作者:手机用户2502860335 | 来源:互联网 | 2023-09-23 00:21
前言
每逢金九银十 , 像作者这样的IT码农, 会按捺住内心对 996 和 SB产品经理 的一万种脏话, 偷偷将手中的简历更新, 投往互联网各公司的HR手中 , 这时IT论坛里也热闹起来了, 各种大厂内推和求内推的帖子被顶的火热. 有些幸运的 码农拿到了些大厂的 面试邀请, 想着大厂入职后诱人的福利, 翻倍的薪资, 不少年轻的码农不知不觉流下了口水, 兴奋的彻夜难眠…
讲个事, 我有个哥们叫张大胖也是 Java码农, 上个月去某大厂面完试 , 去之前神采奕奕 的和我说 “这个岗位的最低薪资就是他现在薪水的两倍 , 笑着说: 等着哥们到时候进某厂了, 给你内推, 一起写Bug.” 这个星期五 张大胖喊我下班来他家吃羊肉火锅, 一上桌看着大胖整个人垂头丧气的, 脸上写满了惆怅, 我赶紧给他把酒满上, 招呼他吃菜, 酒过三巡, 我问张大胖 “上个月面的咋样啊 ?” 他这时面露说道: “我TM就面个中级工程师,去了先让我做一堆看不懂的算法题, 然后来一个秃头老大哥来面我, 据说都工作十多年了, 没等我把项目逻辑讲完就拿着简历追问我技术栈底层实现, 用了什么设计思想 balabala, 我硬撑着把肚子里的那点货倒腾出来, 又被连环追问,感觉人都傻了, 哥们最近真倒霉能力被碾压了!” 我说: “你在简历中专业技能栏里写的啥?” 大胖用手机把他的简历发给我了, 专业技能栏足足写了 10行, 前面都写着精通. 我说 "这么多技术你都懂原理吗? " 张大胖摆了摆手, “都是项目里用过的,用完早就忘了, 叹了口气又说 我啥时候才能和你一样吊打面试官, 薪资翻倍啊!” 我喝了口酒笑着说 “我也就比你多做了点功课,来大胖我帮你分析分析!”
看看张大胖的技术栈.
- 精通Java基础知识以及设计模式 , 熟练应用阿里官方Java代码规范标准编写优质Java代码。
- 精通微信小程序项目, 以及微信公众号等相关微信生态开发集成。
- 精通Javascript编程、Vue.js框架以及WebPack等前端技术,掌握iView, Vue-Route, TypeScript,ECharts。
- 深入研究Spring相关源码, 业余拥抱开源社区贡献代码, 并长期保持刷LeetCode的习惯。
- 精通Elastic Stack (ELK) 大数据生态 中的Elasticsearch, Logstash, Kibana, Filebeat进行数据挖掘。
- 精通SpringBoot, Spring, Mybatis, Hibernate, OSGI等框架的核心思想及开发JavaEE项目流程。
- 精通Oracle , MySQL的数据库的设计维护。非关系型的数据库中,对于Neo4j的使用较为熟练。
- 精通Dubbo RPC远程通信技术, Kafka消息队列, Guava本地缓存, 了解SpringCloud微服务等。
- 精通爬虫技术(HttpClient Jsoup), 了解反爬与反反爬技术。
- 精通Intellij IDEA , VS Code开发工具,熟悉Git/SVN 版本控制工具, Maven依赖管理工具。
大胖被面试官KO的真相
我曾经也是作为过面试官,亲历过从约面试到发Offer的全过程, 负责任的讲, 公司给你发面试邀请的这个环节, 其实是因为你的简历得到了HR 你未来上司的初步认同, 认为你的简历技能与当前职位匹配, 面试这个环节本质则是考察面试者与职位匹配度的高低, 基本的框架 CRUD 搬砖问题谁都会回答, 怎么能考察出面试者的真实水平, 从而优中选优呢?
大厂考察研发工程师都需要写算法题, 考察面试者的基础编程能力.
关于你的项目是什么个业务逻辑, 面试官一点都不关心, 面试官关注的是你对技术的追求, 是否深入了解项目中的技术原理, 是否有自学能力.
不要顺着面试官的意思来, 在自己深入的技术上, 要主动讲源码, 讲思想, 挑逗面试官的好奇心, 从而抱得Offer归.
一切的一切, 都说明一个问题, 面试前一定要做好秀面试官一脸的功课, 让他抓着你的手求你明天来上班 , 而不是最后被面试官吊一顿,回家等通知, 面试的过程, 要变被动为主动, 是你选择Offer而不是Offer选择你.
如何帮助张大胖反秀面试官一脸
日常刷LeetCode, 如果想进大厂, 算法与数据结构不能丢.
必须将写在简历上的技术栈底层搞懂个七七八八,能住唬人.
尽量聊面试官感兴趣的话题, 将自身经历与职位要求上靠, 提高匹配度,
将面试时被问到回答的不满意的问题,记录成下面的问答式面试题集.
日常必须阅读源码, 比如 Spring IOC 理解等 (面试必问) , 面试问到 IOC, 就是你反杀面试官的开始 , 23333.
讲讲张大胖被问倒的面试底层面试题集
1.ES的倒排索引的底层?
ElasticSearch引擎把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表
示例:
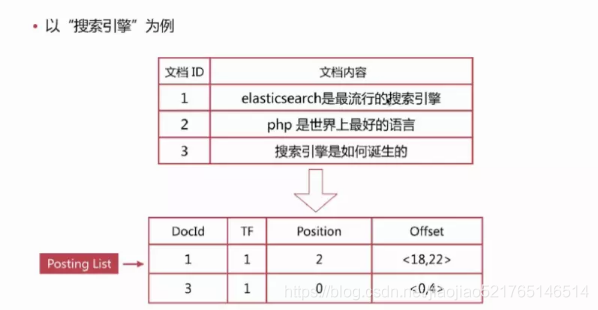
对以下三个文档去除停用词后构造倒排索引
倒排索引-查询过程
查询包含“搜索引擎”的文档
通过倒排索引获得“搜索引擎”对应的文档id列表,有1,3
通过正排索引查询1和3的完整内容
返回最终结果
倒排索引-组成
单词词典(Term Dictionary)
倒排列表(Posting List)
单词词典(Term Dictionary)
单词词典的实现一般用B 树,B 树构造的可视化过程网址:B Tree Visualization
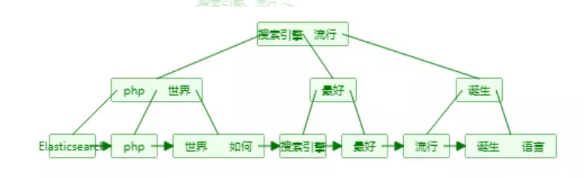
倒排列表(Posting List)
倒排列表记录了单词对应的文档集合,有倒排索引项(Posting)组成
倒排索引项主要包含如下信息:
1.文档id用于获取原始信息
2.单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分
3.位置(Posting),记录单词在文档中的分词位置(多个),用于做词语搜索(Phrase Query)
4.偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示
B 树内部结点存索引,叶子结点存数据,这里的 单词词典就是B 树索引,倒排列表就是数据,整合在一起后如下所示
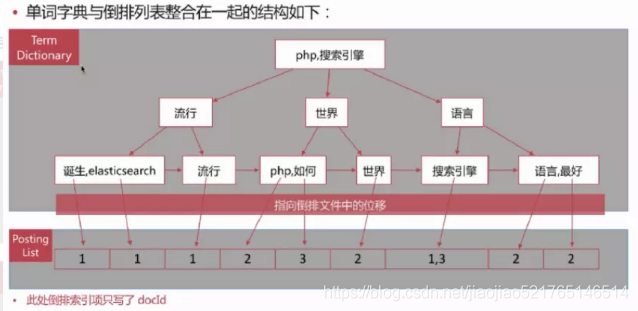
ES存储的是一个JSON格式的文档,其中包含多个字段,每个字段会有自己的倒排索引
倒排索引的结构
包含这个关键词的document list
包含这个关键词的所有document的数量:IDF(inverse document frequency)
这个关键词在每个document中出现的次数:TF(term frequency)
这个关键词在这个document中的次序
每个document的长度:length norm
包含这个关键词的所有document的平均长度
倒排索引不可变的好处
- 不需要锁,提升并发能力,避免锁的问题
- 数据不变,一直保存在OS Cache中,只要Cache内存足够
- filter cache一直驻留在内存,因为数据不变
- 可以压缩,节省CPU和Io开销
2.Dubbo和SpringCloud的区别, Dubbo 有什么致命缺点 ?
通讯协议上的区分
Dubbo由于是二进制的传输,占用带宽会更少.
SpringCloud是http协议传输,带宽会比较多,同时使用http协议一般会使用JSON报文,消耗会更大.
注册中心上的区分
SpringCloud的接口协议约定比较自由且松散,需要有强有力的行政措施来限制接口无序升级.
Dubbo的注册中心可以选择ZK,Redis等多种,springcloud的注册中心只能用Eureka或者自研.
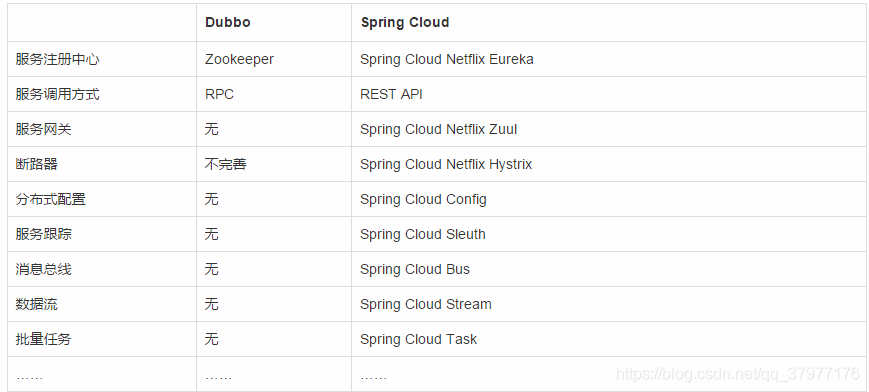
Dubbo 的致命缺点
Dubbo的开发难度较大,原因是Dubbo的jar包依赖问题很多大型工程无法解决.
Dubbo 仅仅是微服务的一种框架,不是一套技术栈.
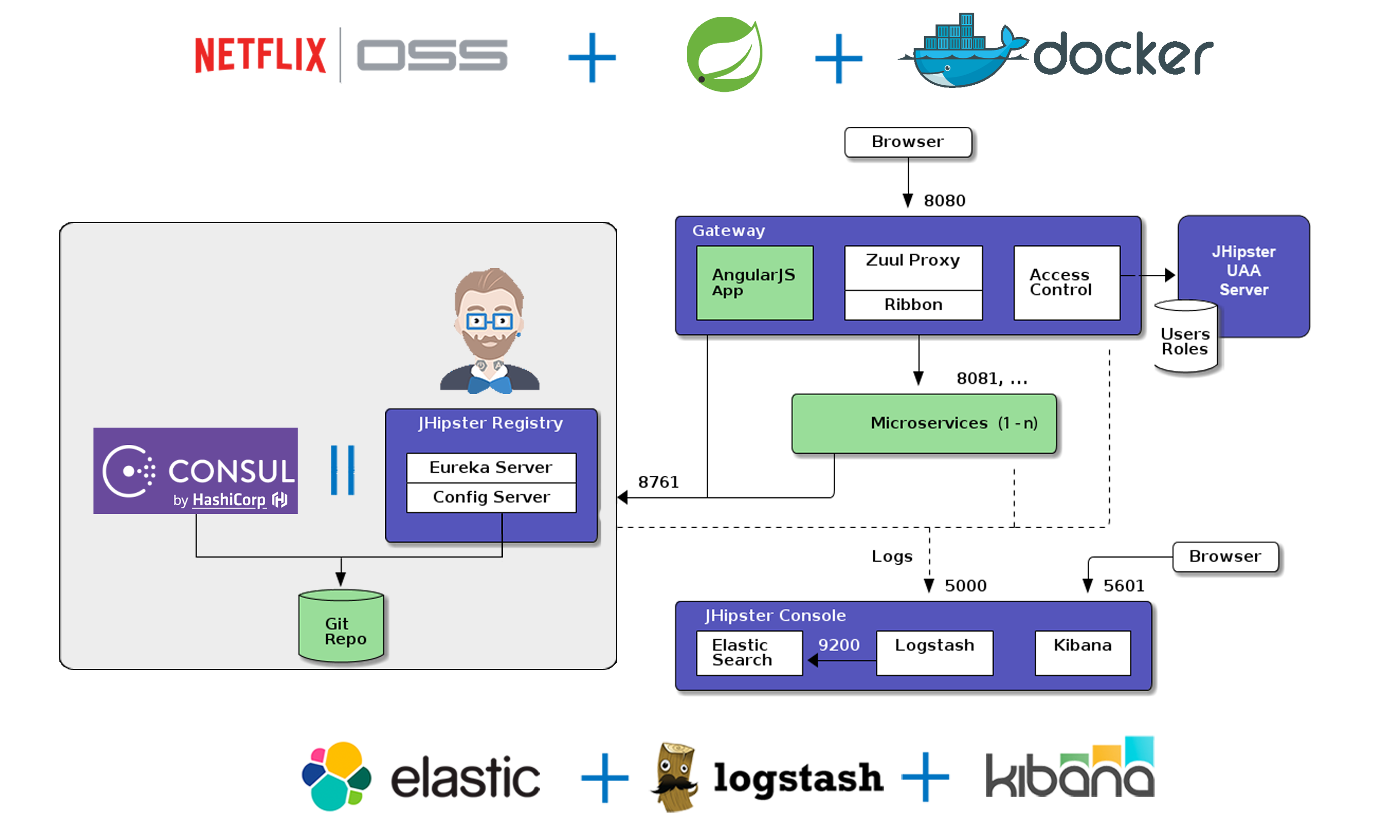
SpringCould-JHipster 微服务架构
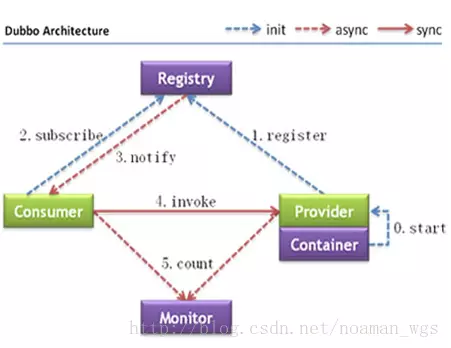
Dubbo 微服务架构
3.Kafaka队列底层原理
Kafka 是一个高吞吐量,分布式的发布-订阅消息系统;

Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。

**微信扫描二维码,关注我的公众号
**
专注分享Java干货, 提高编码实力 , 助力读者月入20K , 点击在看即可帮助更多人.






 京公网安备 11010802041100号
京公网安备 11010802041100号