转载https:www.cnblogs.comshixiangwanp7532830.html蓝鲸王子常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度
转载https://www.cnblogs.com/shixiangwan/p/7532830.html
蓝鲸王子
常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)
我们每个人都会在我们的生活或者工作中遇到各种各样的最优化问题,比如每个企业和个人都要考虑的一个问题“在一定成本下,如何使利润最大化”等。最优化方法是一种数学方法,它是研究在给定约束之下如何寻求某些因素(的量),以使某一(或某些)指标达到最优的一些学科的总称。随着学习的深入,博主越来越发现最优化方法的重要性,学习和工作中遇到的大多问题都可以建模成一种最优化模型进行求解,比如我们现在学习的机器学习算法,大部分的机器学习算法的本质都是建立优化模型,通过最优化方法对目标函数(或损失函数)进行优化,从而训练出最好的模型。常见的最优化方法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法等等。
1. 梯度下降法(Gradient Descent)
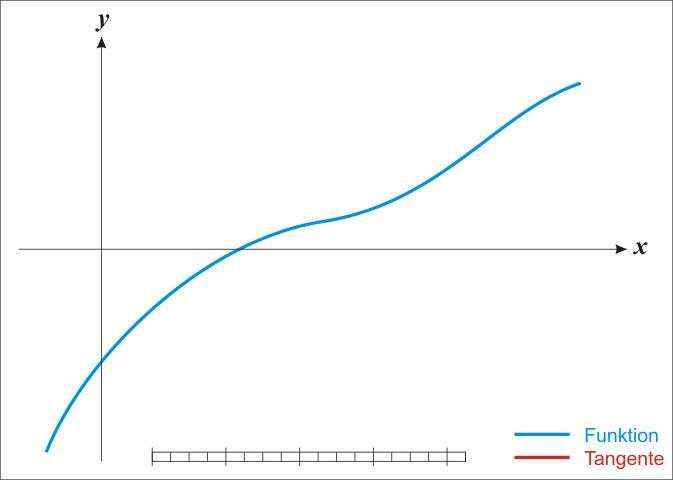
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:
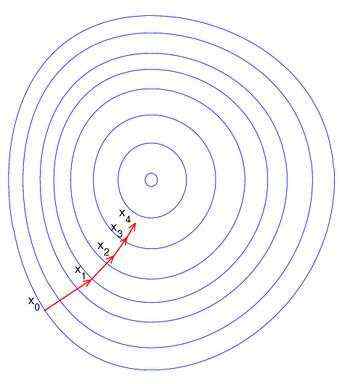
梯度下降法的缺点:
(1)靠近极小值时收敛速度减慢,如下图所示;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降。
从上图可以看出,梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
比如对一个线性回归(Linear Logistics)模型,假设下面的h(x)是要拟合的函数,J(theta)为损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的样本个数,n是特征的个数。
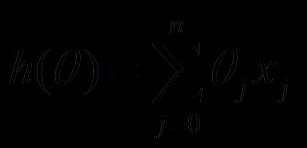

1)批量梯度下降法(Batch Gradient Descent,BGD)
(1)将J(theta)对theta求偏导,得到每个theta对应的的梯度:

我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
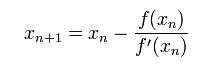
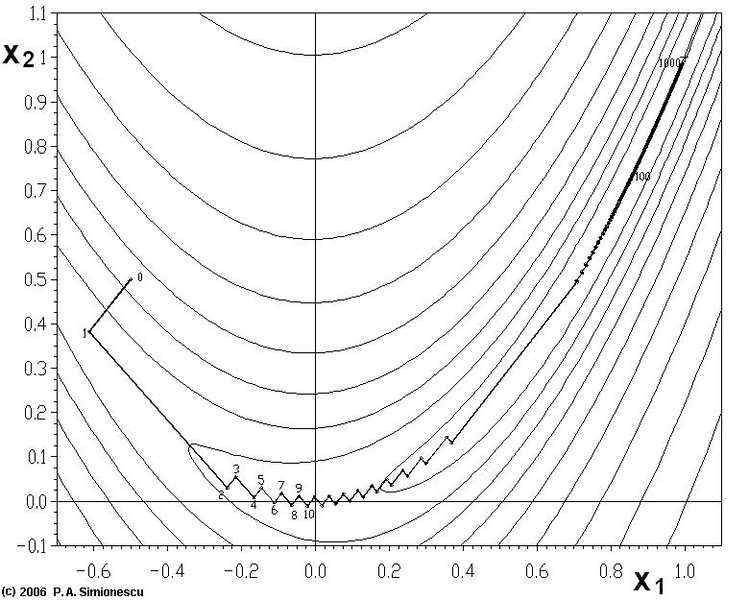
已经证明,如果f ' 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ' (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。下图为一个牛顿法执行过程的例子。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:
牛顿法搜索动态示例图:
关于牛顿法和梯度下降法的效率对比:
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
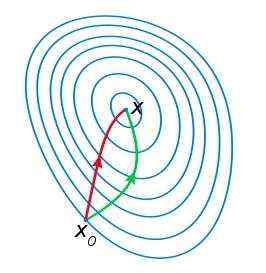
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
2)拟牛顿法(Quasi-Newton Methods)
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型:
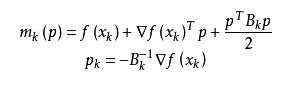
这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点:
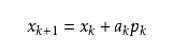
其中我们要求步长ak 满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hesse矩阵Bk
代替真实的Hesse矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk
的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:
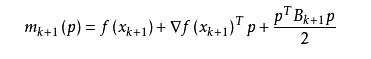
我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求
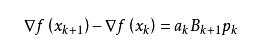
从而得到
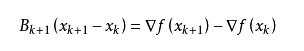
这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。
3. 共轭梯度法(Conjugate Gradient)
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
具体的实现步骤请参加wiki百科共轭梯度法。
下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
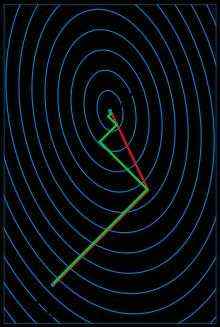
注:绿色为梯度下降法,红色代表共轭梯度法
4. 启发式优化方法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
5. 解决约束优化问题——拉格朗日乘数法
有关拉格朗日乘数法的介绍请见另一篇博客:《拉格朗日乘数法》
6 LBFGS
转载:http://www.hankcs.com/ml/l-bfgs.html
数值优化是许多机器学习算法的核心。一旦你确定用什么模型,并且准备好了数据集,剩下的工作就是训练了。估计模型的参数(训练模型)通常归结为最小化一个多元函数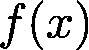 ,其中输入
,其中输入 是一个高维向量,也就是模型参数。换句话说,如果你求解出:
是一个高维向量,也就是模型参数。换句话说,如果你求解出:
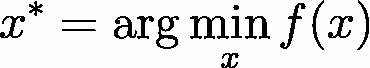
那么*就是最佳的模型参数(当然跟你选择了什么目标函数有关系)。
在这篇文章中,我将重点放在讲解L-BFGS算法的无约束最小化上,该算法在一些能用上批处理优化的ML问题中特别受欢迎。对于更大的数据集,则常用SGD方法,因为SGD只需要很少的迭代次数就能达到收敛。在以后的文章中,我可能会涉及这些技术,包括我个人最喜欢的AdaDelta 。
注 : 在整个文章中,我会假设你记得多元微积分。所以,如果你不记得什么是梯度或海森矩阵,你得先复习一下。
牛顿法
大多数数值优化算法都是迭代式的,它们产生一个序列,该序列最终收敛于 ,使得达到全局最小化。假设,我们有一个估计
,使得达到全局最小化。假设,我们有一个估计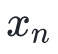 ,我们希望我们的下一个估计
,我们希望我们的下一个估计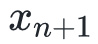 有这种属性:
有这种属性: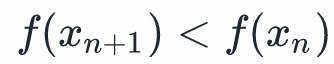 。
。
牛顿的方法是在点附近使用二次函数近似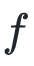 。假设是二次可微的,我们可以用在点
。假设是二次可微的,我们可以用在点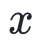 的泰勒展开来近似。
的泰勒展开来近似。
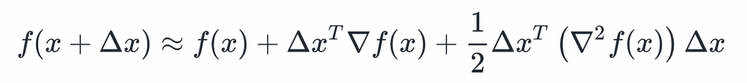
其中,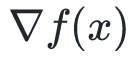 和
和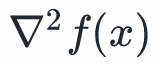 分别为目标函数在点处的梯度和Hessian矩阵。当
分别为目标函数在点处的梯度和Hessian矩阵。当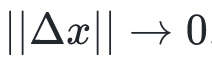 时,上面的近似展开式是成立的。你可能记得微积分中一维泰勒多项式展开,这是其推广。
时,上面的近似展开式是成立的。你可能记得微积分中一维泰勒多项式展开,这是其推广。
为了简化符号,将上述二次近似记为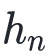 ,我们把生成这样的二次近似的迭代算法中的一些概念简记如下:
,我们把生成这样的二次近似的迭代算法中的一些概念简记如下:
不失一般性,我们可以记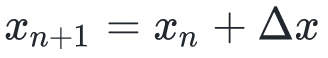 ,那么上式可以写作:
,那么上式可以写作:
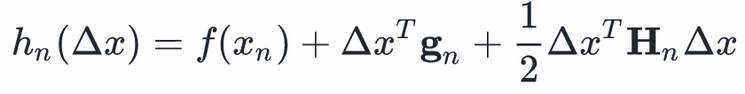
其中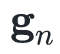 和
和 分别表示目标函数在点处的梯度和Hessian矩阵。
分别表示目标函数在点处的梯度和Hessian矩阵。
我们想找一个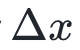 ,使得在的二次近似最小。上式对求导:
,使得在的二次近似最小。上式对求导:
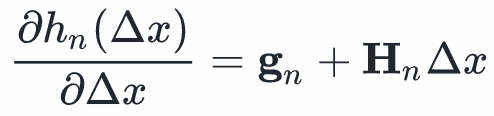
任何使得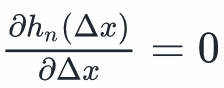 的
的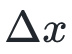 都是
都是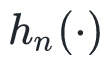 的局部极值点,如果我们假设是凸函数,则是正定的,那么局部极值点就是全局极值点(凸二次规划)。
的局部极值点,如果我们假设是凸函数,则是正定的,那么局部极值点就是全局极值点(凸二次规划)。
解出:
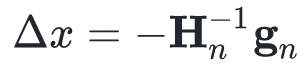
这就得到了一个很好的搜索方向,在实际应用中,我们一般选择一个步长α,即按照下式更新:
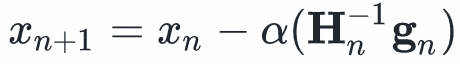
使得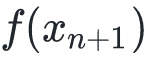 相比的减小量最大化。
相比的减小量最大化。
迭代算法伪码:
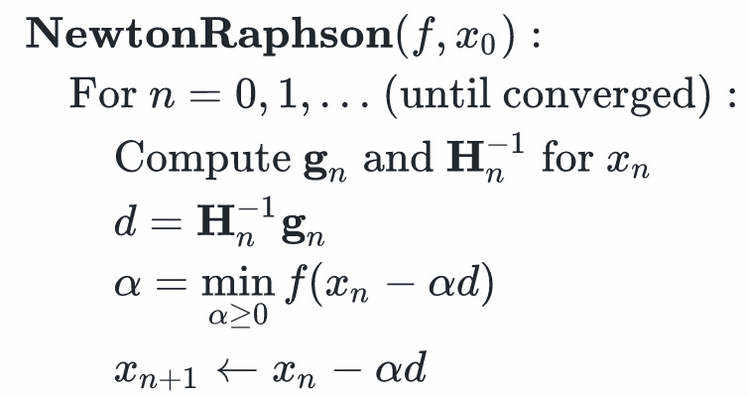
步长α的确定可以采用任何line search算法,其中最简单的一种是backtracking line search。该算法简单地选取越来越小的步长α,直到的值小到满意为止。关于line search算法的详情请参考 Line Search Methods.pdf或Lecture 5- Gradient Descent.pdf。
Line Search Methods.pdf或Lecture 5- Gradient Descent.pdf。
在软件工程上,我们可以将牛顿法视作实现了下列Java接口的一个黑盒子:
- public interface TwiceDifferentiableFunction
- {
- // compute f(x)
- double valueAt(double[] x);
-
- // compute grad f(x)
- double[] gradientAt(double[] x);
-
- // compute inverse hessian H^-1
- double[][] inverseHessian(double[] x);
- }
如果你有兴趣,你还可以通过一些枯燥无味的数学公式,证明对任意一个凸函数,上述算法一定可以收敛到一个唯一的最小值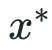 ,且不受初值
,且不受初值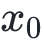 的影响。对于非凸函数,上述算法仍然有效,但只能保证收敛到一个局部极小值。在上述算法于非凸函数的实际应用中,用户需要注意初值的选取以及其他算法细节。
的影响。对于非凸函数,上述算法仍然有效,但只能保证收敛到一个局部极小值。在上述算法于非凸函数的实际应用中,用户需要注意初值的选取以及其他算法细节。
巨大的海森矩阵
牛顿法最大的问题在于我们必须计算海森矩阵的逆。注意在机器学习应用中,的输入的维度常常与模型参数对应。十万维度的参数并不少见(SVM中文文本分类取词做特征的话,就在十万这个量级),在一些图像识别的场景中,参数可能上十亿。所以,计算海森矩阵或其逆并不现实。对许多函数而言,海森矩阵可能根本无法计算,更不用说表示出来求逆了。
所以,在实际应用中牛顿法很少用于大型的优化问题。但幸运的是,即便我们不求出在的精确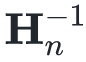 ,而使用一个近似的替代值,上述算法依然有效。
,而使用一个近似的替代值,上述算法依然有效。
拟牛顿法
如果不求解在的精确,我们要使用什么样的近似呢?我们使用一种叫QuasiUpdate的策略来生成的近似,先不管QuasiUpdate具体是怎么做的,有了这个策略,牛顿法进化为如下的拟牛顿法:

跟牛顿法相比,只是把的计算交给了QuasiUpdate。为了辅助QuasiUpdate,计算了几个中间变量。QuasiUpdate只需要上个迭代的、输入和梯度的变化量(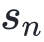 和
和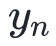 )。如果QuasiUpdate能够返回精确的
)。如果QuasiUpdate能够返回精确的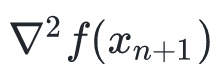 的逆,则拟牛顿法等价于牛顿法。
的逆,则拟牛顿法等价于牛顿法。
在软件工程上,我们又可以写一个黑盒子接口,该接口不再需要计算海森矩阵的逆,只需要在内部更新它,再提供一个矩阵乘法的接口即可。事实上,内部如何处理,外部根本无需关心。用Java表示如下:
- public interface DifferentiableFunction
- {
- // compute f(x)
- double valueAt(double[] x);
-
- // compute grad f(x)
- double[] gradientAt(double[] x);
- }
-
- public interface QuasiNewtonApproximation
- {
- // update the H^{-1} estimate (using x_{n+1}-x_n and grad_{n+1}-grad_n)
- void update(double[] deltaX, double[] deltaGrad);
-
- // H^{-1} (direction) using the current H^{-1} estimate
- double[] inverseHessianMultiply(double[] direction);
- }
注意我们唯一用到海森矩阵的逆的地方就是求它与梯度的乘积,所以我们根本不需要在内存中将其显式地、完全地表示出来。这对接下来要阐述的L-BFGS特别有用。如果你对实现细节感兴趣,可以看看作者的golang实现。
近似海森矩阵
QuasiUpdate到底要如何近似海森矩阵呢?如果我们让QuasiUpdate忽略输入参数,直接返回单位矩阵,那么拟牛顿法就退化成了梯度下降法了,因为函数减小的方向永远是梯度。梯度下降法依然能保证凸函数收敛到全局最优对应的,但直觉告诉我们,梯度下降法没有利用到的二阶导数信息,收敛速度肯定更慢了。
我们先把的二次近似写在下面,从这里找些灵感。
Secant Condition
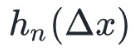 的一个性质是,它的梯度与在处的梯度一致(近似函数的梯度与原函数的梯度一致,这才叫近似嘛)。也就是说我们希望保证:
的一个性质是,它的梯度与在处的梯度一致(近似函数的梯度与原函数的梯度一致,这才叫近似嘛)。也就是说我们希望保证:
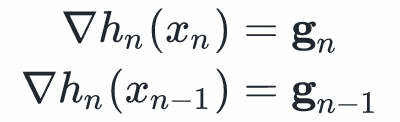
我们做个减法:
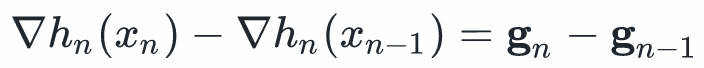
由中值定理,我们有:
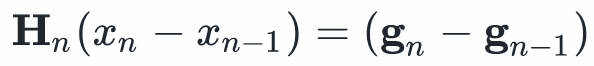
这个式子就是所谓的Secant Condition,该条件保证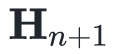 至少对
至少对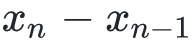 而言是近似海森矩阵的。
而言是近似海森矩阵的。
等式两边同时乘以,并且由于我们定义过:

于是我们得到:
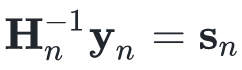
对称性
由定义知海森矩阵是函数的二阶偏导数矩阵,即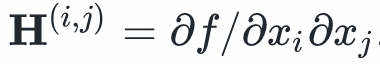 ,所以海森矩阵一定是对称的。
,所以海森矩阵一定是对称的。
BFGS更新
形式化地讲,我们希望至少满足上述两个条件:
-
对和而言满足Secant Condition
-
满足对称性
给定上述两个条件,我们还希望相较于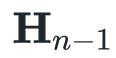 的变化量最小。这类似“ MIRA 更新”,我们有许多满足条件的选项,但我们只选那个变化最小的。这种约束形式化地表述如下:
的变化量最小。这类似“ MIRA 更新”,我们有许多满足条件的选项,但我们只选那个变化最小的。这种约束形式化地表述如下:
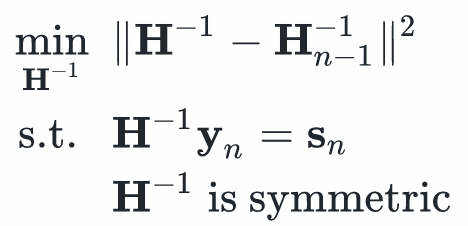
上面的范数 表示weighted frobenius norm。这个约束最小化问题的解是:
表示weighted frobenius norm。这个约束最小化问题的解是:
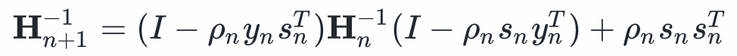
式中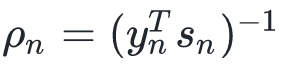 。我不知道如何推导它,推导的话需要用很多符号,并且费时费力。
。我不知道如何推导它,推导的话需要用很多符号,并且费时费力。
这种更新算法就是著名的Broyden–Fletcher–Goldfarb–Shanno (BFGS)算法,该算法是取发明者名字的首字母命名的。

关于BFGS,有一些需要注意的点:
把这些知识放到一起,我们就得出了BFGS更新的算法,给定方向d,该算法可以计算出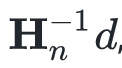 ,却不需要求矩阵,只需要按照上述表达式不断地递推即可:
,却不需要求矩阵,只需要按照上述表达式不断地递推即可:

由于的唯一作用就是计算 ,我们只需用该更新算法就能实现拟牛顿法。
,我们只需用该更新算法就能实现拟牛顿法。
L-BFGS:省内存的BFGS
BFGS拟牛顿近似算法虽然免去了计算海森矩阵的烦恼,但是我们仍然需要保存每次迭代的和的历史值。这依然没有减轻内存负担,要知道我们选用拟牛顿法的初衷就是减小内存占用。
L-BFGS是limited BFGS的缩写,简单地只使用最近的m个和记录值。也就是只储存 和
和 ,用它们去近似计算。初值
,用它们去近似计算。初值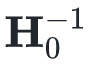 依然可以选取任意对称的正定矩阵。
依然可以选取任意对称的正定矩阵。
L-BFGS改进算法
在实际应用中有许多L-BFGS的改进算法。对不可微分的函数,可以用 othant-wise 的L-BFGS改进算法来训练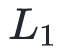 正则损失函数。
正则损失函数。
不在大型数据集上使用L-BFGS的原因之一是,在线算法可能收敛得更快。这里甚至有一个L-BFGS的在线学习算法,但据我所知,在大型数据集上它们都不如一些SGD的改进算法(包括 AdaGrad 或 AdaDelta)的表现好。
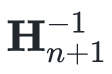 就一定是正定的。所以我们只需要选择一个正定的
就一定是正定的。所以我们只需要选择一个正定的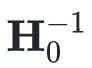 即可,甚至可以选择单位矩阵。
即可,甚至可以选择单位矩阵。






 京公网安备 11010802041100号
京公网安备 11010802041100号