原标题:MySQL8.0性能优化(实践)
一台几年前的旧笔记本电脑的虚拟系统运行环境,作为本次实践的运行工具,仅供参考。
案例环境:Linux、Docker、MySQLCommunity8.0.31、InnoDB。
过早的MySQL版本不一定适用本章内容,仅围绕 InnoDB 引擎的阐述。
-- create 方式创建
create [unique] index {index_name} on {tab_name}({col_name}[(length)]);
-- alter表 方式创建
alter {tab_name} add [unique] index {index_name} on ({col_name}[(length)]);
-- 创建组合索引
create index {index_name} on ({col_name1}[(length)], {col_name2}[(length)], {col_name3}[(length)]);
-- unique:唯一索引
-- col_name:一列为单列索引;逗号隔开的多列为组合索引
-- length:字段中前几个字符有效,避免无限长度(通常能够明显区分值即可的长度;如:员工表的Email,@后面都一样)
-- 查看表中的索引
show index from {tab_name};
-- 删除索引
drop index {index_name} on {tab_name};
过多查询的表,过少写入的表。
数据量过大导致的查询效率慢。
经常作为条件查询的列。
批量的重复值,不适合创建索引;比如<业务状态>列
值过少重复的列,适合创建索引;比如
通过非聚集索引检索记录的时候,需要2次操作,先在非聚集索引中检索出主键,然后再到聚集索引中检索出主键对应的记录,这个过程叫做回表,比聚集索引多了一次操作。
where全部为and时,无所谓位置,都会命中索引(当多个条件中有索引的时候,并且关系是and的时候,会自动匹配索引区分度高的)
where后面为 or 时,索引列 依影响数据范围越精确 按序靠前写。
使用原则:
-- 按现有数据,计算哪个列最精确;越精确的列,位置越靠前优先。
select sum(depno=28), sum(username like 'Sol%'), sum(position='dev') from tab_emp;
+---------------+---------------------------+---------------------+
| sum(depno=28) | sum(username like 'Sol%') | sum(position='dev') |
+---------------+---------------------------+---------------------+
| 366551 | 3 | 109 |
+---------------+---------------------------+---------------------+
-- 由此得出:username列的范围最精确,应该放到where后的首位;不在组合索引的列放到最后。
-- 如下组合索引的创建方式:
create index {index_name} on {tab_name}(username,position,depno);
-- 如下组合索引的查询方式:
select username,position,depno from tab_emp where username like 'Sol%' and position='dev' and depno=106 and age<27
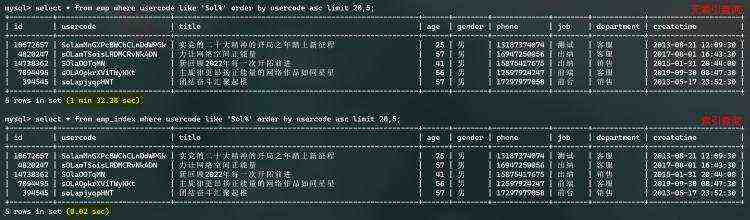
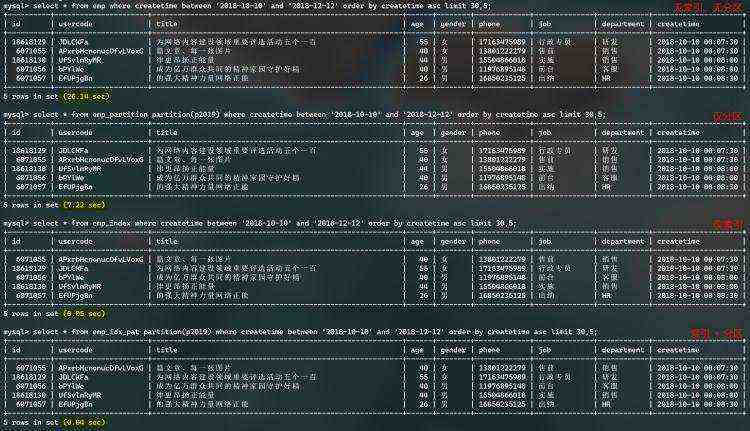
这里准备两张两千万相同表数据,测试效果如下图:
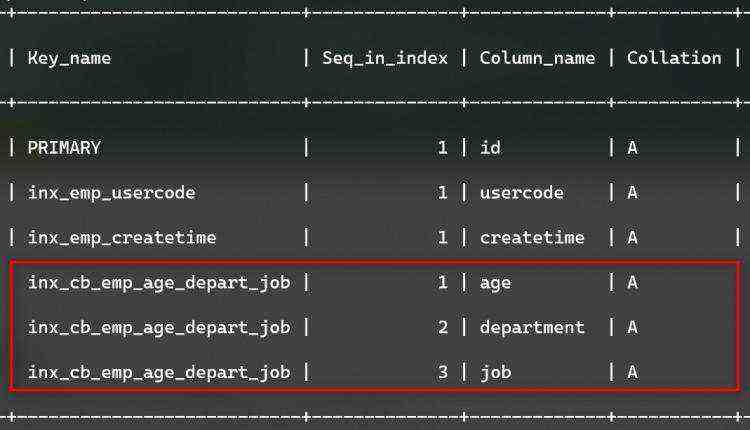
表创建的组合索引,如下图:
两千万数据表,组合索引查询效果,如下图:
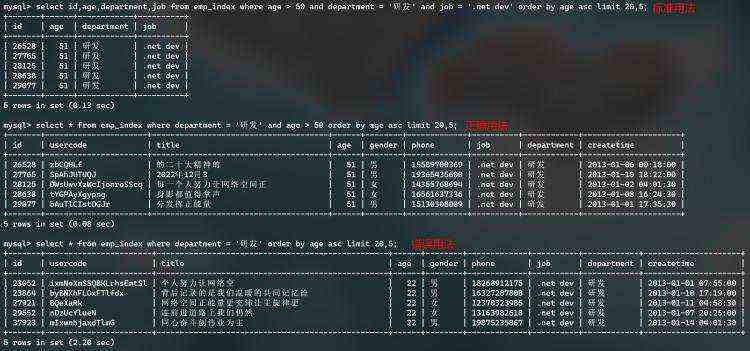
总结:组合索引所包含的列,尽量在where, order中写全,非索引列或过少的组合索引列可能不会产生索引效果。
通常MySQL分页时用到的limit,当limit值过大时,查询效果会很慢。
当如 limit 9000000,10 时,需要先查询出900万数据,再抛掉900万数据;这900万的过程可否省略?
假如:每次查询一页时,把当前页的最后一条数据的重要栏位都做记录,并标识是第几页;当查询它的下页时,拿它的最后一条数据的重要栏位作为追加的查询条件,如何呢...??
下图示例:usercode 为主要的索引及排序字段,上页的最后一条作为追加条件,再往下取5条,效果有了显著提升。(排序列重复数据呢?)当然适用于类似code、time等这样重复数据较少的列。
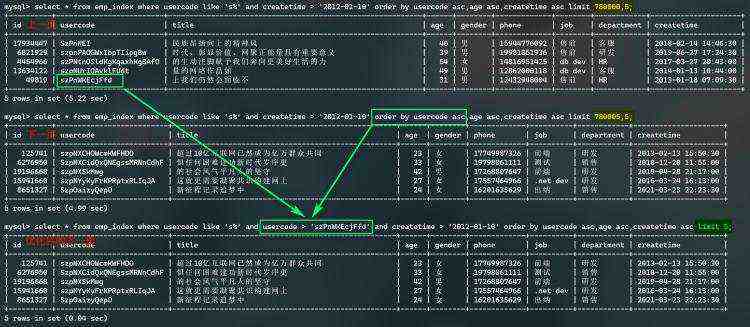
当查询的列中包含了非索引列,系统相当于扫描了两遍数据,如果能只扫描了一遍,也提高了查询效率。
回表查询的过程:
查询涉及到的列都为组合索引列时,包括:select、where、order、group等,索引覆盖(索引下推),避免回表查询。
避免使用*,以避免回表查询;不常用的查询列或text类型的列,尽量以单独的扩展表存放。
通常列表数据需要的列并不多,查询的时候可以考虑为索引列;通常详细信息时涵盖的列多,可通过主键单独查询。
列类型转换可能会导致索引无效;如:
不建议类型的转换,尽量按原类型查询。
条件中的函数导致索引无效;索引列不能用在函数内。如:where abs(Id) > 200
条件中的表达式导致索引无效;如:where (Id + 1) > 200
避免单列索引与组合索引的重复列;在组合索引中的列,去除单列索引。
全模糊查询导致索引无效;匹配开头不会影响索引,如 'Sol%';全模糊或'%Sol'时无效。
显示执行过程,查看是否命中索引
explain select * from tab_emp where uname='Sol'
-- 可能用到的索引、实际用到的索引、扫描了的行数
+----+-------------+---------+-------+---------------+---------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key 文章来源站点https://www.yii666.com/ | key_len | ref | rows | Extra |
+----+-------------+---------+-------+---------------+---------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | tab_emp | range | idx_emp_uname | idx_emp_uname | 4 | const | 1 | Using index condition |
+----+-------------+---------+-------+---------------+---------------+---------+-------+------+-----------------------+
在通常情况下,能不能命中索引,取决于索引列的值重复程度;如果是极少重复的值,就很容易命中索引。如果类似于状态或类型的值,重复程度很高,就很难命中索引,这是MySQL自动取舍的结果。
比如:没有索引的列-电话号码,有索引的列-部门,那么很难命中部门索引,因为MySQL认为[电话号码]更精确;或者使用force强行命中,通常MySQL的自动取舍是最有效的。
避免使用*,以避免回表查询。
不常用的查询列或text类型的列,尽量以单独的扩展表存放。
条件避免使用函数。
条件避免过多的or,建议使用in()/union代替,in中的数据不可以极端海量,至少个数小于1000比较稳妥。
避免子查询,子查询的结果集是临时表不支持索引、或结果集过大、或重复扫描子表;以join代替子查询,尽量以inner join代替最为妥当。
避免使用'%Sol%'查询,或以'Sol%'代替。
表分区也就是把一张物理表的数据文件分成若干个数据文件存储,使得单个数据文件的量有限,有助于避免全表扫描数据,提升查询性能。
那,跨区查询的性能影响有多大,从整体看,表分区还是带来了不少的性能提升。
如果表中有主键列,分区列必须是主键列之一。比如:又有自增主键,又想按年份分区,那主键就是组合索引咯。(id+date)
HASH:按算法,平均分配到各分区
-- 表创建 HASH 分区12个
CREATE TABLE clients (
id INT,
fname VARCHAR(30),
lname VARCHAR(30),
signed DATE
)
PARTITION BY HASH(MONTH(signed))
PARTITIONS 12;
KEY:按算法,无序不等的分配到各分区
-- 表创建12个 KEY 分区
CREATE TABLE clients_lk (
id INT,
fname VARCHAR(30),
lname VARCHAR(30),
signed DATE
)
PARTITION BY LINEAR KEY(signed)
PARTITIONS 12;
RANGE:按划定的范围将数据存放到符合的分区
-- 按年份创建范围分区
CREATE TABLE tr (
id INT,
name VARCHAR(50),
purchased DATE
)
PARTITION BY RANGE(YEAR(purchased)) (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (1995),
PARTITION p2 VALUES LESS THAN (2000)
);
LIST:按定义的一组包含值将数据存放到符合的分区
-- LIST 分组包含方式
CREATE TABLE tt (
id INT,
data INT
)
PARTITION BY LIST(data) (
PARTITION p0 VALUES IN (5, 10, 15),
PARTITION p1 VALUES IN (6, 12, 18)
);
新增 HASH/KEY 分区
-- 将原来的 12 个分区合并为 8 个分区
ALTER TABLE clients COALESCE PARTITION 4;
-- 在原有的基础上增加 6 个分区
ALTER TABLE clients ADD PARTITION PARTITIONS 6;
新增 RANGE/LIST 分区
-- RANGE 追加分区
ALTER TABLE tr ADD PARTITION (PARTITION p3 VALUES LESS THAN (2010));
-- LIST 追加新分区(不可包含已存在的值)
ALTER TABLE tt ADD PARTITION (PARTITION p2 VALUES IN (7, 14, 21));
变更 RANGE/LIST 分区
-- RANGE 拆分原有分区(重组分区)
ALTER TABLE tr REORGANIZE PARTITION p0 INTO (
PARTITION n0 VALUES LESS THAN (1980),
PARTITION n1 VALUES LESS THAN (1990)
);
-- RANGE 合并相邻分区
ALTER TABLE tt REORGANIZE PARTITION s1,s2 INTO (
PARTITIONwww.yii666.com s0 VALUES LESS THAN (1980)
);
-- LIST 重组原有分区
ALTER TABLE tt REORGANIZE PARTITION p1,np INTO (
PARTITION p1 VALUES IN (6, 18),
PARTITION np VALUES in (4, 8, 12)
);
删除指定分区
-- 丢掉指定分区及其数据
ALTER TABLE {TABLE_NAME} DROP PARTITION p2,p3;
-- 删除指定分区,保留数据
ALTER TABLE {TABLE_NAME} TRUNCATE PARTITION p2;
-- 删除表全部分区,保留数据
ALTER TABLE {TABLE_NAME} REMOVE PARTITIONING;
分区详细信息
-- 查询指定分区的数据
SELECT * FROM tr PARTITION (p2);
-- 查询各分区详细
SELECT * FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tt';
-- 查看某个分区的状态
ALTER TABLE tr ANALYZE PARTITION p3;
修复分区
-- 检查分区是否损坏
ALTER TABLE tr CHECK PARTITION p1;
-- 修复分区
ALTER TABLE tr REPAIR PARTITION p1, p2;
-- 优化分区,整理分区碎片
ALTER TABLE tr OPTIMIZE PARTITION p0, p1;
-- 当前分区数据,重建分区
ALTER TABLE tr REBUILD PARTITION p0, p1;
2000万相同数据、相同表结构,相同的查询方式,测试效果如下图:(仅供参考)
数据量大了,查询慢;加索引了,数据量越大,写入越慢;
还是物理分表好呀~
仅列出了点官方认可的稳定性良好的可靠的参数,以 InnoDB 为主。
[mysqld]
# 保持在缓存中的可用连接线程
# default = -1(无)
thread_cache_size = 16
# 最大的连接线程数(关系型数据库)
# default = 151
max_cOnnections= 1000
# 最大的连接线程数(文档型/KV型)
# default = 100
#mysqlx_max_cOnnections= 700
[mysqld]
# 缓冲区单位大小;default = 128M
innodb_buffer_pool_size = 128M
# 缓冲区总大小,内存的70%,单位大小的倍数
# default = 128M
innodb_buffer_pool_size = 6G
# 以上两个参数的设定,MySQL会自动改变 innodb_buffer_pool_instances 的值
[mysqld]
# 优化 order/group/distinct/join 的性能
# SHOW GLOBAL STATUS 中的 Sort_merge_passes 过多就增加设置
# default = 1K
max_sort_length = 8K
#www.yii666.com default = 256K
sort_buffer_size = 2M
# 通常别太大,海量join时大
# default = 256K
#join_buffer_size = 128M
[mysqld]
# 异步I/O子系统
# default = NO
innodb_use_native_aio = NO
# 读数据线程数
# default = 4
innodb_read_io_threads = 32
# 写入数据线程数
# default = 4
innodb_write_io_threads = 32
[mysqld]
# default = 200
innodb_io_capacity = 1000
# default = 2000
innodb_io_capacity_max = 2500
# 数据日志容量值越大,恢复数据越慢
# default = 100M
innodb_redo_log_capacity = 1G
# 数据刷新到磁盘的方式
# 有些同学说用 O_DSYNC 方式,在写入时,有很大提升。但官网说:
# InnoDB does not use O_DSYNC directly because there have been problems with it on many varieties of Unix.
# 也就是少部分系统可以使用,或者已经过确认。
# 个人认为,默认值最可靠
# innodb_flush_method = fsync
[mysqld]
# default = 5000
open_files_limit = 10000
# 计算公式:MAX((open_files_limit-10-max_connections)/2,400)
# default = 4000
table_open_cache = 4495
# 超过16核的硬件,肯定要增加,以发挥出性能
# default = 16
table_open_cache_instances = 32
测试目的:
经过【四、SQL服务参数优化】的配置后,分别测试空表状态批量写入200万和500万数据的耗时。
测试场景:
一台几年前的破笔记本,创建的虚拟机4C8G,Docker + MySQL8.0.31。
桌面应用以36个线程写入随机数据。
批量写入脚本:INSERT INTO TABLE ... VALUES (...),(...),(...) 的方式,INSERT 每次1000条。
表结构:聚集索引 + 两列的非聚集索引 + 一组三列的组合索引;(参照 1.5.2)
+------------+--------------+------+-----+-------------------+-------------------+
| Field | Type | Null | Key文章来源地址67757.html | Default | Extra |
+------------+--------------+------+-----+-------------------+-------------------+
| id | bigint | NO | PRI | NULL | auto_increment |
| usercode | varchar(32) | YES | MUL | NULL | 文章来源地址67757.html|
| title | varchar(128) | YES | | NULL | |
| age | int | YES | MUL | NULL | |
| gender | char(1) | YES | | 男 | |
| phone | char(11) | YES | | NULL | |
| job | varchar(32) | YES | | NULL | |
| department | varchar(32) | YES | | NULL | |
| createtime | datetime | NO | PRI | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
+------------+--------------+------+-----+-------------------+-------------------+
测试结果:
逐步追加MySQL服务参数配置+表分区,最终有了成倍的性能提升;每次测试后的日志记录了优化的递进过程;
如下图:(日志不够细,懂就行)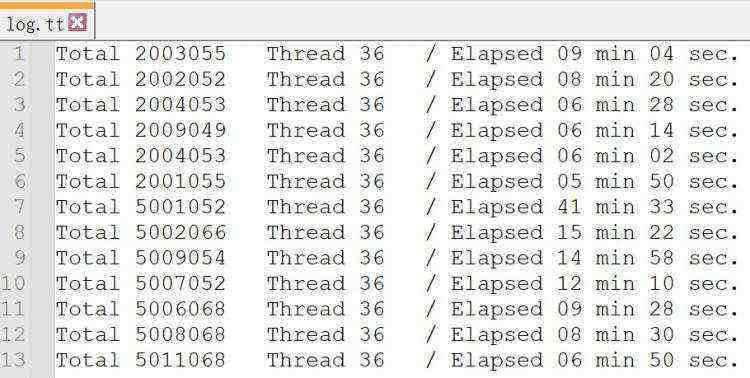
经过逐步优化:
200万数据写入耗时从 9分4秒,提升到 5分50秒;(无表分区)
500万数据写入耗时从 41分33秒,提升到 6分50秒。(有表分区)
来源于:MySQL8.0性能优化(实践)









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有