_name &#61; title_list[nums] &#43; &#39; 图片&#39; &#43; &#39;{}&#39;.format(index) # 图片名称img_path &#61; url_path_file &#43; img_name &#43; &#39;.png&#39; # 图片地址with open(img_path, &#39;wb&#39;) as f:f.write(img_rep.content) # 以二进制的方式写入f.close()print(&#39;第{}张图片保存成功&#xff0c;保存地址为&#xff1a;&#39;.format(index), img_path)# 保存网页文本txt_name &#61; str(title_list[nums] &#43; &#39; &#39; &#43; author_list[nums] &#43; &#39; &#39; &#43; releasetime_list[nums]) # 文本名称txt_path &#61; url_path_file &#43; &#39;/&#39; &#43; txt_name &#43; &#39;.txt&#39; # 文本地址with open(txt_path, &#39;w&#39;, encoding&#61;&#39;utf-8&#39;) as f:f.write(str(text_list[0]))f.close()print("该页面文本保存成功,文本地址为&#xff1a;", txt_path)print("爬取成功&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;&#xff01;")print(&#39;\n&#39;)# 主页面信息保存
data &#61; pd.DataFrame({&#39;title&#39;: title_list,&#39;author&#39;: author_list,&#39;time&#39;: releasetime_list,&#39;url&#39;: href_list})
data.to_excel(&#39;{}./data.xls&#39;.format(path), index&#61;False)
print(&#39;保存成功,excel文件地址&#xff1a;&#39;, &#39;{}/data.xls&#39;.format(path))print(&#39;爬取完成!!!!&#39;)
end_time &#61; time.time()
print(&#39;爬取所用时长&#xff1a;&#39;, end_time - start_time)
后续有时间再对该案例扩展防反爬措施&#xff08;ip池、表头池、响应访问&#xff09;、数据处理&#xff08;数据分析、数据可视化&#xff09;等内容
【爬虫实战案例1】基于Requests&#43;Xpath&#43;Pandas简单实现爬虫需求_inganxu-CSDN博客
【爬虫实战案例1】基于Scrapy&#43;Xpath简单实现爬虫需求_inganxu-CSDN博客_scrapy爬虫案例








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 