作者:mobiledu2502876597 | 来源:互联网 | 2023-07-06 10:54
背景:在aws和qq同时存在时,两边分开计算,数据量不大,任务不会出现延迟,全迁移到qq之后,所以数据全在一个集群中处理,延时非常严重,没办法做到实时风控拦截调优后配置如下:1.控
背景:在aws和qq同时存在时,两边分开计算,数据量不大,任务不会出现延迟,全迁移到qq之后,所以数据全在一个集群中处理,延时非常严重,没办法做到实时风控拦截
调优后配置如下:
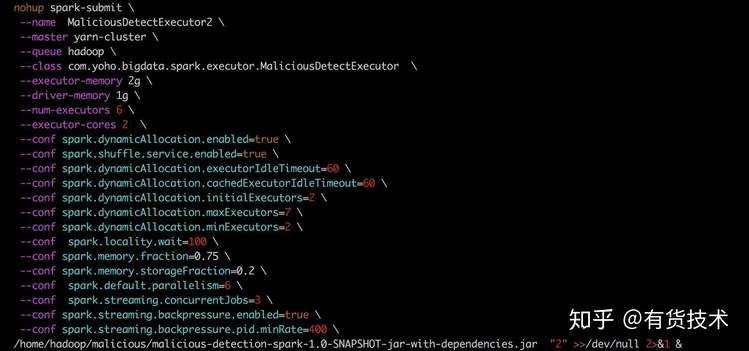
1.控制sparkstreaming 消费能力,防止任务计算不完发生堆积或内存溢出
机制1:
背压机制,sparkstreaming 支持根据响应时间动态控制接入消息数,配置如下
spark.streaming.backpressure.enabled=true(开启背压)
spark.streaming.backpressure.pid.minRate=400(最少接入消息数)
机制2:
spark.streaming.kafka.maxRatePerPartition(控制batch类最多消费多少条消息,分区个数*spark.streaming.kafka.maxRatePerPartition就是接入的总消息数)
背压效果如下:
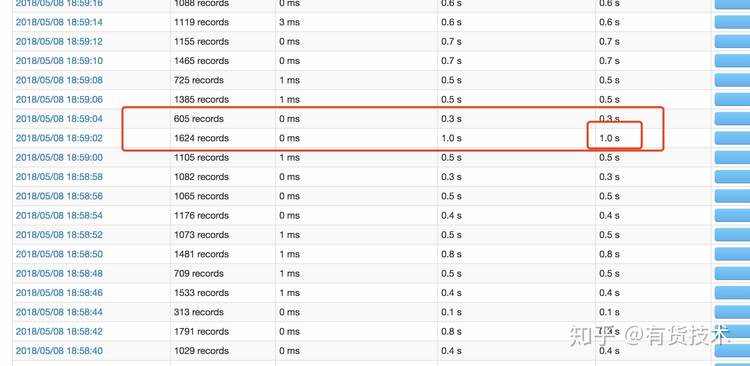
背压机制较机制2更灵活,且能很好结合资源动态伸缩
2.广播机制
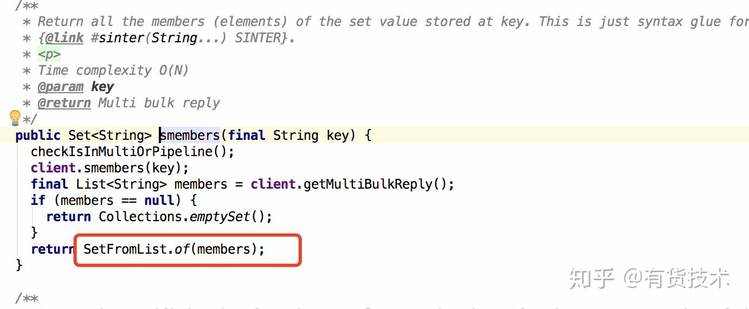
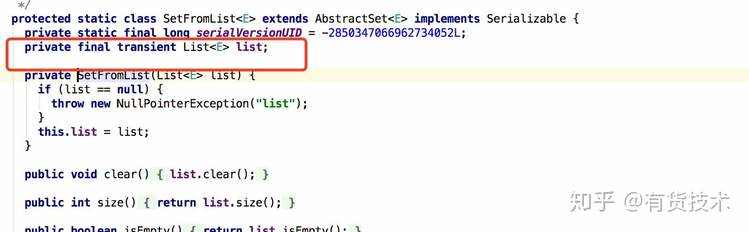
敏感接口列表,用广播机制替代实时查询redis(这里要注意广播出去的变量都必须是支持序列化的,redis类库返回的set是不支持序列化的,运行过程会报空指针)

3.高性能算子和缓存机制
用mapPartitionsToPair替代mapToPair,前者直接作用于一个Partition来计算,后者基于Partition中的每个元素一个个运算
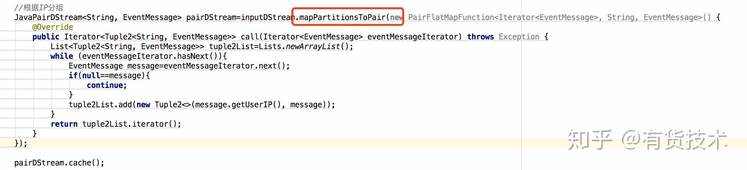
将经常用maprdd缓存起来,避免job重复计算
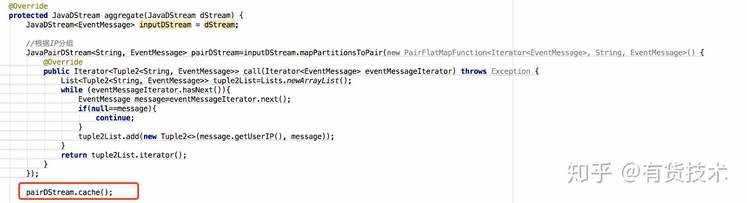
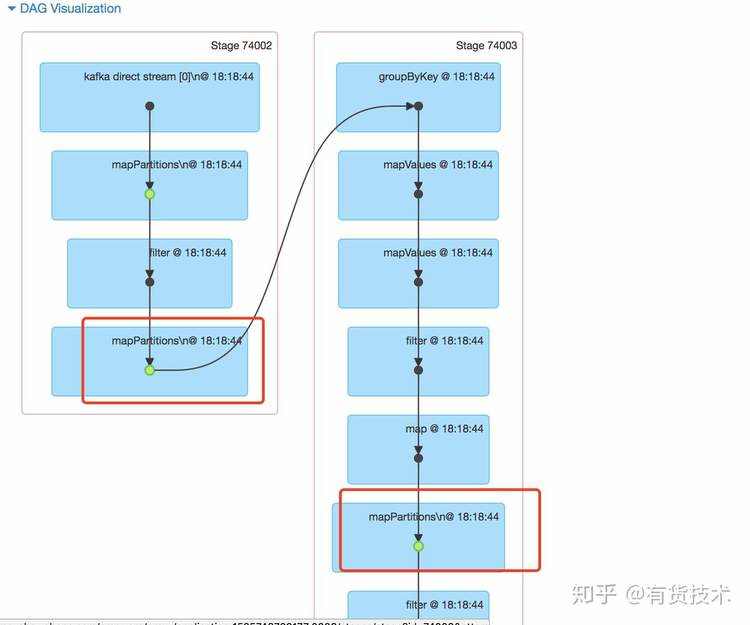
4.资源动态伸缩
spark.dynamicAllocation.enabled=true \
spark.shuffle.service.enabled=true \
spark.dynamicAllocation.executorIdleTimeout=60
\
spark.dynamicAllocation.cachedExecutorIdleTimeout=60
\
spark.dynamicAllocation.initialExecutors=2
\
spark.dynamicAllocation.maxExecutors=7 \
spark.dynamicAllocation.minExecutors=2 \
yarn-site文件配置shuffle服务,添加如下配置


另外需要将spark下的

jar包拷贝到/usr/local/service/hadoop/share/hadoop/yarn下,保障nm能找到对应的类。
PS:实测过程,伸缩回来之后,executor无法回收回去,即使计算时间很快
Executor回收机制:
只要有一个task结束,就会判定有哪些Executor已经没有任务了。然后会被加入待移除列表。在放到removeTimes的时候,会把当前时间now
+ executorIdleTimeoutS * 1000 作为时间戳存储起来。当调度进程扫描这个到Executor时,会判定时间是不是到了,到了的话就执行实际的remove动作。在这个期间,一旦有task再启动,并且正好运行在这个Executor上,则又会从removeTimes列表中被移除。
那么这个Executor就不会被真实的删除了。因为实际运行过程中,有12个kafka 分区,会导致一直有task在Executor中运行,无法触发Executor删除操作,源码可见org.apache.spark.
ExecutorAllocationManager
5.分离regionserver和 nm进程,regionserver进程在compact时,会很耗资源,导致跑在这些机器上任务执行时间很长
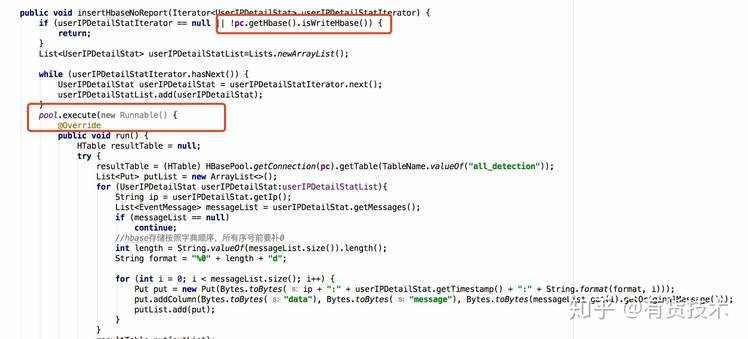
6.将写hbase操作,做成异步写,并可以动态关闭写hbase 接口明细操作
7.合理设置shuffle的数量,例如groupByKey操作,通过spark.default.parallelism参数控制,默认是2(这样可以有效控制foreachRdd操作时每个任务的耗时时间)实际操作过程中,最好是和excutor core个数相等,配置成6会产生6个task

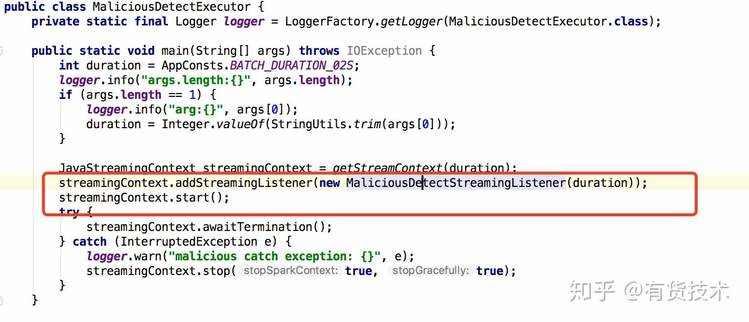
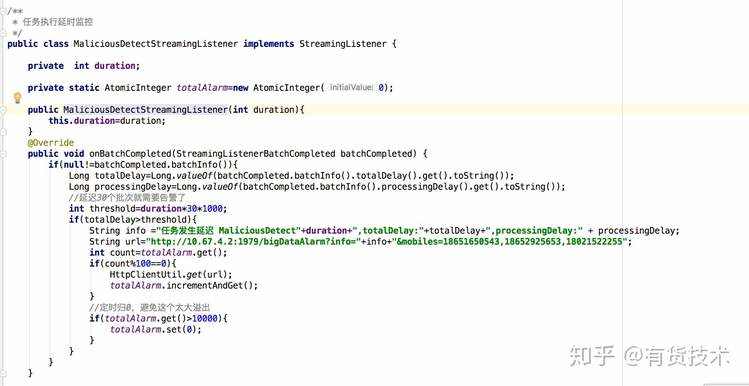
8.sparkstreaming 任务延时监控,在任务延迟时,能第一时间知道
通过注册MaliciousDetectStreamingListener到JavaStreamingContext中,来监控任务延时情况,并告警 @See https://www.jianshu.com/p/5506cd264f4d







 京公网安备 11010802041100号
京公网安备 11010802041100号