大吉大利,准备吃鸡!
你是否玩儿了好几个月的吃鸡,依旧是落地成盒?
是否常常不得知自己如何被打、莫名其妙的挂了?

还没有吃过鸡/(ㄒoㄒ)/~~总是不明不白的就被别的玩家杀了
!!!∑(゚Д゚ノ)ノ能进前二十就已经很不错了
今天小编带来了福利奥O(≧▽≦)O

大吉大利,今晚吃鸡~
打人时要坚持一个原则,先打对你来说最危险的目标。
(不一定是近点的目标,大部分情况是先近后远)

那么我们就用 Python 和 R 做数据分析来回答以下的灵魂发问?
首先来看下数据:
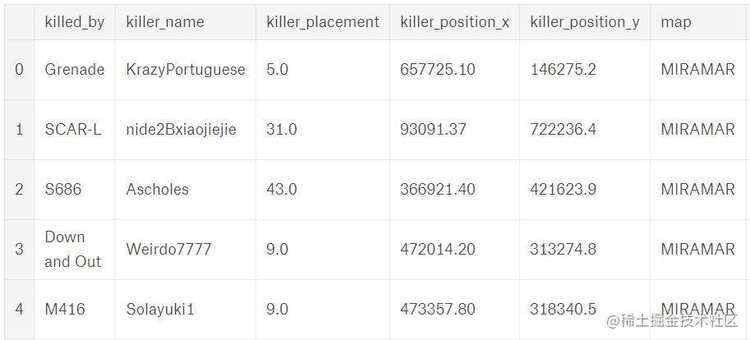
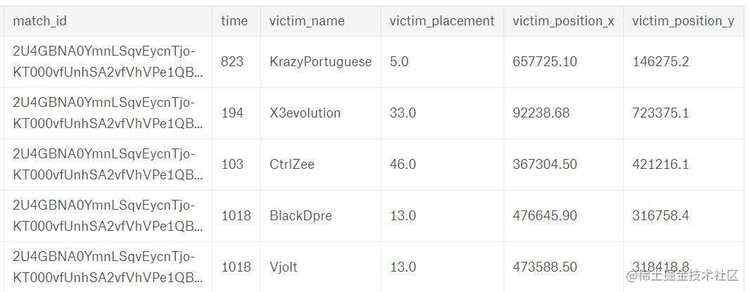
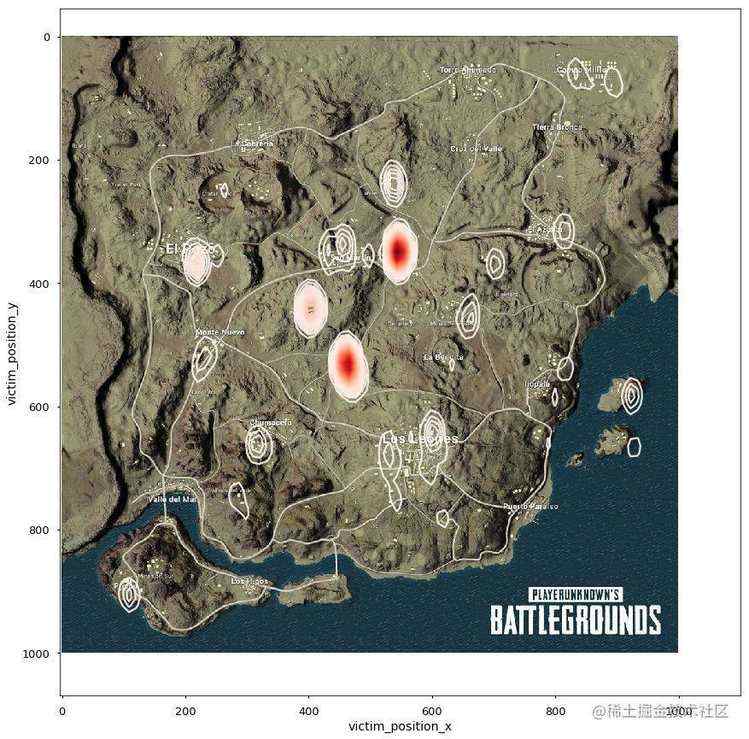
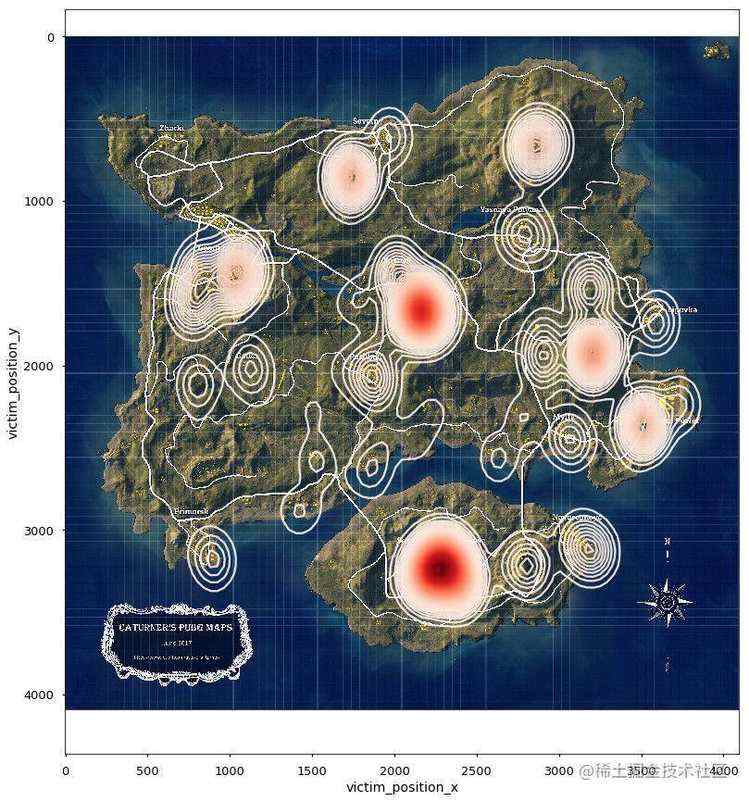
一、跳哪儿危险?
对于我这样一直喜欢苟着的良心玩家,在经历了无数次落地成河的惨痛经历后,我是坚决不会选择跳P城这样楼房密集的城市,穷归穷但保命要紧。所以我们决定统计一下到底哪些地方更容易落地成河?我们筛选出在前100秒死亡的玩家地点进行可视化分析。激情沙漠地图的电站、皮卡多、别墅区、依波城最为危险,火车站、火电厂相对安全。绝地海岛中P城、军事基地、学校、医院、核电站、防空洞都是绝对的危险地带。物质丰富的G港居然相对安全。
1 import numpy as np
2 import matplotlib.pyplot as plt
3 import pandas as pd
4 import seaborn as sns
5 from scipy.misc.pilutil import imread
6 import matplotlib.cm as cm
7
8 #导入部分数据 9deaths1 = pd.read_csv("deaths/kill_match_stats_final_0.csv")
10 deaths2 = pd.read_csv("deaths/kill_match_stats_final_1.csv")
11
12 deaths = pd.concat([deaths1, deaths2])
13
14 #打印前5列,理解变量
15 print (deaths.head(),'\n',len(deaths))
16
17 #两种地图
18 miramar = deaths[deaths["map"] == "MIRAMAR"]
19 erangel = deaths[deaths["map"] == "ERANGEL"]
20
21 #开局前100秒死亡热力图22 position_data = ["killer_position_x","killer_position_y","victim_position_x","victim_position_y"]
23 for position in position_data:
24 miramar[position] = miramar[position].apply(lambda x: x*1000/800000)
25 miramar = miramar[miramar[position] != 0]
26
27 erangel[position] = erangel[position].apply(lambda x: x*4096/800000)
28 erangel = erangel[erangel[position] != 0]
29
30 n = 50000
31 mira_sample &#61; miramar[miramar["time"] < 100].sample(n)
32 eran_sample &#61; erangel[erangel["time"] < 100].sample(n)
33
34 # miramar热力图35bg &#61; imread("miramar.jpg")
36 fig, ax &#61; plt.subplots(1,1,figsize&#61;(15,15))
37 ax.imshow(bg)
38 sns.kdeplot(mira_sample["victim_position_x"], mira_sample["victim_position_y"],n_levels&#61;100, cmap&#61;cm.Reds, alpha&#61;0.9)
39
40 # erangel热力图41bg &#61; imread("erangel.jpg")
42 fig, ax &#61; plt.subplots(1,1,figsize&#61;(15,15))
43 ax.imshow(bg)
44 sns.kdeplot(eran_sample["victim_position_x"], eran_sample["victim_position_y"], n_levels&#61;100,cmap&#61;cm.Reds, alpha&#61;0.9)
二、苟着还是出去干&#xff1f;
我到底是苟在房间里面还是出去和敌人硬拼&#xff1f;这里因为比赛的规模不一样&#xff0c;这里选取参赛人数大于90的比赛数据&#xff0c;然后筛选出团队team_placement即最后成功吃鸡的团队数据&#xff1a;
先计算了吃鸡团队平均击杀敌人的数量&#xff0c;这里剔除了四人模式的比赛数据&#xff0c;因为人数太多的团队会因为数量悬殊平均而变得没意义&#xff1b;
所以我们考虑通过分组统计每一组吃鸡中存活到最后的成员击杀敌人的数量&#xff0c;但是这里发现数据统计存活时间变量是按照团队最终存活时间记录的&#xff0c;所以该想法失败&#xff1b;
最后统计每个吃鸡团队中击杀人数最多的数量统计&#xff0c;这里剔除了单人模式的数据&#xff0c;因为单人模式的数量就是每组击杀最多的数量。最后居然发现还有击杀数量达到60的&#xff0c;怀疑是否有开挂。想要吃鸡还是得出去练枪法&#xff0c;光是苟着是不行的。

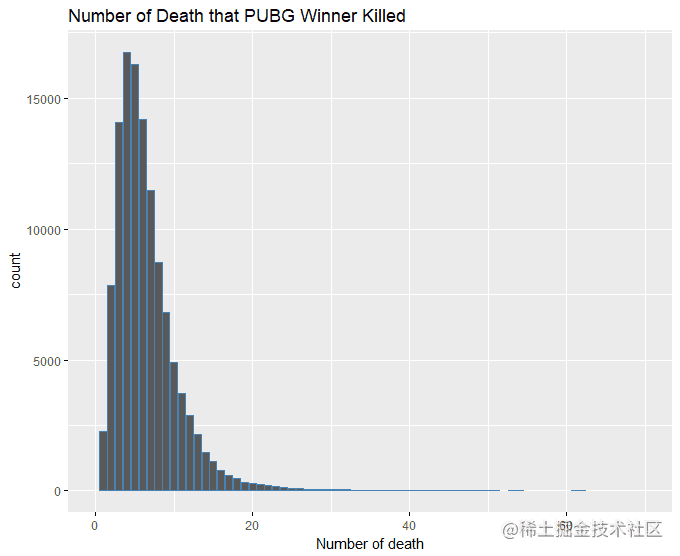
1 library(dplyr)
2 library(tidyverse)
3 library(data.table)
4 library(ggplot2)
5 pubg_full <- fread("../agg_match_stats.csv")
6 # 吃鸡团队平均击杀敌人的数量
7 attach(pubg_full)
8 pubg_winner <- pubg_full %>% filter(team_placement&#61;&#61;1&party_size<4&game_size>90)
9 detach(pubg_full)
10 team_killed <- aggregate(pubg_winner$player_kills, by&#61;list(pubg_winner$match_id,pubg_winner$team_id), FUN&#61;"mean")
11 team_killed$death_num <- ceiling(team_killed$x)
12 ggplot(data &#61; team_killed) &#43; geom_bar(mapping &#61; aes(x &#61; death_num, y &#61; ..count..), color&#61;"steelblue") &#43;
13 xlim(0,70) &#43; labs(title &#61; "Number of Death that PUBG Winner team Killed", x&#61;"Number of death")
14
15 # 吃鸡团队最后存活的玩家击杀数量
16 pubg_winner <- pubg_full %>% filter(pubg_full$team_placement&#61;&#61;1) %>% group_by(match_id,team_id)
17 attach(pubg_winner)
18 eam_leader <- aggregate(player_survive_time~player_kills, data &#61; pubg_winner, FUN&#61;"max")
19 detach(pubg_winner)
20
21 # 吃鸡团队中击杀敌人最多的数量22 pubg_winner <- pubg_full %>% filter(pubg_full$team_placement&#61;&#61;1&pubg_full$party_size>1)
23 attach(pubg_winner)
24 team_leader <- aggregate(player_kills, by&#61;list(match_id,team_id), FUN&#61;"max")
25 detach(pubg_winner)
26 ggplot(data &#61; team_leader) &#43; geom_bar(mapping &#61; aes(x &#61; x, y &#61; ..count..), color&#61;"steelblue") &#43;
27 xlim(0,70) &#43; labs(title &#61; "Number of Death that PUBG Winner Killed", x&#61;"Number of death")
28
三、哪一种武器干掉的玩家多&#xff1f;
运气好挑到好武器的时候&#xff0c;你是否犹豫选择哪一件&#xff1f;从图上来看&#xff0c;M416和SCAR是不错的武器&#xff0c;也是相对容易能捡到的武器&#xff0c;大家公认Kar98k是能一枪毙命的好枪&#xff0c;它排名比较靠后的原因也是因为这把枪在比赛比较难得&#xff0c;而且一下击中敌人也是需要实力的&#xff0c;像我这种捡到98k还装上8倍镜但没捂热乎1分钟的玩家是不配得到它的。
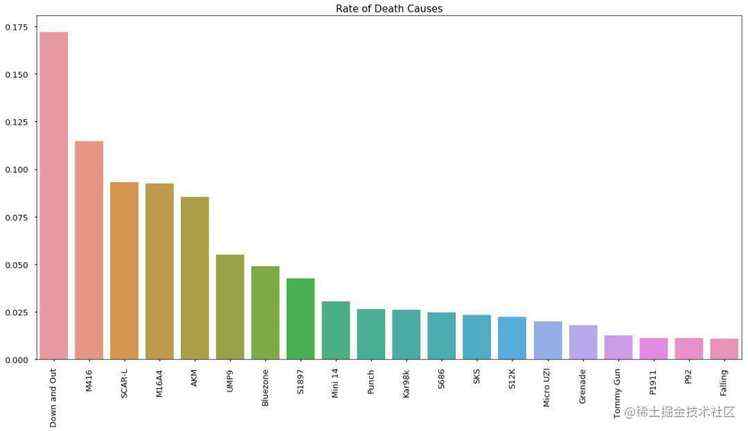
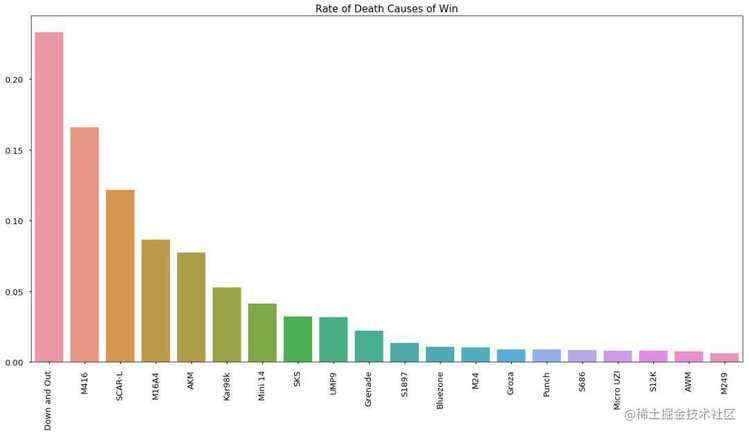
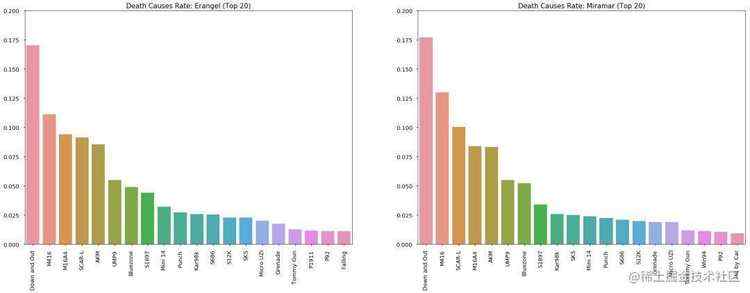
1 #杀人武器排名
2 death_causes &#61; deaths[&#39;killed_by&#39;].value_counts()
3
4 sns.set_context(&#39;talk&#39;)
5 fig &#61; plt.figure(figsize&#61;(30, 10))
6 ax &#61; sns.barplot(x&#61;death_causes.index, y&#61;[v / sum(death_causes) for v in death_causes.values])
7 ax.set_title(&#39;Rate of Death Causes&#39;)
8 ax.set_xticklabels(death_causes.index, rotation&#61;90)
9
10 #排名前20的武器
11 rank &#61; 20
12 fig &#61; plt.figure(figsize&#61;(20, 10))
13 ax &#61; sns.barplot(x&#61;death_causes[:rank].index, y&#61;[v / sum(death_causes) for v in death_causes[:rank].values])
14 ax.set_title(&#39;Rate of Death Causes&#39;)
15 ax.set_xticklabels(death_causes.index, rotation&#61;90)
16
17 #两个地图分开取
18 f, axes &#61; plt.subplots(1, 2, figsize&#61;(30, 10))
19 axes[0].set_title(&#39;Death Causes Rate: Erangel (Top {})&#39;.format(rank))
20 axes[1].set_title(&#39;Death Causes Rate: Miramar (Top {})&#39;.format(rank))
21
22 counts_er &#61; erangel[&#39;killed_by&#39;].value_counts()
23 counts_mr &#61; miramar[&#39;killed_by&#39;].value_counts()
24
25 sns.barplot(x&#61;counts_er[:rank].index, y&#61;[v / sum(counts_er) for v in counts_er.values][:rank], ax&#61;axes[0] )
26 sns.barplot(x&#61;counts_mr[:rank].index, y&#61;[v / sum(counts_mr) for v in counts_mr.values][:rank], ax&#61;axes[1] )
27 axes[0].set_ylim((0, 0.20))
28 axes[0].set_xticklabels(counts_er.index, rotation&#61;90)
29 axes[1].set_ylim((0, 0.20))
30 axes[1].set_xticklabels(counts_mr.index, rotation&#61;90)
31
32 #吃鸡和武器的关系
33 win &#61; deaths[deaths["killer_placement"] &#61;&#61; 1.0]
34 win_causes &#61; win[&#39;killed_by&#39;].value_counts()
35
36 sns.set_context(&#39;talk&#39;)
37 fig &#61; plt.figure(figsize&#61;(20, 10))
38 ax &#61; sns.barplot(x&#61;win_causes[:20].index, y&#61;[v / sum(win_causes) for v in win_causes[:20].values])
39 ax.set_title(&#39;Rate of Death Causes of Win&#39;)
40 ax.set_xticklabels(win_causes.index, rotation&#61;90)
四、队友的助攻是否助我吃鸡&#xff1f;
有时候一不留神就被击倒了&#xff0c;还好我爬得快让队友救我。这里选择成功吃鸡的队伍&#xff0c;最终接受1次帮助的成员所在的团队吃鸡的概率为29%&#xff0c;所以说队友助攻还是很重要的&#xff08;再不要骂我猪队友了&#xff0c;我也可以选择不救你。&#xff09;竟然还有让队友救9次的&#xff0c;你也是个人才。
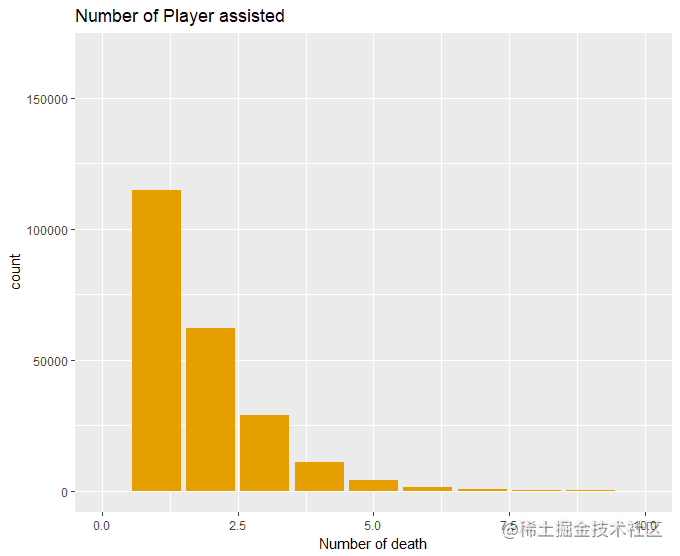
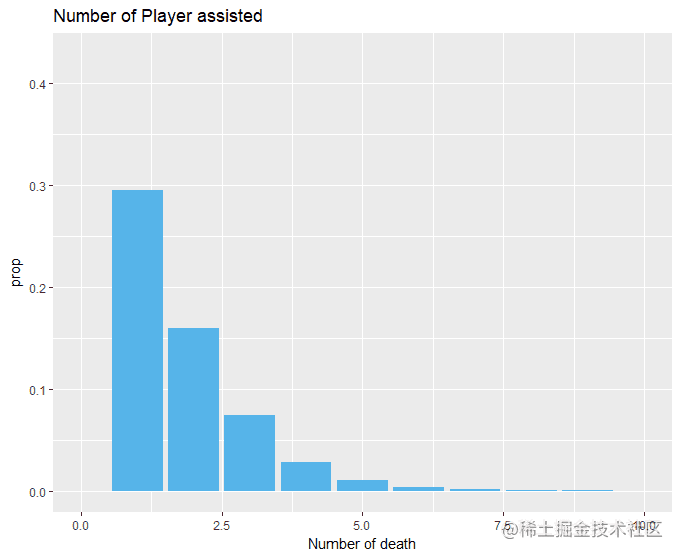
1 library(dplyr)
2 library(tidyverse)
3 library(data.table)
4 library(ggplot2)
5 pubg_full <- fread("E:/aggregate/agg_match_stats_0.csv") 6 attach(pubg_full)
7 pubg_winner <- pubg_full %>% filter(team_placement&#61;&#61;1)
8 detach(pubg_full)
9 ggplot(data &#61; pubg_winner) &#43; geom_bar(mapping &#61; aes(x &#61; player_assists, y &#61; ..count..), fill&#61;"#E69F00") &#43;
10 xlim(0,10) &#43; labs(title &#61; "Number of Player assisted", x&#61;"Number of death")
11 ggplot(data &#61; pubg_winner) &#43; geom_bar(mapping &#61; aes(x &#61; player_assists, y &#61; ..prop..), fill&#61;"#56B4E9") &#43;
12 xlim(0,10) &#43; labs(title &#61; "Number of Player assisted", x&#61;"Number of death")
五、 敌人离我越近越危险&#xff1f;
对数据中的killer_position和victim_position变量进行欧式距离计算&#xff0c;查看两者的直线距离跟被击倒的分布情况&#xff0c;呈现一个明显的右偏分布&#xff0c;看来还是需要随时观察到附近的敌情&#xff0c;以免到淘汰都不知道敌人在哪儿。
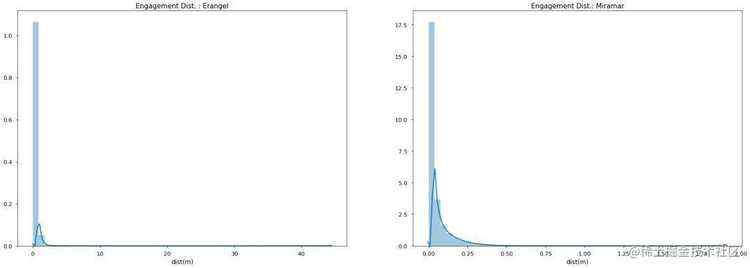
1 # python代码&#xff1a;杀人和距离的关系
2 import math 3def get_dist(df): #距离函数
4 dist &#61; []
5 for row in df.itertuples():
6 subset &#61; (row.killer_position_x - row.victim_position_x)**2 &#43; (row.killer_position_y - row.victim_position_y)**2
7 if subset > 0:
8 dist.append(math.sqrt(subset) / 100)
9 else:
10 dist.append(0)
11 return dist
12
13 df_dist &#61; pd.DataFrame.from_dict({&#39;dist(m)&#39;: get_dist(erangel)})
14 df_dist.index &#61; erangel.index
15
16 erangel_dist &#61; pd.concat([erangel,df_dist], axis&#61;1)
17
18 df_dist &#61; pd.DataFrame.from_dict({&#39;dist(m)&#39;: get_dist(miramar)})
19 df_dist.index &#61; miramar.index
20
21 miramar_dist &#61; pd.concat([miramar,df_dist], axis&#61;1)
22
23 f, axes &#61; plt.subplots(1, 2, figsize&#61;(30, 10))
24plot_dist &#61; 150
25
26 axes[0].set_title(&#39;Engagement Dist. : Erangel&#39;)
27 axes[1].set_title(&#39;Engagement Dist.: Miramar&#39;)
28
29 plot_dist_er &#61; erangel_dist[erangel_dist[&#39;dist(m)&#39;] <&#61; plot_dist]
30 plot_dist_mr &#61; miramar_dist[miramar_dist[&#39;dist(m)&#39;] <&#61; plot_dist]
31
32 sns.distplot(plot_dist_er[&#39;dist(m)&#39;], ax&#61;axes[0])
33 sns.distplot(plot_dist_mr[&#39;dist(m)&#39;], ax&#61;axes[1])
六、团队人越多我活得越久&#xff1f;
对数据中的party_size变量进行生存分析&#xff0c;可以看到在同一生存率下&#xff0c;四人团队的生存时间高于两人团队&#xff0c;再是单人模式&#xff0c;所以人多力量大这句话不是没有道理的。
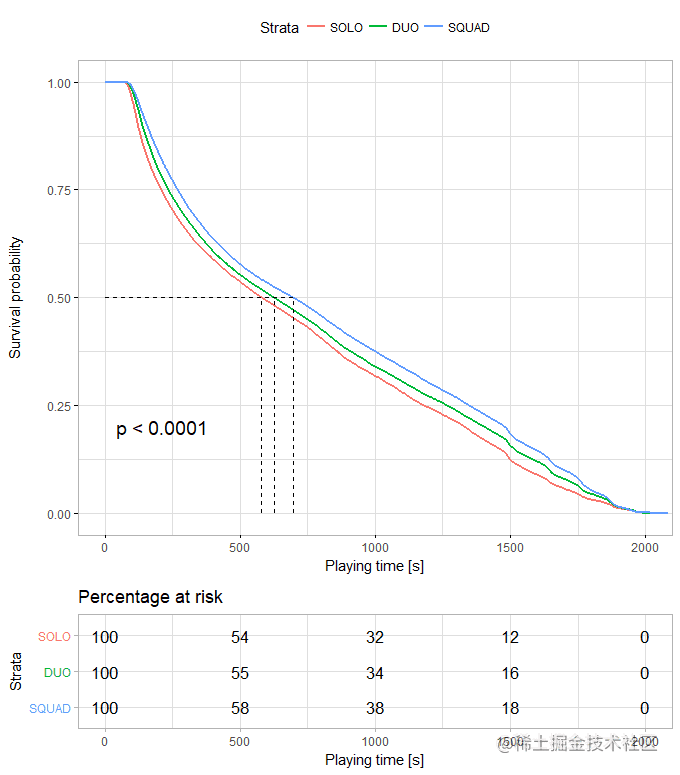
七、乘车是否活得更久&#xff1f;
对死因分析中发现&#xff0c;也有不少玩家死于Bluezone&#xff0c;大家天真的以为捡绷带就能跑毒。对数据中的player_dist_ride变量进行生存分析&#xff0c;可以看到在同一生存率下&#xff0c;有开车经历的玩家生存时间高于只走路的玩家&#xff0c;光靠腿你是跑不过毒的。
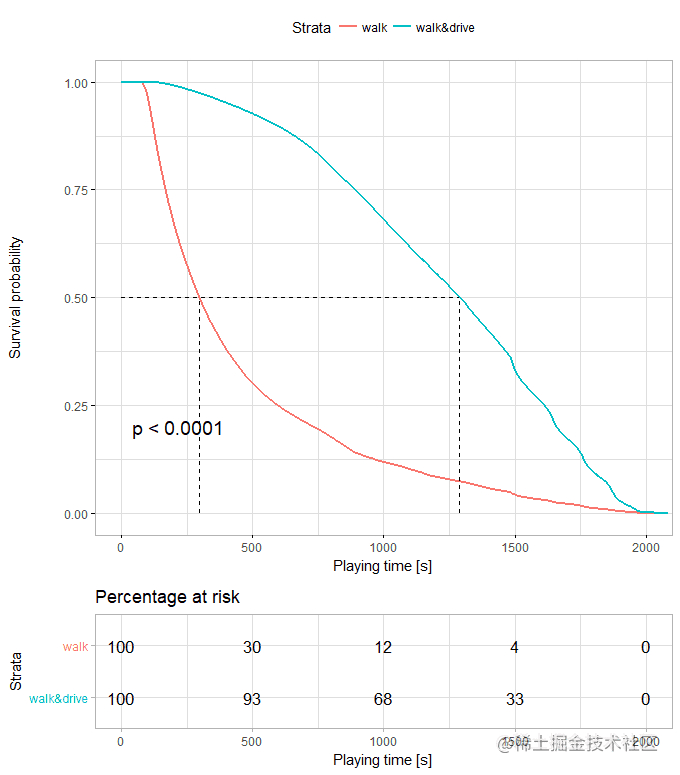
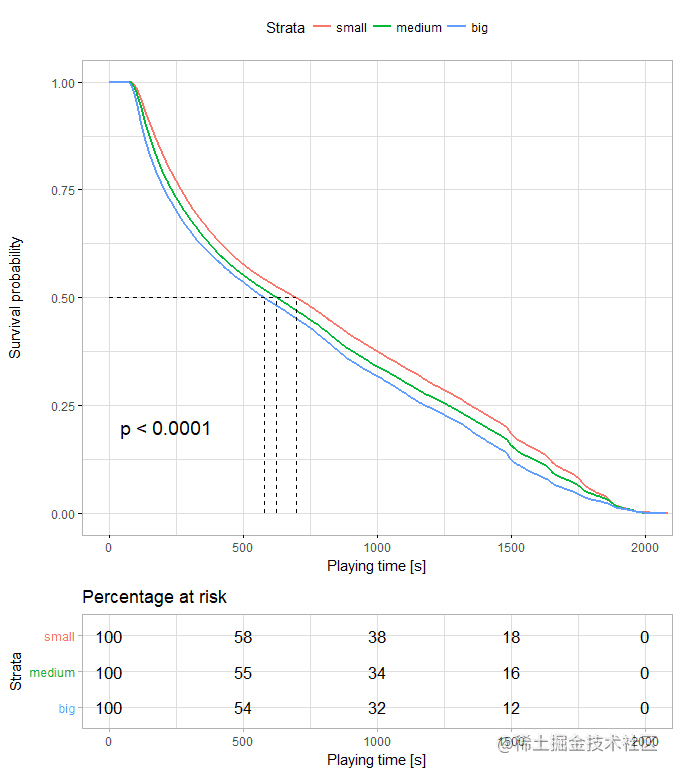
八、小岛上人越多我活得更久&#xff1f;
对game_size变量进行生存分析发现还是小规模的比赛比较容易存活。
1 # R语言代码如下&#xff1a;
2 library(magrittr)
3 library(dplyr)
4 library(survival)
5 library(tidyverse)
6 library(data.table)
7 library(ggplot2)
8 library(survminer)
9 pubg_full <- fread("../agg_match_stats.csv")
10 # 数据预处理&#xff0c;将连续变量划为分类变量
11 pubg_sub <- pubg_full %>%
12 filter(player_survive_time<2100) %>%
13 mutate(drive &#61; ifelse(player_dist_ride>0, 1, 0)) %>%
14 mutate(size &#61; ifelse(game_size<33, 1,ifelse(game_size>&#61;33 &game_size<66,2,3)))
15 # 创建生存对象
16 surv_object <- Surv(time &#61; pubg_sub$player_survive_time)
17 fit1 <- survfit(surv_object~party_size,data &#61; pubg_sub)
18 # 可视化生存率
19 ggsurvplot(fit1, data &#61; pubg_sub, pval &#61; TRUE, xlab&#61;"Playing time [s]", surv.median.line&#61;"hv",
20 legend.labs&#61;c("SOLO","DUO","SQUAD"), ggtheme &#61; theme_light(),risk.table&#61;"percentage")
21 fit2 <- survfit(surv_object~drive,data&#61;pubg_sub)
22 ggsurvplot(fit2, data &#61; pubg_sub, pval &#61; TRUE, xlab&#61;"Playing time [s]", surv.median.line&#61;"hv",
23 legend.labs&#61;c("walk","walk&drive"), ggtheme &#61; theme_light(),risk.table&#61;"percentage")
24 fit3 <- survfit(surv_object~size,data&#61;pubg_sub)
25 ggsurvplot(fit3, data &#61; pubg_sub, pval &#61; TRUE, xlab&#61;"Playing time [s]", surv.median.line&#61;"hv",
26 legend.labs&#61;c("small","medium","big"), ggtheme &#61; theme_light(),risk.table&#61;"percentage")
九、最后毒圈有可能出现的地点&#xff1f;
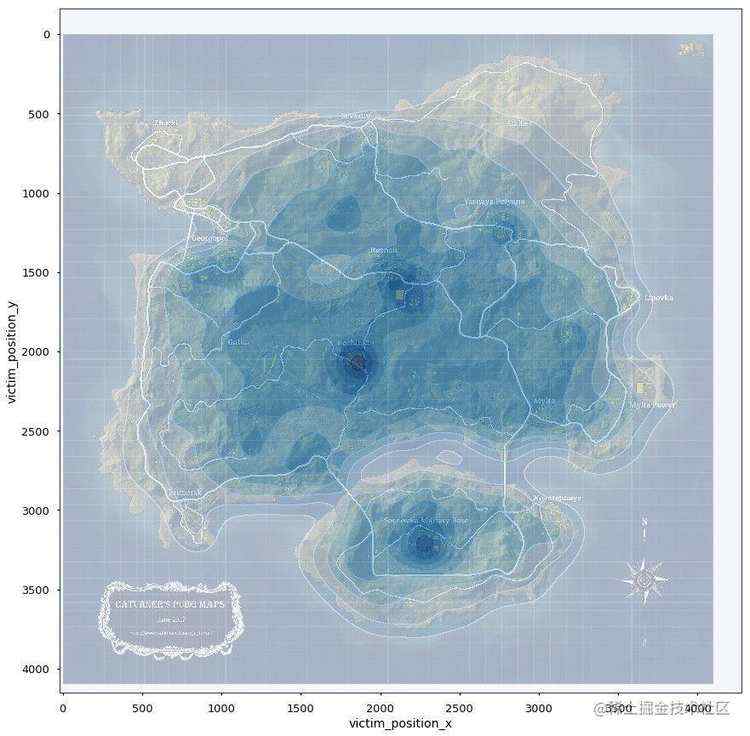
面对有本事能苟到最后的我&#xff0c;怎么样预测最后的毒圈出现在什么位置。从表agg_match_stats数据找出排名第一的队伍&#xff0c;然后按照match_id分组&#xff0c;找出分组数据里面player_survive_time最大的值&#xff0c;然后据此匹配表格kill_match_stats_final里面的数据&#xff0c;这些数据里面取第二名死亡的位置&#xff0c;作图发现激情沙漠的毒圈明显更集中一些&#xff0c;大概率出现在皮卡多、圣马丁和别墅区。绝地海岛的就比较随机了&#xff0c;但是还是能看出军事基地和山脉的地方更有可能是最后的毒圈。
1 #最后毒圈位置
2 import matplotlib.pyplot as plt
3 import pandas as pd
4 import seaborn as sns
5 from scipy.misc.pilutil import imread
6 import matplotlib.cm as cm
7
8 #导入部分数据
9 deaths &#61; pd.read_csv("deaths/kill_match_stats_final_0.csv")
10 #导入aggregate数据
11 aggregate &#61; pd.read_csv("aggregate/agg_match_stats_0.csv")
12 print(aggregate.head())
13 #找出最后三人死亡的位置
14
15 team_win &#61; aggregate[aggregate["team_placement"]&#61;&#61;1] #排名第一的队伍
16 #找出每次比赛第一名队伍活的最久的那个player
17 grouped &#61; team_win.groupby(&#39;match_id&#39;).apply(lambda t: t[t.player_survive_time&#61;&#61;t.player_survive_time.max()])
18
19 deaths_solo &#61; deaths[deaths[&#39;match_id&#39;].isin(grouped[&#39;match_id&#39;].values)]
20 deaths_solo_er &#61; deaths_solo[deaths_solo[&#39;map&#39;] &#61;&#61; &#39;ERANGEL&#39;]
21 deaths_solo_mr &#61; deaths_solo[deaths_solo[&#39;map&#39;] &#61;&#61; &#39;MIRAMAR&#39;]
22
23 df_second_er &#61; deaths_solo_er[(deaths_solo_er[&#39;victim_placement&#39;] &#61;&#61; 2)].dropna()
24 df_second_mr &#61; deaths_solo_mr[(deaths_solo_mr[&#39;victim_placement&#39;] &#61;&#61; 2)].dropna()
25 print (df_second_er)
26
27 position_data &#61; ["killer_position_x","killer_position_y","victim_position_x","victim_position_y"]
28for position in position_data:
29 df_second_mr[position] &#61; df_second_mr[position].apply(lambda x: x*1000/800000)
30 df_second_mr &#61; df_second_mr[df_second_mr[position] !&#61; 0]
31
32 df_second_er[position] &#61; df_second_er[position].apply(lambda x: x*4096/800000)
33 df_second_er &#61; df_second_er[df_second_er[position] !&#61; 0]
34
35 df_second_er&#61;df_second_er
36 # erangel热力图
37 sns.set_context(&#39;talk&#39;)
38 bg &#61; imread("erangel.jpg")
39 fig, ax &#61; plt.subplots(1,1,figsize&#61;(15,15))
40 ax.imshow(bg)
41 sns.kdeplot(df_second_er["victim_position_x"], df_second_er["victim_position_y"], cmap&#61;cm.Blues, alpha&#61;0.7,shade&#61;True)
42
43 # miramar热力图
44 bg &#61; imread("miramar.jpg")
45 fig, ax &#61; plt.subplots(1,1,figsize&#61;(15,15))
46 ax.imshow(bg)
47 sns.kdeplot(df_second_mr["victim_position_x"], df_second_mr["victim_position_y"], cmap&#61;cm.Blues,alpha&#61;0.8,shade&#61;True)
福利&#xff1a;需要Python的各方面资料&#xff0c;就私信小编&#xff0c;随时给予小伙伴们最大的帮助~
每一个 点赞 &#43; 转发 都是对小编的支持&#xff0c;万分感谢 ★,::‧(&#xffe3;▽&#xffe3;)/‧:‧°★* 需要完整源码后台私信暗号666点击链接找我









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有