作者:qiutuiq | 来源:互联网 | 2023-06-26 09:55
B树B树(B-tree、B-树):是一种平衡的多路搜索树,多用于文件系统、数据库的实现。B树的特点:1个节点可以存储超过2个元素、可以拥有超过2个子节点;拥有二叉搜索树的一些性质(
B树
B树(B-tree、B-树):是一种平衡的多路搜索树,多用于文件系统、数据库的实现。
B树的特点:
m阶B树的性质(m≥2)
m阶表示节点允许有m个子节点,节点元素的个数可以有m-1个。
3阶B树:
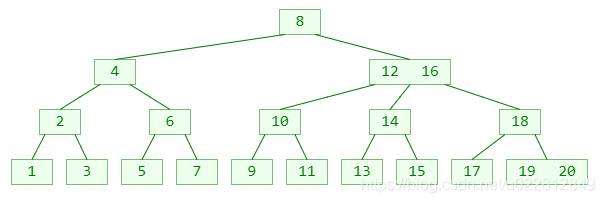
4阶B树:
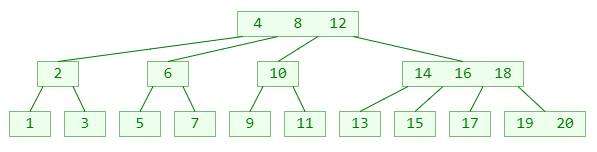
B+树
B+树是B树的一种变形形式,B+树上的叶子结点存储关键字以及相应记录
的地址,叶子结点以上各层作为索引使用。
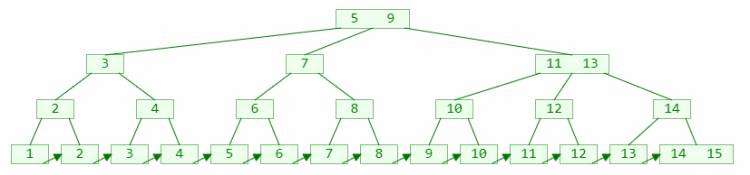
从上图我们可以归纳出B+树的几个特征:
所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点
指针进行连接;
相同节点数量的情况下,B+树高度远低于平衡二叉树;
非叶子节点只保存索引信息和下一层节点的指针信息,不保存实际数据
记录;
只有叶子节点存储实际的数据。
B+树的变体为B树,在B+树的非根和非叶子结点再增加指向兄弟的指针;
B树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代
替 B+树的1/2)。
MySQL中的B+树索引结构
B+树索引是数据库系统中最为常见的一种索引数据结构,几乎所有的关系型数据库都支持它。
那为什么关系型数据库都热衷支持B+树索引呢?因为它是目前为止排序最有效率的数据结构。像二叉树,哈希索引、红黑树、SkipList,在海量数据基于磁盘存储效率方面远不如B+树索引高效。
所以,上述的数据结构一般仅用于内存对象,基于磁盘的数据排序与存储,最有效的依然是B+树索引。
B+树索引的特点是: 基于磁盘的平衡树,但树非常矮,通常为3~4层,能存放千万到上亿的排序数据。树矮意味着访问效率高,从千万或上亿数据里查询一条数据,只用 3、4 次I/O。
又因为现在的固态硬盘每秒能执行至少10000次I/O,所以查询一条数据,哪怕全部在磁盘上,也只需要0.0030.004秒。另外,因为B+树矮,在做排序时,也只需要比较34次就能定位数据需要插入的位置,排序效率非常不错。
B+树索引由根节点(root node)、中间节点(non leaf node)、叶子节点(leaf node)组成,其中叶子节点存放所有排序后的数据。当然也存在一种比较特殊的情况,比如高度为1的B+树索引:

上图中,第一个列就是B+树索引排序的列,你可以理解它是表User中的列id,类型为8字节的BIGINT,所以列userId就是索引键(key),类似下表:
CREATE TABLE User (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(128) NOT NULL,
sex CHAR(6) NOT NULL,
registerDate DATETIME NOT NULL,
...
)
所有B+树都是从高度为1的树开始,然后根据数据的插入,慢慢增加树的高度。你要牢记:索引是对记录进行排序, 高度为1的B+树索引中,存放的记录都已经排序好了,若要在一个叶子节点内再进行查询,只进行二分查找,就能快速定位数据。
可随着插入B+树索引的记录变多,1个页(16K)无法存放这么多数据,所以会发生B+树的分裂,B+树的高度变为 2,当B+树的高度大于等于2时,根节点和中间节点存放的是索引键对,由(索引键、指针)组成。
索引键就是排序的列,而指针是指向下一层的地址,在MySQ 的InnoDB存储引擎中占用6个字节。下图显示了B+树高度为2时,B+树索引的样子:
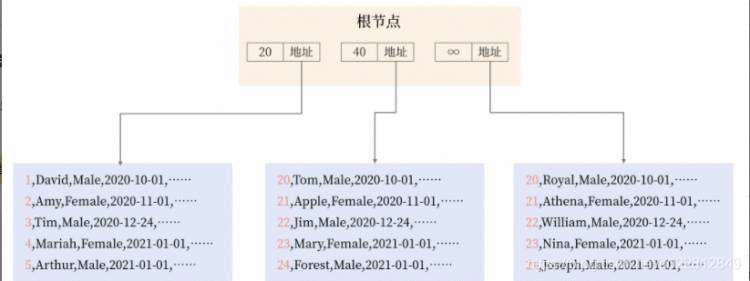
可以看到,在上面的B+树索引中,若要查询索引键值为5的记录,则首先查找根节点,查到键值对(20,地址),这表示小于20的记录在地址指向的下一层叶子节点中。接着根据下一层地址就可以找到最左边的叶子节点,在叶子节点中根据二分查找就能找到索引键值为5的记录。
那一个高度为2的B+树索引,理论上最多能存放多少行记录呢?
在 MySQL InnoDB存储引擎中,一个页的大小为16K,在上面的表User中,键值userId是BIGINT类型,则:
根节点能最多存放以下多个键值对 = 16K / 键值对大小(8+6) ≈ 1100
再假设表User中,每条记录的大小为500字节,则:
叶子节点能存放的最多记录为 = 16K / 每条记录大小 ≈ 32
综上所述,树高度为 2 的 B+ 树索引,最多能存放的记录数为:
总记录数 = 1100 * 32 = 35,200
也就是说,35200条记录排序后,生成的B+树索引高度为2。在35200条记录中根据索引键查询一条记录只需要查询2个页,一个根叶,一个叶子节点,就能定位到记录所在的页。
高度为3的B+树索引本质上与高度2的索引一致,如下图所示,不再赘述:
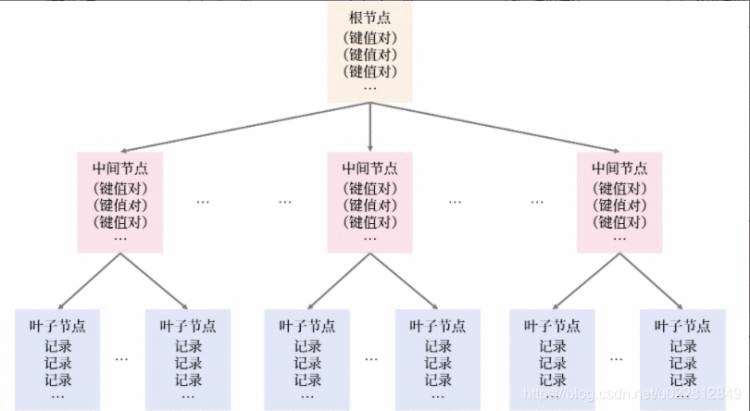
同理,树高度为3的 B+ 树索引,最多能存放的记录数为:
总记录数 = 1100(根节点) * 1100(中间节点) * 32 = 38,720,000
讲到这儿,你会发现,高度为3的B+树索引竟然能存放3800W条记录。高度为4的B+树索引就能存放上百亿的记录了,也就意味着在亿级别的数据中查询一条记录,只需要查询4页,也就是4次IO操作。那么B+树索引的优势是否逐步体现出来了呢?
不过,在真实环境中,每个页其实利用率并没有这么高,还会存在一些碎片的情况。
优化B+树索引的插入性能
B+树的查询高效是要付出代价的,也就是在插入时会带来性能问题。
B+ 树在插入时就对要对数据进行排序,但排序的开销其实并没有你想象得那么大,因为排序是CPU操作(当前一个时钟周期CPU能处理上亿指令)。
真正的开销在于B+树索引的维护,保证数据排序,这里存在两种不同数据类型的插入情况。
数据顺序(或逆序)插入: B+ 树索引的维护代价非常小,叶子节点都是从左往右进行插入,比较典型的是自增 ID 的插入、时间的插入(若在自增 ID 上创建索引,时间列上创建索引,则 B+ 树插入通常是比较快的)。
数据无序插入: B+ 树为了维护排序,需要对页进行分裂、旋转等开销较大的操作,另外,即便对于固态硬盘,随机写的性能也不如顺序写,所以磁盘性能也会收到较大影响。比较典型的是用户昵称,每个用户注册时,昵称是随意取的,若在昵称上创建索引,插入是无序的,索引维护需要的开销会比较大。
你不可能要求所有插入的数据都是有序的,因为索引的本身就是用于数据的排序,插入数据都已经是排序的,那么你就不需要B+树索引进行数据查询了。
所以对于B+树索引,在 MySQL 数据库设计中,仅要求主键的索引设计为顺序,比如使用自增,而不用无序值做主键。









 京公网安备 11010802041100号
京公网安备 11010802041100号