作者:鹏城飞将 | 来源:互联网 | 2023-09-10 10:52
SSD
动机
目前目标检测的一些算法包括基于深度学习的,都是先假定一些候选框,接着对候选框内容进行特征提取再分类,然后再对边框的位置进行修正这一系列的计算,最典型的例如Faster RCNN,虽然准确,但是计算太过于密集,即使是在高端的硬件上,检测的速度也非常慢,难以达到实时检测的要求。
而另一种基于回归的方法例如YOLO算法,虽然达到了实时的要求,但是牺牲了准确率,并且对于目标的位置也不够精确。并且对于相邻比较近的多个物体,YOLO只能检测出一个。另外对于小物体的检测效果比较差。
因此希望在YOLO的基础上改良,希望能在达到实时的标准下,能够做到和Faster RCNN相媲美的准确率。
主要创新点
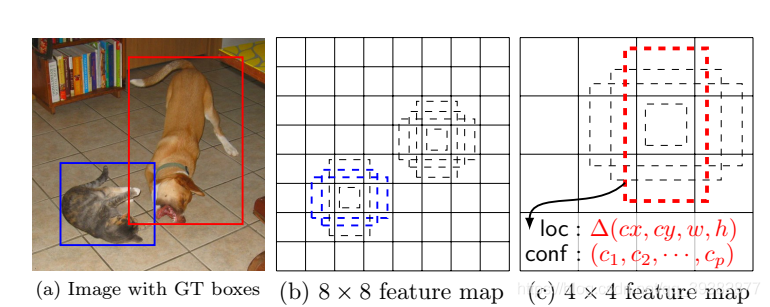
不同比例的默认框(Default boxes)
YOLO网络对于一个网格生成B个候选框,而SSD在此基础上添加了不同的长宽比的概念,因此候选框的生成能够更好的涵盖各种各样的目标,如图所示在一个特征点上生成4个不同的候选框,候选框的大小不同,长宽比例也不一样。这里的default boxes与Faster RCNN的锚点anchors相类似,但是SSD与RPN不同的是,SSD在多个大小的特征图上提取候选区域,而RPN只在最后一层特征图上提取候选区域。因此SSD可以对不同大小的目标都具有比较好的检测效果,高层的特征图负责大目标,低层的特征图负责小目标。
多尺度预测
SSD在原来卷积网络的基础上,又增加了几个卷积层,使得网络能够在多个不同大小的特征图上分别进行预测,这样就能够保证对于图中的不同大小的目标都可以有效的检测,大大提高了目标检测的准确率。
算法

SSD在YOLO网络的基础上进行改进,首先是将原始图像输入一系列卷积层,经过VGG16基础网络的5层卷积层之后得到38x38x512的特征图,与YOLO不同的是,SSD网络去除接下的来的全连接层,将VGG中的fc6、fc7用一系列卷积层来代替,得到了不同大小的特征图,例如图中的19x19,10x10,5x5,3x3,对每一个特征图分别进行预测。
预测的方法是用一个3x3的卷积核,例如在图中38x38的特征图上进行预测,对于原来的38x38x512的特征图,乘上3x3x512x(4x(classes+4))的卷积核,填充为1,步长的为1的卷积得到38x38x(4x(classes+4))((38-3+1x2)/1+1=38)的特征图,表示38x38每个特征点上默认生成4个默认框,每个默认框中有4个位置偏移的预测值以及每一个类别的得分值。因此输出的是4x(classes+4)个通道,分别表示的是每一个特征点各个默认框的位置偏移以及类别打分,这样就可以一次性预测同一个特征图上的所有区域。
最后将所有特征图的输出结合到一起,就达到了同时预测一张图片上所有的默认框的类别,实现了YOLO一次运算就完成了整张图像的检测的思想。
优缺点
SSD检测速度比较快,能够达到实时检测目标的要求,但是对于默认框的设置比较依赖经验,而这对准确率有比较大影响,因此适合于一些大小已知比较固定的目标。
准确率
由于用到了多个不同尺度的特征图进行预测,再加上多个不同长宽比例的默认框的思想,检测的准确率相较于YOLO的63.4%提高到了74.3%,达到了Faster RCNN的效果(73.2%)。
运行速度
由于将YOLO网络中的全连接层用卷积层代替,运算的参数也减少了,检测速度由YOLO的45fps提到高了59fps。
缺点
- 网络中默认框的大小和长宽比不能通过学习得到,因此非常依赖于经验调整。
- 虽然用到了多个尺度特征图,但是最大仍然是VGG5个卷积层之后得到的,因此对于小物体的检测效果也没有那么好。
- 没有结合多层特征图(例如FPN中的那样),导致底层特征图虽然对于位置的预测比较准确,但是对于语义的判定还比较低级,只能检测表示边缘特征。
DSSD
TODO
FSSD
TODO
DSOD
动机
卷积神经网络在计算机视觉领域已经有了很广泛的应用,包括图像分类、目标检测以及图像的分割,而在目标检测领域内,基于深度学习的模型已经取得了很好的效果。
但是之前的一些基于深度学习的目标检测的模型都是从已有的模型进行微调得到的,例如ImageNet上的分类模型,这样会在学习的过程带来偏差。首先是已有模型中参数非常大,因此新的模型难以在原有的预训练模型的基础上改变结构;其次就是在分类和检测的过程中,损失函数以及类别的分布并不相同,导致学习有偏差;最后就是一些特定的领域例如医学图像与传统的图像有较大差异,造成学习有所误差。
因此就希望能够提出一种新的模型,能够从零开始进行学习,也能够达到从预训练模型微调那样保持比较高的准确率。
主要创新点
Dense Block
DOSD一大特点就是吸取了DenseNet的优点,将DOSD基础的卷积网络部分换成了DenseNet,通过一个个Dense Block连接。

如图所示,Dense Block吸取了ResNet的残差的特性,但是在ResNet中只连接了间接相邻的一层,例如H2与H4之间有一个残差连接,如果H3层卷积导致整个网络的分类效果有所下降,则跳过H3,将H2的直接输入到H4。而DenseNet则是在一个模块内,一个卷积层的输入来自之前所有层的输出,例如图中H4的输入则是H0、H1、H2以及H3所有的层。通过加深了网络的结构,有效的提高了网络的分类性能。
除此以外,由于卷积层的输入是网络前面多个卷积层输出的特征图,因此减少了每一层卷积核的通道数,这样通过融合多层卷积层输出的特征图,也能得到ResNet一样的效果。通过“特征复用”不但融合了多层特征图,并且可以大大减少了网络中需要训练的参数。
密集的预测结构
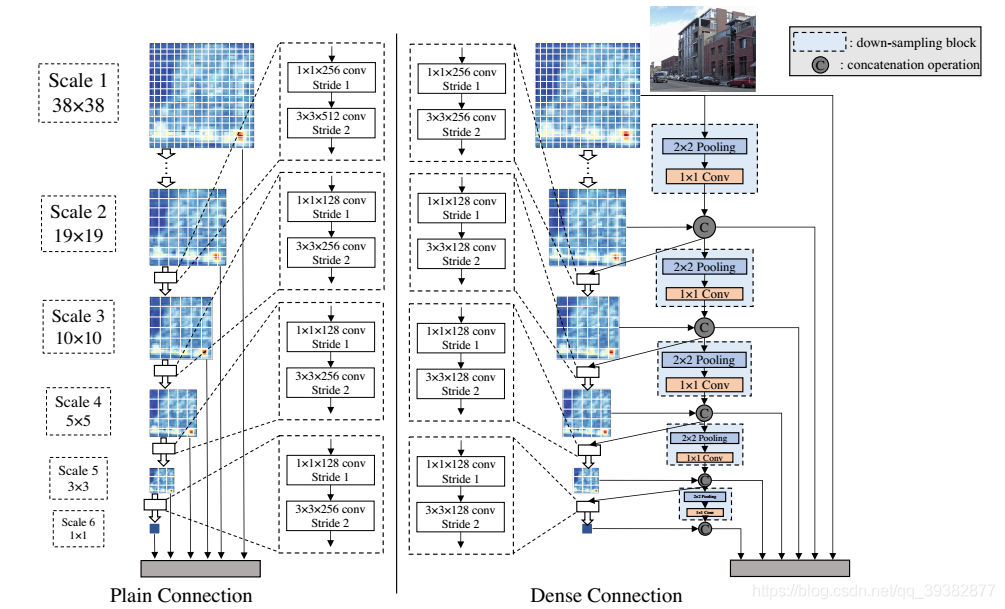
如图所示,左侧是SSD的结构,SSD中用到了6个种不同尺度的特征图进行预测,只不过六个特征图都是单独来进行预测。而右侧就是DOSD的结构,同样吸取了DenseNet的密集型结构,加上SSD原本的框架,通过一个下采样层将高维的特征图降低到下一个特征图一样的维度,再将两层特征图相加结合起来进行预测,这样就做到了对于新的特征图一半是新学习到的而另一半是复用的上一层特征图,因此也大大减少了需要学习的参数。
算法
DOSD主要的思想就是希望能够从零开始学习训练也能够达到与那些预训练模型上微调得到的模型所一样的效果,但那些基于区域提取的网络例如Faster RCNN从零开始训练无法收敛,因此选择了SSD的基础上进行改进。DOSD实际上就是SSD加上DenseNet,整体的流程与SSD基本一致,主要变化的地方在于首先是基础的卷积网络由VGG换成了分类性能更好的DenseNet,另外就是对于新的特征图采取一半学习一半复用的原则,通过融合了两层特征图,既提高了检测的性能,同时减少了参数,对于从零开始训练加快了训练的速度。
整体的流程就是首先对于一张输入的图像进行卷积运算,接着得到不同尺度的特征图,通过密集的预测结构来得到6个新的不同尺度的特征图,分别在这6个新的特征图上进行预测。
优点
DOSD主要解决的就是不需要预训练模型也能跑出很好的效果,因此适用于例如医疗影像这些与传统图像相差较大的领域。
准确率
DOSD主要就是希望能够对于不用预训练模型从零开始也能够达到相媲美的效果,在VOC07的测试集上准确率达到77.7%,相较于Faster RCNN+ResNet的结构甚至略有提升(Faster RCNN76.4%),虽然相较于R-FCN(79.5%)还略有不足。
运行速度
由于密集型结构的思想,DOSD网络中的参数非常少,因此在单一GPU上,检测速度达到17.4fps,相比之下R-FCN只有11fps,SSD+ResNet-101也仅有12.1fps。(SSD+VGG 有45fps)。








 京公网安备 11010802041100号
京公网安备 11010802041100号