本文导读 本文将解读MySQL数据库查询优化器(CBO)的工作原理。简单介绍了MySQL Server的组成,MySQL优化器选择索引额原理以及SQL成本分析,最后通过 select 查询总结整个查询过程。
一、MySQL 优化器是如何选择索引的 下面我们来看这张表,SUB_ODR_ID字段创建了相关的 2 个索引,根据我们前面所学我们建立一个PRIMARY KEY (ID)自增主键索引,(LOG_ID, SUB_ODR_ID)设置为联合索引、唯一索引,两个时间CREATE_TIME、UPDATE_TIME分别设置两个索引。
CREATE TABLE `***` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`LOG_ID` varchar(32) NOT NULL COMMENT '交易流水号',
`ODR_ID` varchar(32) NOT NULL COMMENT '父单号',
`SUB_ODR_ID` varchar(32) NOT NULL COMMENT '子单号',
`CREATE_TIME` datetime(0) NOT NULL COMMENT '创建时间',
`CREATE_BY` varchar(32) NOT NULL COMMENT ' 创建人',
`UPDATE_TIME` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间',
`UPDATE_BY` varchar(32) NOT NULL COMMENT '更新人',
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE INDEX `UNQ_LOG_SUBODR_ID`(`LOG_ID`, `SUB_ODR_ID`) USING BTREE,
INDEX `IDX_ODR_ID`(`ODR_ID`) USING BTREE,
INDEX `IDX_SUB_ID`(`SUB_ODR_ID`) USING BTREE,
INDEX `IDX_CREATE_TIME`(`CREATE_TIME`) USING BTREE,
INDEX `IDX_UPDATE_TIME`(`UPDATE_TIME`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 SET = utf8 COLLATE = utf8_general_ci COMMENT = '分摊业务明细表' ROW_FORMAT = Dynamic;
在查询字段 SUB_ODR_ID 中,理论上可以使用三个相关的索引:UNQ_LOG_SUBODR_ID、IDX_SUB_ID,MySQL优化器如何从这三个索引中进行选择?
在关系数据库中,B+树只是用于存储的数据结构。
如何使用它取决于数据库的优化器。优化器确定特定索引的选择,即执行计划。优化器的选择基于成本,成本越低,首选指数越高。
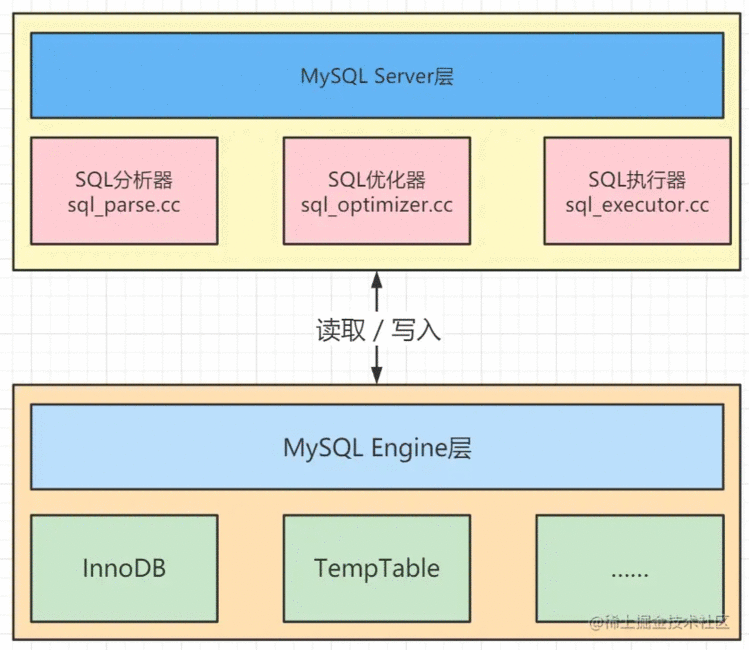
1、MySQL数据库组成
MySQL数据库由Server(服务器)层和Engine(引擎)层组成。
Serve层有SQL分析器、SQL优化器和SQL执行器,负责SQL语句的具体执行过程。
Engine层负责存储特定数据,例如最常用的InnoDB存储引擎,以及用于在内存中存储临时结果集的TempTable引擎。
SQL优化器将分析所有可能的执行计划,并选择成本最低的执行。这个优化器被称为CBO(基于成本的优化器)。
2、MySQL数据库成本计算
在 MySQL中,一条 SQL 的计算成本计算,很好理解,就是访问数据库(数据库页、磁盘)+处理数据。
CPU成本,表示计算成本,例如索引键值的比较、记录值的比较和结果集的排序。这些操作都在服务器层完成
IO成本,表示引擎级IO的成本,MySQL 8.0可以通过区分表的数据是否在内存中来分别计算读取内存IO和磁盘IO的成本。
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
MySQL优化器认为,如果一段SQL需要创建一个基于磁盘的临时表,那么此时的成本是最大的,是基于内存的临时表的20倍。比较索引键值和记录的成本很低,但如果要比较的记录很多,成本就会非常大。
MySQL 优化器认为,从磁盘读取的开销是内存开销的 4 倍(成本不是一成不变的会根据硬件变化)。
二、MySQL查询成本 查看各成本的值,MySQL优化器的工作原理,我们执行下面这行SQL语句,分析执行过程,MySQL 索引选择是基于 SQL 执行成本
EXPLAIN FORMAT=json
select * from test.fork_business_detail f where f.sub_odr_id = ''
read_cost表示从InnoDB存储引擎读取的成本;
eval_cost表示服务器层的CPU成本;
prefix_cost表示SQL的总成本;
data_read_per_join 表示读取记录中的字节总数。
{
"query_block": {
"cost_info": {
"query_cost": "1.20"
},
"table": {
"access_type": "ref",
"possible_keys": [
"IDX_SUB_ID"
],
"key": "IDX_SUB_ID",
"used_key_parts": [
"SUB_ODR_ID"
],
"key_length": "98",
"ref": [
"const"
],
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.20",
"prefix_cost": "1.20",
"data_read_per_join": "1K"
},
"used_columns": [
"ID",
"LOG_ID",
"ODR_ID",
"SUB_ODR_ID",
"CREATE_TIME",
"CREATE_BY",
"UPDATE_TIME",
"UPDATE_BY"
]
}
}
}
三、SELECT 执行过程
如何提高MySQL的查询性能?首先,您需要了解查询优化器进行SQL处理的整个过程。SELECT SQL 的执行过程为例,如下图所示:

客户端向服务器发送SELECT查询;服务器首先检查查询缓存。如果缓存被命中,存储在缓存中的结果将立即返回。否则,进入下一阶段;
服务器执行SQL解析、预处理,查询优化器生成相应的执行计划;MySQL根据优化器生成的执行计划调用存储引擎的API执行查询;结果将返回到客户端,并同时放入查询缓存。
总结 本文将解读MySQL数据库查询优化器(CBO)的工作原理。简单介绍了MySQL Server的组成,MySQL优化器选择索引额原理以及SQL成本分析,最后通过 select 查询总结整个查询过程。






 京公网安备 11010802041100号
京公网安备 11010802041100号