作者:The-6ixth-Floor乐队 | 来源:互联网 | 2023-08-23 20:00
Nature杂志论文——使用机器学习来预测自闭症基因普林斯顿大学最新一项研究发现了一些新的与自闭症相关的候选基因。虽然研究人员估计存在有数百个与自闭症相关的基因,但实际上只有一小部
Nature杂志论文——使用机器学习来预测自闭症基因
普林斯顿大学最新一项研究发现了一些新的与自闭症相关的候选基因。
虽然研究人员估计存在有数百个与自闭症相关的基因,但实际上只有一小部分有明确的实验证据证明其与自闭症有关。8月1日发表在自然杂志上的一项研究旨在改变这种现状,他们通过使用大数据和机器学习的方法来进行一个有关泛自闭症障碍(ASD)的全基因组预测。该研究的第一作者Arjun Krishnan告诉我们他们的结果将如何帮助泛自闭症障碍(ASD)的早期诊断和治疗。

Q:你能简单总结下你的研究吗?
Arjun Krishnan:泛自闭症障碍(ASD)具有很强的遗传基础,预计有400-1000相关基因,但是目前只有约65种自闭症基因被发现。由于泛自闭症障碍(ASD)十分复杂,光排序或仅仅进行基因研究是相当不够的,不足以揭示自闭症的遗传基础。因此,我们决定采取一种补充数据驱动的方法来解决这一问题。我们使用的方法是基于对先前已知自闭症基因的学习模式与人脑中特定基因网络之间是如何联系的,我们用这些模式来识别新的自闭症基因。
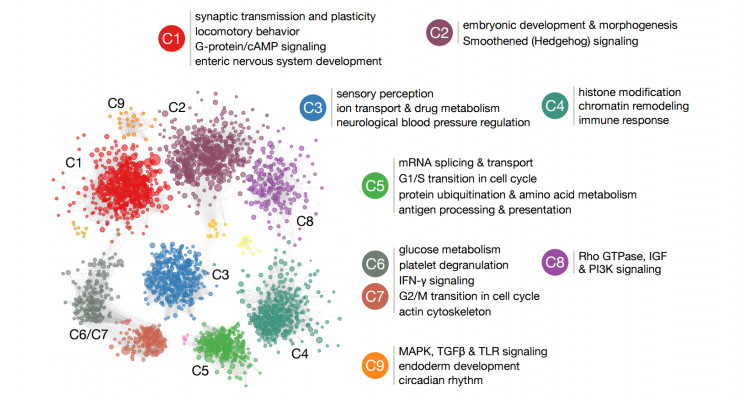
最重要的结果是对基因组中自闭症相关的基因做了一个全面的补充预测。在研究的其他部分中,利用这些基因组泛自闭症障碍ASD候选基因和大脑网络,我们已经确定大脑发育的阶段和区域,以及自闭症患者身上可能会被破坏的特定细胞功能。我们还建立了一个交互网站,任何生物医学研究人员或临床医生都可以访问和查阅使用我们的研究结果。 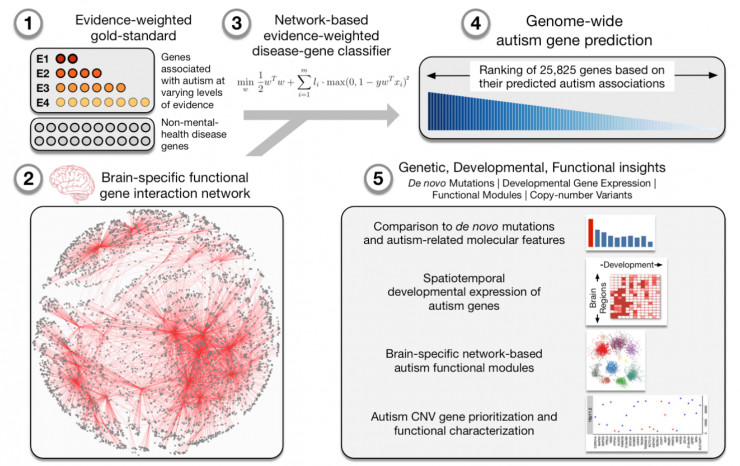
Q:你的研究结果意义是什么?
Arjun Krishnan:我们预测了数百个“新的”候选基因,这些都是在以前的自闭症相关遗传研究从来没有被确定或者涉及的。对于遗传学家来说,这意味着他们可以使用我们的预测来直接进行测序研究,更快、更便宜的发现自闭症相关基因。研究人员可以利用它们来区分和解释有关研究ASD全基因组测序的结果。最后,生物医学研究人员可以使用这些数据以及相关分析,全力研究新的自闭症基因以及它的相关功能、发育和在结构上的影响。
Q:你能向我们解释下是如何将机器学习方法应用到这项研究上吗?
Arjun Krishnan:这项技术基本上类似于Facebook使用的“社交网络”方法,人们在社会背景下是互相关联的,Facebook首先通在社交网络中寻找你的朋友,建议你将一位中学同学“添加为好友”,然后通过你们在社交网络中的共同好友进行推荐。
我们建立了一个特定的大脑基因网络,它是一个关于基因如何在大脑中依靠对方正常运转的地图。利用这个网络,我们采用类似的理念来预测新的ASD基因——首先,我们在大脑网络中发现与已经ASD基因相关的同伴,然后确定网络中与这些协作基因相关的其他基因。
这个设想和其他一些设想一起,形成了一个我们进行系统预测的机器学习框架。
Q:你们实现这些成果用了哪些方法?
Arjun Krishnan:我们用来做ASD基因预测的是一种机器学习方法,它能学习如何识别在基因网络与其他基因关联的自闭症基因,然后使用这些模式来预测新的ASD基因。我们使用的基因网络表明基因是如何一起在大脑中以细胞发挥作用的,或直观地说是一副大脑分子水平的功能图。
我们从所有可能的来源收集了与自闭症相关的基因,包括那些有直接证据或者间接证明的,同时对每个基因的证据是否可靠进行跟踪。然后我们建立了一个基于网络证据加权疾病基因分类器,学习在大脑网络中已知ASD基因的连接模式(考虑到每个基因的证据级别),然后使用数据驱动模式来预测基因组中的每一个基因潜在的与ASD的相关性。
Q:这种方式与以前的基因预测方法有什么不同呢?
Arjun Krishnan:我们的研究对传统的基因预测方法有两个主要的贡献,首先是我们使用了一个基因组规模的组织特异性网络。人类疾病的起源和表现在人体中特定的组织和细胞类型,例如高血压—肾脏,或自闭症—大脑。因此,要准确地描述哪些基因与自闭症类似的疾病相关,我们需要了解和预测这些基因在大脑中发生了什么,而不是在大脑以外其他人体部分。我们通过在人类基因组中使用特定的大脑网络基因实现了这个结果,基于成千上万的基因组实验融合成了特定的大脑信号。
第二个贡献是使用证据加权进行分类,我们在多个来源精心策划了一组与ASD相关的基因,并追踪这些来源是否可靠,使用他们的证据层级为我们的机器学习作出新的预测方法。这种方式作出的预测比基于高置信基因的预测要准确的多。
Q:你的研究对于泛自闭症障碍(ASD)来说意味着什么?
Arjun Krishnan:目前非常需要一个基因或分子测试来对ASD进行诊断,在脑发育早期尽可能地基于ASD患者的基因组成对其进行药物或其他干预治疗。通过对这些候选基因的实验帮助研究人员有效地缩小ASD的遗传基础和遗传筛选,我们的研究结果使他们离这些目标更近了一些。
Q:你认为机器学习在医学研究中最大的潜力是什么?
Arjun Krishnan:我所看到的机器学习的最大潜力是用其处理这个问题——针对个人的基因组成准确预测其健康和疾病的状态。我们的工作是在重大疾病这一方面迈出的巨大一步,帮助找出基因的“特性”可能定义的疾病,希望它可以用来对疾病进行预测。重要的是在追求这一目标的过程中,不单纯是在机器学习或者生物医学研究领域中进行独立研究,更要考虑这两个领域如何能协同合作一起发挥巨大的潜力。
Q:下一步打算如何进行研究?
Arjun Krishnan:下一步我们正在思考的如何将我们的预测结果应用到自闭症患者的全基因组测序研究上,这令我们十分激动。对全基因组测序研究需要面对相当复杂的情况,我们的预测结果可以帮助研究人员集中在一个变量上,落在其附近或接近的基因我们就可以将其识别为与ASD基因高度相关的选项。
PS : 本文由雷锋网(公众号:雷锋网)独家编译,未经许可拒绝转载!
via ResearchGate
雷锋网原创文章,未经授权禁止转载。详情见转载须知。


![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号