转至http://blog.csdn.net/zhongkejingwang/article/details/42264479
另一篇很好的文章 http://blog.codinglabs.org/articles/pca-tutorial.html
什么是PCA?
在数据挖掘或者图像处理等领域经常会用到主成分分析,这样做的好处是使要分析的数据的维度降低了,但是数据的主要信息还能保留下来,并且,这些变换后的维两两不相关!至于为什么?那就接着往下看。在本文中,将会很详细的解答这些问题:PCA、SVD、特征值、奇异值、特征向量这些关键词是怎么联系到一起的?又是如何在一个矩阵上体现出来?它们如何决定着一个矩阵的性质?能不能用一种直观又容易理解的方式描述出来?
数据降维
为了说明什么是数据的主成分,先从数据降维说起。数据降维是怎么回事儿?假设三维空间中有一系列点,这些点分布在一个过原点的斜面上,如果你用自然坐标系x,y,z这三个轴来表示这组数据的话,需要使用三个维度,而事实上,这些点的分布仅仅是在一个二维的平面上,那么,问题出在哪里?如果你再仔细想想,能不能把x,y,z坐标系旋转一下,使数据所在平面与x,y平面重合?这就对了!如果把旋转后的坐标系记为x',y',z',那么这组数据的表示只用x'和y'两个维度表示即可!当然了,如果想恢复原来的表示方式,那就得把这两个坐标之间的变换矩阵存下来。这样就能把数据维度降下来了!但是,我们要看到这个过程的本质,如果把这些数据按行或者按列排成一个矩阵,那么这个矩阵的秩就是2!这些数据之间是有相关性的,这些数据构成的过原点的向量的最大线性无关组包含2个向量,这就是为什么一开始就假设平面过原点的原因!那么如果平面不过原点呢?这就是数据中心化的缘故!将坐标原点平移到数据中心,这样原本不相关的数据在这个新坐标系中就有相关性了!有趣的是,三点一定共面,也就是说三维空间中任意三点中心化后都是线性相关的,一般来讲n维空间中的n个点一定能在一个n-1维子空间中分析!所以,不要说数据不相关,那是因为坐标没选对!
上面这个例子里把数据降维后并没有丢弃任何东西,因为这些数据在平面以外的第三个维度的分量都为0。现在,我假设这些数据在z'轴有一个很小的抖动,那么我们仍然用上述的二维表示这些数据,理由是我认为这两个轴的信息是数据的主成分,而这些信息对于我们的分析已经足够了,z'轴上的抖动很有可能是噪声,也就是说本来这组数据是有相关性的,噪声的引入,导致了数据不完全相关,但是,这些数据在z'轴上的分布与原点构成的夹角非常小,也就是说在z'轴上有很大的相关性,综合这些考虑,就可以认为数据在x',y'轴上的投影构成了数据的主成分!
现在,关于什么是数据的主成分已经很好的回答了。下面来看一个更具体的例子。
下面是一些学生的成绩:
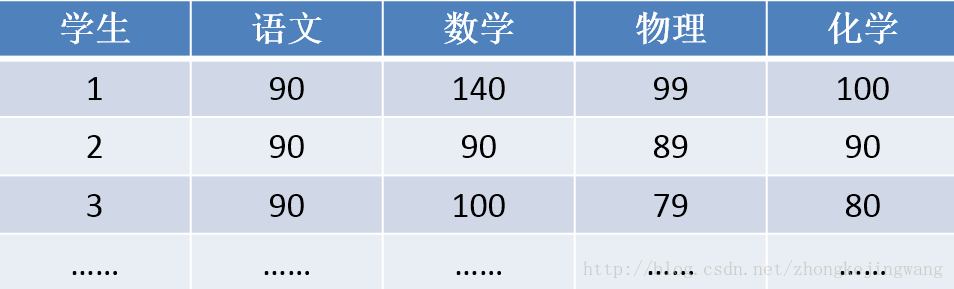
首先,假设这些科目成绩不相关,也就是说某一科考多少份与其他科没有关系。那么一眼就能看出来,数学、物理、化学这三门成绩构成了这组数据的主成分(很显然,数学作为第一主成分,因为数学成绩拉的最开)。为什么一眼能看出来?因为坐标轴选对了!下面再看一组数据,还能不能一眼看出来:
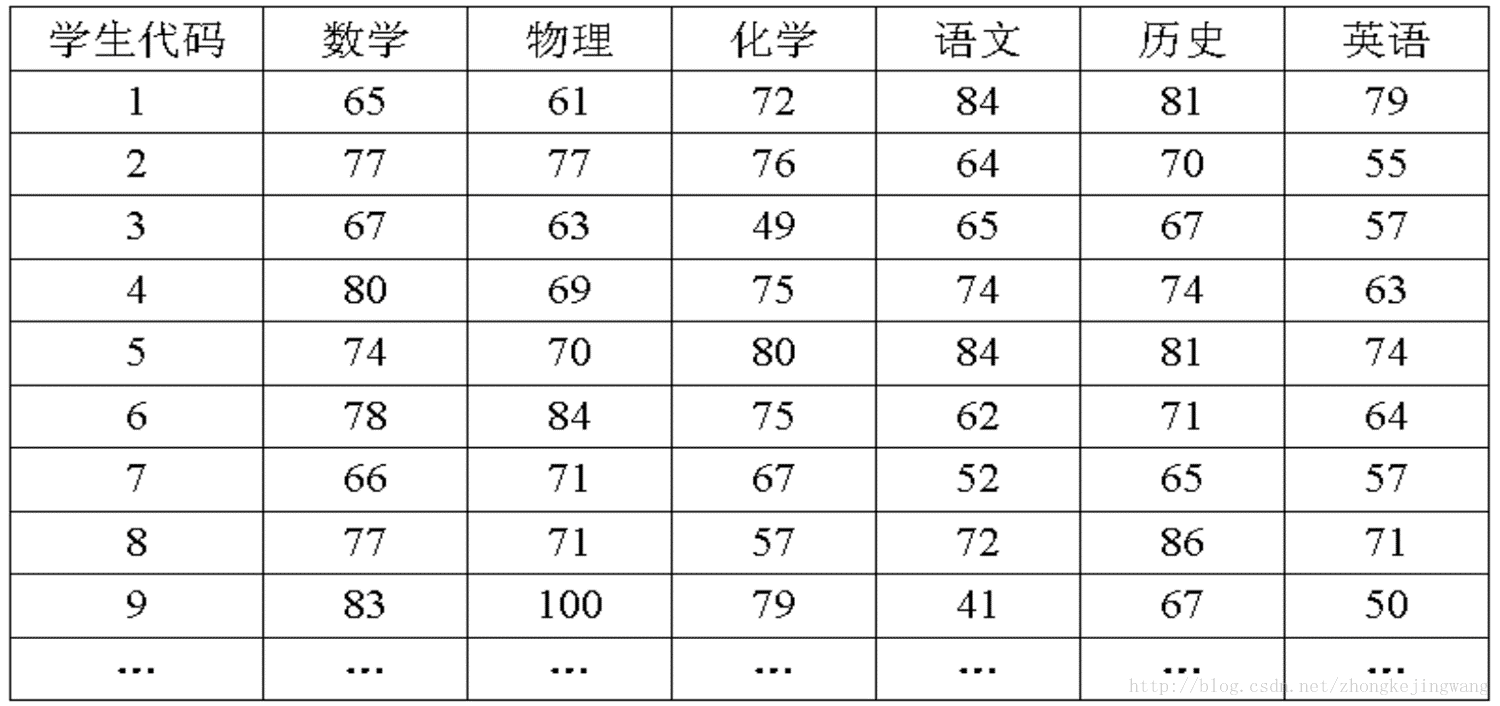
是不是有点凌乱了?你还能看出来数据的主成分吗?显然不能,因为在这坐标系下数据分布很散乱。所以说,看到事物的表象而看不到其本质,是因为看的角度有问题!如果把这些数据在空间中画出来,也许你一眼就能看出来。但是,对于高维数据,能想象其分布吗?就算能描述分布,如何精确地找到这些主成分的轴?如何衡量你提取的主成分到底占了整个数据的多少信息?要回答这些问题,需要将上面的分析上升到理论层面。接下来就是PCA的理论分析。
PCA推导以下面这幅图开始我们的推导:
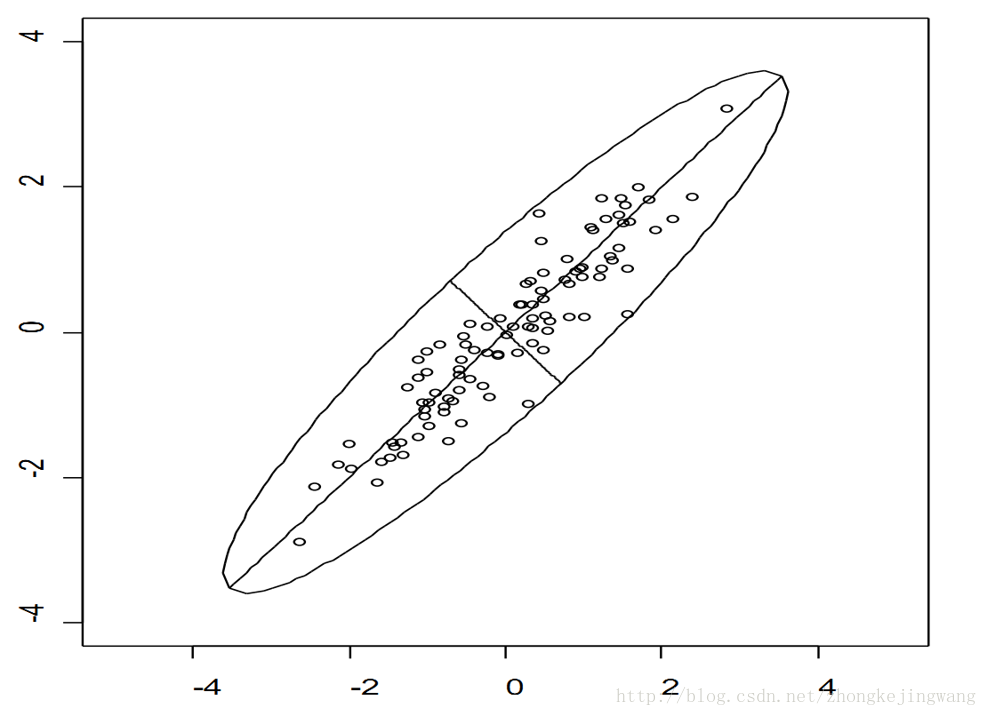
上面是二维空间中的一组数据,很明显,数据的分布让我们很容易就能看出来主成分的轴(简称主轴)的大致方向。下面的问题就是如何通过数学计算找出主轴的方向。来看这张图:
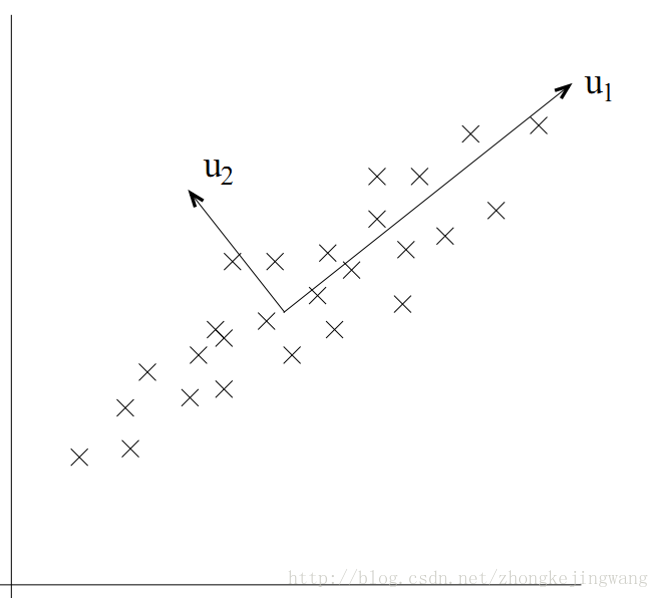
现在要做的事情就是寻找u1的方向,对于这点,我想好多人都有经验,这不就是以前用最小二乘法拟合数据时做的事情吗!对,最小二乘法求出来的直线(二维)的方向就是u1的方向!那u2的方向呢?因为这里是二维情况,所以u2方向就是跟u1垂直的方向,对于高维数据,怎么知道u2的方向?经过下面的理论推导,各个主轴都能确定下来。
给定一组数据:(如无说明,以下推导中出现的向量都是默认是列向量)
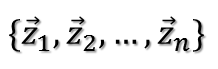
将其中心化后表示为:
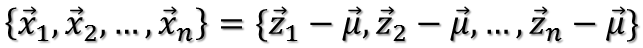
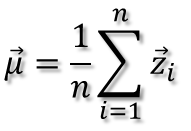
中心化后的数据在第一主轴u1方向上分布散的最开,也就是说在u1方向上的投影的绝对值之和最大(也可以说方差最大),计算投影的方法就是将x与u1做内积,由于只需要求u1的方向,所以设u1是单位向量。
也就是最大化下式:
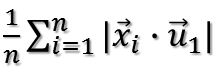
也即最大化:
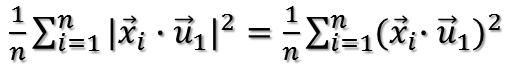
解释:平方可以把绝对值符号拿掉,光滑曲线处理起来方便。
两个向量做内积可以转化成矩阵乘法:
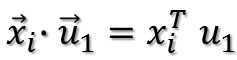
所以目标函数可以表示为:
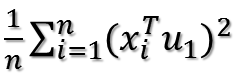
括号里面就是矩阵乘法表示内积,转置以后的行向量乘以列向量得到一个数。因为一个数的转置还是其本身,所以又可以将目标函数化为:
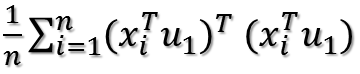
这样就可以把括号去掉!去掉以后变成:
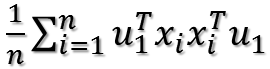
由于u1和i无关,可以把它拿到求和符外面:
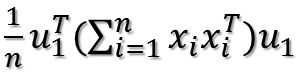
注意,其实括号里面是一个矩阵乘以自身的转置,这个矩阵形式如下:
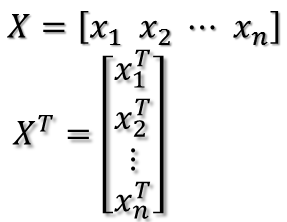
X矩阵的第i列就是xi,于是有:
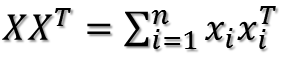
所以目标函数最后化为:
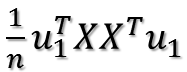
上式到底有没有最大值呢?如果没有前面的1/n,那就是就是一个标准的二次型!并且XX'(为了方便,用'表示转置)得到的矩阵是一个半正定的对称阵!为什么?首先XX'是对称阵,因为(XX')'=XX',下面证明它是半正定,什么是半正定?就是所有特征值大于等于0。
假设XX'的某一个特征值为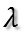
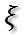
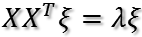
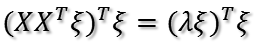
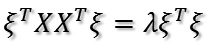
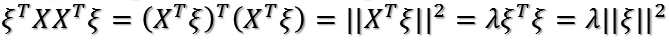
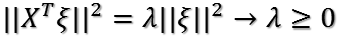
证明完毕!对于半正定阵的二次型,存在最大值!现在问题就是如何求目标函数的最大值?以及取最大值时u1的方向?下面介绍两种方法。
方法一 拉格朗日乘数法
目标函数和约束条件构成了一个最大化问题:
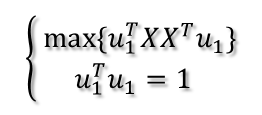
构造拉格朗日函数:
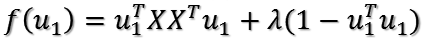
对u1求导
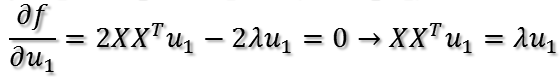
显然,u1即为XX'特征值
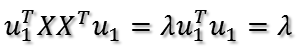
所以,如果取最大的那个特征值,那么得到的目标值就最大。有可能你会有疑问,为什么一阶导数为0就是极大值呢?那么再求二阶导数:

二阶导数半负定,所以,目标函数在最大特征值所对应的特征向量上取得最大值!所以,第一主轴方向即为第一大特征值对应的特征向量方向。第二主轴方向为第二大特征值对应的特征向量方向,以此类推,证明类似。
下面介绍第二种方法
方法二 奇异值法
这方法是从矩阵分析里面总结的,随便取个名叫奇异值法。
首先,对于向量x,其二范数(也就是模长)的平方为:
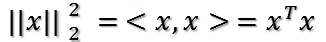
所以有:
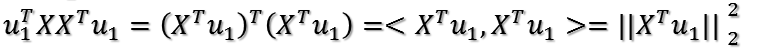
把二次型化成一个范数的形式,最大化上式也即这个问题:对于一个矩阵,它对一个向量做变换,变换前后的向量的模长伸缩尺度如何才能最大?这个很有趣,简直就是把矩阵的真面目给暴露出来了。为了给出解答,下面引入矩阵分析中的一个定理:
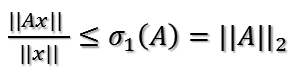
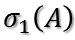
考察对称阵
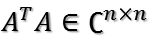
设
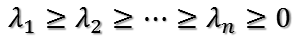
为其n个特征值,并令与之对应的单位特征向量为:
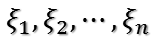
对了,忘了提醒,对称阵不同特征值对应的特征向量两两正交!这组特征向量构成了空间中的一组单位正交基。
任意取一个向量x,将其表示为
则
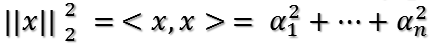
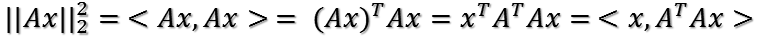
将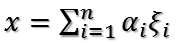
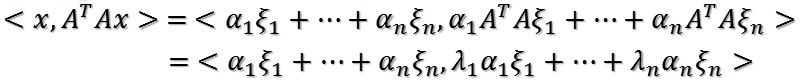
由于这些单位特征向量两两正交,只有相同的做内积为1,不同的做内积为0.所以上式做内积出来的结果为:
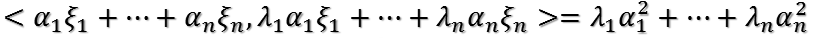
根据特征值的大小关系有
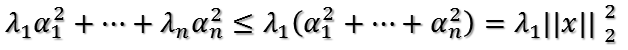
所以
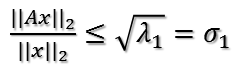
定理得证!
显然,当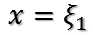
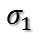
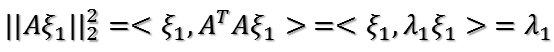
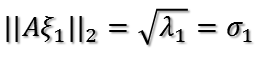
再回到我们的问题,需要最大化:
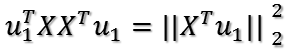
将X'代入上面证明过程中的矩阵A,则u1的方向即为A'A=(X')'X'=XX'对大特征值对应的特征向量的方向!
所以第一主轴已经找到,第二主轴为次大特征值对应的特征向量的方向,以此类推。
两种方法殊途同归,现在来解答关于主成分保留占比的问题。上面我们知道第一主轴对应的最大值是最大奇异值(也就是AA'最大特征值开平方),第二主轴对应的最大值是次大奇异值,以此类推。那么假设取前r大奇异值对应的主轴作为提取的主成分,则提取后的数据信息占比为:
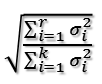
分子是前r大奇异值的平方和,分母是所有奇异值的平方和。
到此,主成分分析PCA就讲完了,文章最后提到了奇异值,关于这个,后面的奇异值分解(SVD)文章将会详细讲解并给出其具体应用!









 京公网安备 11010802041100号
京公网安备 11010802041100号