作者:等待的承诺灬_231 | 来源:互联网 | 2023-07-13 19:56
写过论文的人大都清楚,最终提交的cameraready版本中的字体必须是Type1或TrueType的,而且所有字体都要内嵌到pdf文件中。最近正好遇到这样一个问题,camerar
写过论文的人大都清楚,最终提交的cameraready版本中的字体必须是Type 1或True Type的,而且所有字体都要内嵌到pdf文件中。最近正好遇到这样一个问题,cameraready提交后,编辑发现一些字体没内嵌,只能退回来修改。支持查看字体是否内嵌的工具很多,比如Adobe Reader、Evince、Foxit Reader等等,通常在“文件->属性->字体”这样的菜单下。下图是Evince的截图,可以看到Fonts标签里显示了字体列表,包括字体的类型和是否内嵌。

要找到哪些字体没有内嵌是非常容易的,但要搞清楚这些字体对应哪些内容就不容易了。经验有时候能起些作用,比如采用常用的Latex工具(例如CTex套件、TexEditor、TexStudio、Sublime-Text Latex Tools等等)编译出来的pdf中,正文部分的字体往往都是内嵌的,真正容易出问题的是那些图片,尤其是用Visio等工具生成的图片,这些工具导出pdf的时候,不一定会把字体内嵌。所以,可以打开论文的图片文件夹,把pdf图片挨个点开看看。
如果还是找不到还可以利用一些工具,比如xpdf(http://www.foolabs.com/xpdf/)中的pdffonts。在命令行输入:pdffonts xxx.pdf就能打印出pdf文件使用的所有字体,以及它们是否被内嵌了(下图中emb列)。除此以外,还有一个重要的信息,就是字体对应的编号(下图中的object列)。这个数字描述了在pdf文档中字体的唯一编号,所以通过该数字可以找到使用该字体的内容。
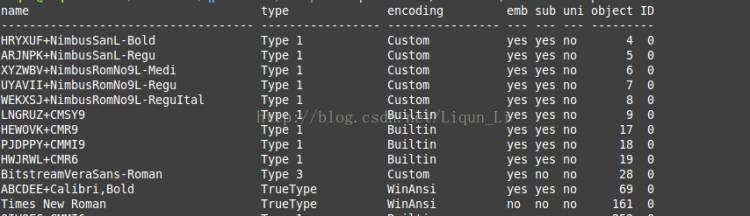
图中显示的Times New Roman字体没有内嵌,并且对应的object编号为161。用文本编辑器(如Vim、Sublime Text、Notepad++等)打开pdf文件后搜索“161 0 obj”,会看到类似下图的结果。在pdf中,obj和endobj之间的部分构成了一个最基本的object单元。要想更多了解pdf的结构,可以参考这篇文章,相比其它文章,作者写得更加浅显易懂。
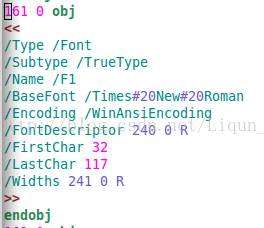
上图中的object只是定义了字体本身,要找到使用该字体的内容还需要在pdf文档中搜索“161 0 R”,看看引用”161 0 obj”的object是什么。按照这个方法,在pdf中找到的内容如下图所示(由于object内容太长,引用的部分没有显示在图中),很容易就能发现字体其实用在图片中。

如果这些字体出现在正文里,可能需要一些额外的步骤,因为pdf的正文(记作stream object)一般是压缩过的(通常采用zlib中的flatecode),所以看到的都是乱码。为了看到这些内容,可以用pdftk或qpdf提供的工具来解压,对应的命令分别为:
pdftk test.pdf output test-d.pdf uncompress
qpdf --stream-data=uncompress input.pdf output.pdf
我在linux下发现pdftk工作不正常,最终是用qpdf解压的,stackoverflow上说可能是由bug造成的,不过用什么工具其实无所谓的。
后记:在了解pdf格式的过程中,发现其实pdf的设计非常灵活,或者说有点灵活过了头,导致编写parser成为一个极其复杂无趣的过程。那些成熟的pdf阅读器都是经过相当长的演化,不断修改才能兼容各种奇葩的pdf格式定义。为什么不把格式定的“死板”一些呢?这样对文件处理很有好处的呀,哪怕牺牲那么点效率。





 京公网安备 11010802041100号
京公网安备 11010802041100号