作者:晨曦dora | 来源:互联网 | 2023-07-07 15:35
1.索引分类:主要就两类,聚簇索引和非聚簇索引,聚簇索引就是主键索引,非聚簇索引如普通索引、组合索引唯一索引和前缀索引等。InnoDB引擎中的索引使用B+树结构组织的索引。2.索引
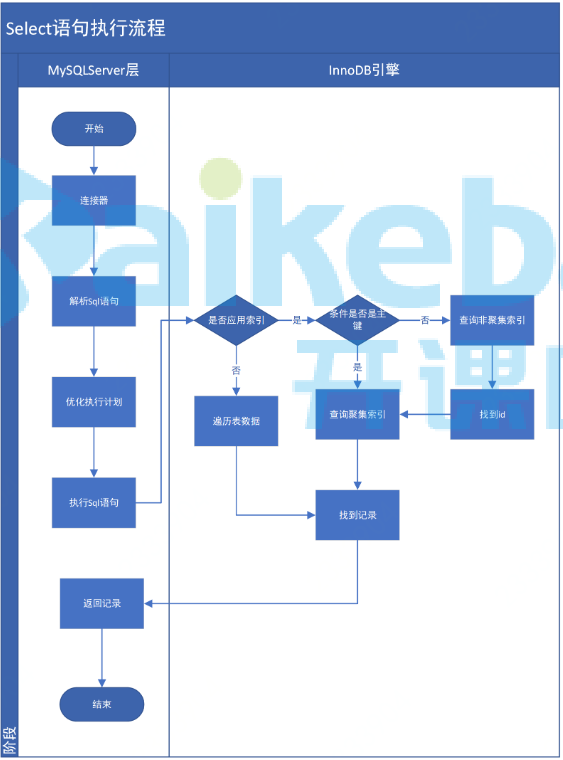
1. 索引分类:主要就两类,聚簇索引和非聚簇索引,聚簇索引就是主键索引,非聚簇索引如普通索引、组合索引唯一索引和前缀索引等。InnoDB引擎中的索引使用B+树结构组织的索引。
2. 索引优劣:索引可以提高数据检索效率,降低数据库IO成本,同时根据索引查出的数据,其索引列是有序的,这样如果order by的列属于执行查询的索引列,则可提高查询并排序的效率;索引是要存储在磁盘上的,占据磁盘空间,虽然可以提高查询效率,但会降低更新表的效率,数据的新增或更新操作,都需要更新相关索引。
3. 数据结构动图演示地址https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
4. MySQL是以页(默认大小16K)为单位读取数据,树结构中的节点就是一个页,所以查询数据时读取树节点个数决定了读取页次数,也就是IO读写次数。
5. B树结构组织的索引,属于多叉平衡查找树,其特点如下:
1)、B树节点中存储着多个元素,每个节点有多个分叉;
2)、节点中元素包含键值和数据,键值是从小到大排列的,如果中间层级查到满足条件的数据,就可以直接返回,无需再继续查到叶子节点;
3)、父节点中的元素不会出现在子节点中;
4)、所有叶子节点都位于同一层,叶节点具有相同深度,且叶节点之间没有连接指针;
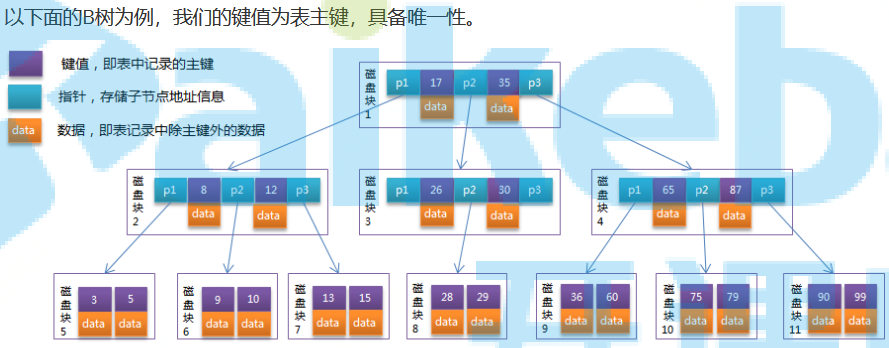
5)、B树不支持范围查询的快速查找,每次查到范围内数据后,还要从根节点再次进行遍历层次查找;
6)、每个节点都存有数据,导致节点占用空间变大,页中存储的键值就会变少,树的高度就会变高,导致查询数据IO次数变多
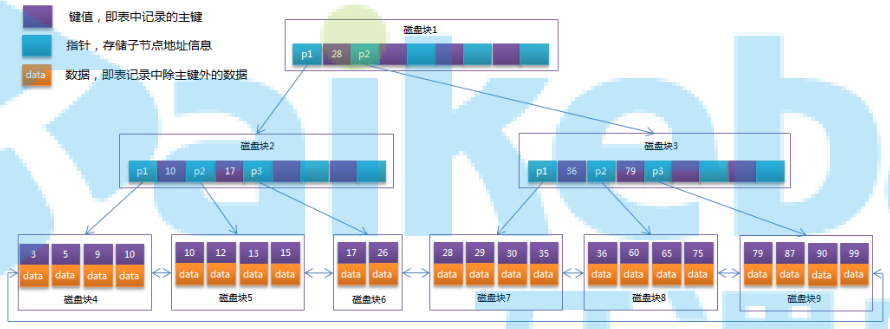
6. MyISAM和InnoDB引擎采用的是B+树结构组织的索引,对B树做了改造,其只有叶子节点存储数据,非叶子节点只存储键值,所有叶子节点之间通过双向指针连成链表。树非叶子节点中不再存储数据,那么节点中就会存储更多的索引数据,可以减少树节点数,这样很多数据时,树的高度不会很大,减少IO读写次数;如果是范围查询,查找到第一个数据后,便可以利用叶子节点的双向链表直接搜索范围内的数据。B+树查找数据必须要查到叶子节点,因为非叶子节点不存有数据。
7. 页分裂:当节点存储的数据达到指定的度后就会进行页分裂,比如一个节点的度为3,当插入第三个数据时,就会选择一个中间值作为父节点,进行分裂成两个子节点(左小,右大或等于),叶子节点是从小到大有序的。
 插入4后,2提升
插入4后,2提升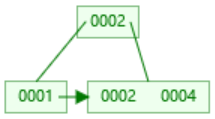 插入5,大于2进入右边,4提升
插入5,大于2进入右边,4提升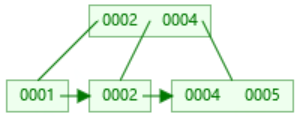 插入3,根据链表顺序,放到2节点中
插入3,根据链表顺序,放到2节点中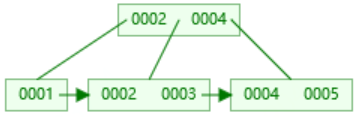 插入6,5提升,父节点又达到度3,则再次提升4
插入6,5提升,父节点又达到度3,则再次提升4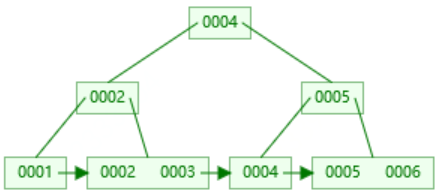
8. MyISAM索引:主键索引和辅助索引结构一样,树节点存储键值是索引值,叶子节点的数据是行记录的磁盘地址。由于辅助索引可以是重复的,所以辅助索引的等职查找也会和范围查询一样检索符合条件的数据;根据索引找到相应数据行记录磁盘地址后,再根据磁盘地址取出数据返回
9. InnoDB索引:
1)、主键索引:树节点的键值是索引值,叶子节点的数据是整行记录;一般情况聚簇索引等同于主键索引,如果一个表没有主键,,那么会选择一个不为NULL的唯一索引列作为主键索引,如果再没有,则InnoDB会自动创建一个ROWID字段构建聚簇索引
2)、辅助索引:树节点的键值是索引值,叶子节点的数据是索引字段值和主键值,如果叶子节点中的数据不能满足查询的数据,则会再根据主键,通过主键索引查询整行记录,这个通过辅助索引找到主键,再通过主键找到整行记录的过程叫做回表操作。
3)、组合索引:
- 表的多个列根据指定列顺序创建的联合索引。如a,b,c三个列创建的索引,先根据a排序,a相同则根据b排序,b相同则根据c排序,c相同则根据主键排序;
- 组合索引最左匹配原则:需要根据创建索引列的顺序,从左向右匹配,直到遇到范围查询(>、<、between、like)或无法匹配到则停止。范围查询的列如果能匹配上索引,则会使用索引,但范围列后的列无法继续使用索引,如a=1 and b>2 and c=3,当匹配到列b时,c无法使用到索引,只能遍历符合a=1 and b>2的所有记录查找c=3的结果集;
- 组合索引创建原则:频繁出现在where条件的列;由于索引是有序的,所以出现在order by或group by语句的列也适合创建索引;常出现在select语句中的列也适合创建索引,可以避免回表操作;
- SQL优化器会优化SQL语句来决定使用哪个索引,如果where条件的列顺序不是创建组合索引的顺序,优化器会进行优化,但仍然建议where条件列顺序为组合索引列的创建顺序;
- 分析SQL select * from table where a=1 and b>2 order by c 如何创建索引:主要依赖b和c的区分度(如性别区分度就低,就三种,未知、男、女),如果b的区分度差就选择a、c创建索引。
4)、覆盖索引:SQL中使用到的列如果都包含在索引列中,那么执行SQL查询时,便可以直接通过组合索引中的数据查询返回,这样也避免了回表。如组合索引abc_index是由表test的列a、b、c顺序创建:explain命令查看执行计划
- select a,b from test where a=1 and b=2;会用到abc_index索引,且会用到覆盖索引,不会回表查询;
- select a,b,d from test where a=1 and b=2;会用abc_index索引查询,但没有用到覆盖索引,需要通过回表查询到d列;
- select a,b from test where b=2 and c=3;会用abc_index索引全表扫描所有数据,利用了覆盖索引,避免了回表。
5)、索引下推(ICP,Index Condition Pushdown):当利用组合索引最左匹配原则进行索引查询数据时,如果匹配到前面的列后,遇到中间某列的范围查询导致中断,而后面还有组合索引的某列,那么此时会利用索引下推,让范围查询列后面的索引列继续起作用。如SQL:select a,d from test where a=1 and b>2 and c=2;当用explain命令查看执行计划时,会发现extra列有Using index condition,表示用到了索引下推。MySQL5.7之前没有索引下推,会把a=1 and b>2的数据返回给Server层进行过滤出c=2的记录,而5.7之后,引入索引下推,InnoDB会直接在a=1 and b>2的记录里过滤出c=2的记录,再返回给Server层处理。
10. 索引创建原则:
1)、where、order by、group by语句后的列考虑创建索引;
2)、join关联条件on语句后的列考虑创建索引;
3)、select常用列可以考虑创建索引,利用覆盖索引,避免回表;
4)、表记录很少的话就没必要创建索引,避免维护索引带来的性能开销;
5)、考虑到索引占用空间和在数据更新时有维护成本,所以索引并不是越多越好;
6)、频繁更新的列不建议创建索引,需要考虑到索引维护成本;
7)、区分度低的列不建议创建索引,因为区分度低,扫描的记录行数并不会少;
8)、主键避免使用很长的字段,建议用长整型,主键越长,页存储的数据就会少,那么范围查询会增加IO频次;
9)、尽量创建组合索引,且把区分度高的列放到前面
11. 索引失效情况:
1)、组合索引不符合最左匹配原则,或者遇到范围条件导致右边索引失效
2)、索引对应的列上使用了函数会导致索引失效
3)、索引列用了不等(!=或<>)会导致索引失效
4)、索引列判断null(is null 或者is not null)会导致索引失效
5)、索引列使用like且用%开头导致索引失效
6)、索引列与对应的值类型不一致,如字符串类型列a使用a=10时,没有加单引号,数据库会进行数据类型转换,导致索引失效
7)、索引列用到or会导致索引失效,如a=1 and b=2可以用到索引,而a=1 or b=2就会全表扫描







 京公网安备 11010802041100号
京公网安备 11010802041100号