密码学第一次实验,主要是对古典密码和流密码的利用与破解。
任务一当流密码的一次性密钥被使用多次时就不再具有语义安全性,可以结合多个密文破解出明文。
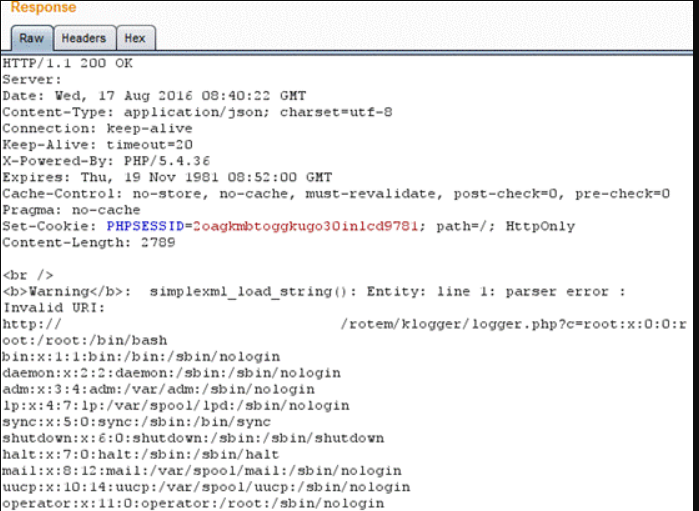
题目链接:Coursera | Online Courses & Credentials From Top Educators. Join for Free | Coursera
空格space的ASCII码为0010 0000,大写字母A~Z的ASCII码为01000001~01011010,小写字母a~z的ASCII码为 01100001~01111010。因此可以用space和字母做XOR操作,对字母进行大小写切换;而两个字母做XOR操作,结果将不在字母范围内。
又由于将两个密文做XOR操作相当于将两个密文对应的明文做XOR操作,如果结果中某个位置出现字母,则说明这两个明文的其中一个在该位置可能为空格。故对11个密文两两做XOR操作,然后通过结果判断不同明文中可能存在空格的位置,然后将对应位置上的密文和space做XOR操作,就可得到对应位置的密钥信息,当获取到足够多的密钥信息后,即可对目标密文进行解密。
NUM_CIPHER = len(ciphertexts)
THRESHOLD_VALUE = 7 # 认为该位置是空格的阈值
def strxor(a, b):
if len(a) > len(b):
return "".join([chr(ord(x) ^ ord(y)) for (x, y) in zip(a[:len(b)], b)])
else:
return "".join([chr(ord(x) ^ ord(y)) for (x, y) in zip(a, b[:len(a)])])
def letter_position(s):
position = []
for idx in range(len(s)):
if ('A' <= s[idx] <= 'Z') or ('a' <= s[idx] <= 'z') or s[idx] == chr(0):
position.append(idx)
return position
def find_space(cipher):
space_position = {}
space_possible = {}
# 两两异或
for cipher_idx_1 in range(NUM_CIPHER):
space_xor = []
c = ''.join(
[chr(int(d, 16)) for d in [cipher[cipher_idx_1][i:i + 2] for i in range(0, len(cipher[cipher_idx_1]), 2)]])
for cipher_idx_2 in range(NUM_CIPHER):
# 16进制字符串转ascii码
e = ''.join([chr(int(d, 16)) for d in
[cipher[cipher_idx_2][i:i + 2] for i in range(0, len(cipher[cipher_idx_2]), 2)]])
plain_xor = strxor(c, e)
if cipher_idx_2 != cipher_idx_1:
# 记录可能的空格位置
space_xor.append(letter_position(plain_xor))
space_possible[cipher_idx_1] = space_xor
for cipher_idx_1 in range(NUM_CIPHER):
spa = []
for position in range(400):
count = 0
for cipher_idx_2 in range(NUM_CIPHER - 1):
if position in space_possible[cipher_idx_1][cipher_idx_2]:
count += 1
if count > THRESHOLD_VALUE:
spa.append(position)
space_position[cipher_idx_1] = spa
return space_position
# 破解出密钥key
def calculate_key(cipher):
key = [0] * 200
space = find_space(cipher)
for cipher_idx_1 in range(NUM_CIPHER):
for position in range(len(space[cipher_idx_1])):
idx = space[cipher_idx_1][position] * 2
a = cipher[cipher_idx_1][idx] + cipher[cipher_idx_1][idx + 1]
key[space[cipher_idx_1][position]] = int(a, 16) ^ ord(' ')
key_str = ""
for k in key:
key_str += chr(k)
return key_str
result = ""
key = calculate_key(ciphertexts)
key_hex = ''.join([hex(ord(c)).replace('0x', '') for c in key])
f = ''.join([chr(int(d, 16)) for d in [ciphertexts[10][i:i + 2] for i in range(0, len(ciphertexts[10]), 2)]])
for letter in strxor(f, key):
if ' ' <= letter <= '~ ':
result += letter
print(result)
破解出的16进制密钥为
key_hex = "66396e89c9dbd8cb9874352acd6395102eafce78aa7fed28a006bc98d29c5b69b0339a19f8aa401a9c6d708f80c066c763fef0123148cdd8e82d05ba98777335daefcecd59c433a6b268b60bf4ef03c9a61100bb09a3161edc704a3"
将密钥与明文异或,破解出的第8组明文为

看到破解出的文本中有轻微错误,可以通过调整认为该位置是空格的阈值和两两异或密文的个数,多次进行尝试。最后分析出第8组的明文为“ We can see the point where the chip is unhappy if a wrong bit is sent and consumes”。
任务二给出一段密文和加密程序,告知明文只包含大小写字母、标点符号和空格,没有数字和其他字符。
加密程序关键如下
if (ch!='\n') {
fprintf(fpOut, "%02X", ch ^ key[i % KEY_LENGTH]); // ^ is logical XOR
i++;
}
}
本质上是密钥重复使用问题,假设密钥长度为klen,则相隔n*klen的密文使用同一密钥进行加密。所以首先猜测密钥长度klen,再将密文分割成klen组,对每一组遍历密钥的所有可能取值,并与密文异或,找到并记录异或结果全为明文字符的可能密钥值。
爆破密钥长度和可能密钥值
# 找出可以与subarr中的值异或成可显示字符的密钥值
# subarr是在Vigenere密码中用同一密钥加密的密文
def findkey(sub_arr):
required_chars = [chr(32), chr(33), chr(34), chr(44), chr(45), chr(46), chr(58), chr(63), chr(95)] # 标点和空格
for x in range(65, 91):
required_chars.append(chr(x)) # 大写字母
for x in range(97, 123):
required_chars.append(chr(x)) # 小写字母
# print(required_chars)
all_keys = []
res_keys = []
for x in range(0x00, 0xff + 1): # 枚举当前字节处所有可能的密钥
all_keys.append(x)
res_keys.append(x)
for i in all_keys:
for s in sub_arr:
if chr(s ^ i) not in required_chars:
res_keys.remove(i)
break
return res_keys
ciphertext = "F96DE8C227A259C87EE1DA2AED57C93FE5DA36ED4EC87EF2C63AAE5B9A7EFFD673BE4ACF7BE8923C\
AB1ECE7AF2DA3DA44FCF7AE29235A24C963FF0DF3CA3599A70E5DA36BF1ECE77F8DC34BE129A6CF4D126BF\
5B9A7CFEDF3EB850D37CF0C63AA2509A76FF9227A55B9A6FE3D720A850D97AB1DD35ED5FCE6BF0D138A84C\
C931B1F121B44ECE70F6C032BD56C33FF9D320ED5CDF7AFF9226BE5BDE3FF7DD21ED56CF71F5C036A94D96\
3FF8D473A351CE3FE5DA3CB84DDB71F5C17FED51DC3FE8D732BF4D963FF3C727ED4AC87EF5DB27A451D47E\
FD9230BF47CA6BFEC12ABE4ADF72E29224A84CDF3FF5D720A459D47AF59232A35A9A7AE7D33FB85FCE7AF5\
923AA31EDB3FF7D33ABF52C33FF0D673A551D93FFCD33DA35BC831B1F43CBF1EDF67F0DF23A15B963FE5DA\
36ED68D378F4DC36BF5B9A7AFFD121B44ECE76FEDC73BE5DD27AFCD773BA5FC93FE5DA3CB859D26BB1C63C\
ED5CDF3FE2D730B84CDF3FF7DD21ED5ADF7CF0D636BE1EDB79E5D721ED57CE3FE6D320ED57D469F4DC27A8\
5A963FF3C727ED49DF3FFFDD24ED55D470E69E73AC50DE3FE5DA3ABE1EDF67F4C030A44DDF3FF5D73EA250\
C96BE3D327A84D963FE5DA32B91ED36BB1D132A31ED87AB1D021A255DF71B1C436BF479A7AF0C13AA14794"
arr = [] # 将16进制密文划分成8位2进制数
for x in range(0, len(ciphertext), 2):
arr.append(int(ciphertext[x:2 + x], 16))
for key_length in range(1, 14): # 密钥长度1~13
for class_number in range(0, key_length): # 密文划分成key_length类,每一类和同一密钥值异或
sub_arr = arr[class_number::key_length] # 分割出同一组的密文
res_keys = findkey(sub_arr)
print('key_length= ', key_length, 'class_number= ', class_number, 'keys= ', res_keys)
if len(res_keys) > 1: # 如果有多个可能的密钥值,查看具体明文情况进行选择
for x in res_keys:
print(x)
for s in sub_arr:
print(chr(s ^ x), end='')
print("\n")
结果为
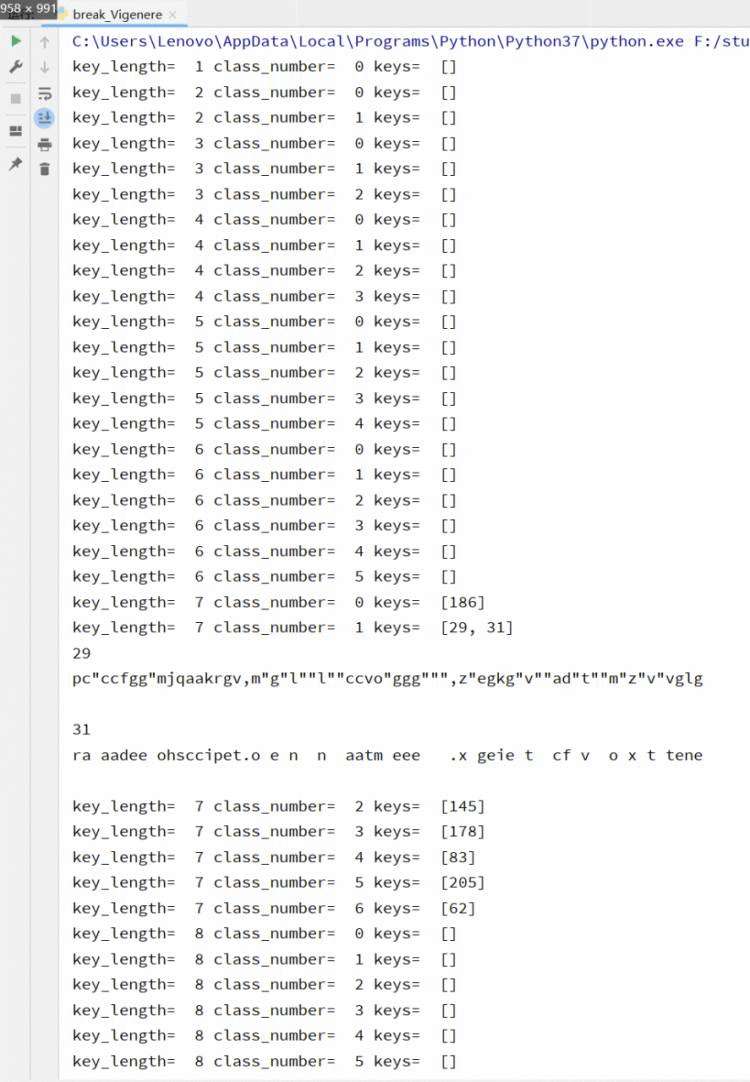
可以看到只有在密钥长度为7时,找到了可能密钥值,其中第一组有两个可能密钥值,分析异或结果判断密钥是31的概率更高,得到密钥为[186, 31, 145, 178, 83, 205, 62]。
直接用密钥解密
keys = [186, 31, 145, 178, 83, 205, 62]
plaintext = ""
for i in range(0, len(arr)):
plaintext = plaintext + chr(arr[i] ^ keys[i % len(keys)]) # 解密
print(plaintext)
结果为
任务三Cryptography is the practice and study of techniques for, among other things, secure communication in the presence of attackers. Cryptography has been used for hundreds, if not thousands, of years, but traditional cryptosystems were designed and evaluated in a fairly ad hoc manner. For example, the Vigenere encryption scheme was thought to be secure for decades after it was invented, but we now know, and this exercise demonstrates, that it can be broken very easily.
题目链接:Challenge 6 Set 1 - The Cryptopals Crypto Challenges
这一题可以认为是上一题的加强。
猜测密钥长度后,将密文分成相应长度块,计算相邻块间的汉明距离,具有最小归一化汉明距离的块长度很可能是真实密钥长度。
用字母频率分析的方法爆破当前位置的密钥。
import string
import re
from operator import itemgetter, attrgetter
import base64
def English_Scoring(t):
letter_frequency = {
'a': .08167, 'b': .01492, 'c': .02782, 'd': .04253,
'e': .12702, 'f': .02228, 'g': .02015, 'h': .06094,
'i': .06094, 'j': .00153, 'k': .00772, 'l': .04025,
'm': .02406, 'n': .06749, 'o': .07507, 'p': .01929,
'q': .00095, 'r': .05987, 's': .06327, 't': .09056,
'u': .02758, 'v': .00978, 'w': .02360, 'x': .00150,
'y': .01974, 'z': .00074, ' ': .15000
}
return sum([letter_frequency.get(chr(i), 0) for i in t.lower()]) # 总字母频率
def Single_XOR(s, single_character):
t = b''
# s = bytes.fromhex(s)
# t = the XOR'd result
for i in s:
t = t + bytes([i ^ single_character])
return t
def ciphertext_XOR(s):
_data = []
# s = bytes.fromhex(s)
# key = ord (single_character)
# ciphertext = b''
for single_character in range(256):
ciphertext = Single_XOR(s, single_character)
score = English_Scoring(ciphertext)
data = {
'Single character': single_character,
'ciphertext': ciphertext,
'score': score
}
_data.append(data)
score = sorted(_data, key=lambda score: score['score'], reverse=True)[0] # 字母频率最大的
return score
def Repeating_key_XOR(_cipher, _key): # 破解出明文
message = b''
length = len(_key)
for i in range(0, len(_cipher)):
message = message + bytes([_cipher[i] ^ _key[i % length]])
return message
# 计算汉明距离
def hamming_distance(a, b):
distance = 0
for i, j in zip(a, b):
byte = i ^ j
distance = distance + sum(k == '1' for k in bin(byte)) # 转成二进制
return distance
# 猜测密钥长度
def Get_the_keysize(ciphertext):
data = []
for keysize in range(2, 41):
block = [ciphertext[i:i + keysize] for i in range(0, len(ciphertext), keysize)] # 划分成等长的块
distances = []
for i in range(0, len(block) - 1, 1): # 逐个计算两个相邻块之间的汉明距离
block1 = block[i]
block2 = block[i + 1]
distance = hamming_distance(block1, block2)
distances.append(distance / keysize)
_distance = sum(distances) / len(distances)
_data = { # 记录长度和归一化距离
'keysize': keysize,
'distance': _distance
}
data.append(_data)
_keysize = sorted(data, key=lambda distance: distance['distance'])[0] # 具有最小归一化汉明距离的KEYSIZE,很可能是真实密钥长度
return _keysize
def Break_repeating_key_XOR(ciphertext):
_keysize = Get_the_keysize(ciphertext) # 猜测得到的密钥长度
keysize = _keysize['keysize']
print(keysize)
key = b''
message = b''
block = [ciphertext[i:i + keysize] for i in range(0, len(ciphertext), keysize)]
for i in range(0, keysize):
new_block = []
t = b''
for j in range(0, len(block) - 1):
s = block[j]
t = t + bytes([s[i]]) # 相同位置的组合在一起,被同一密钥加密
socre = ciphertext_XOR(t)
key = key + bytes([socre['Single character']]) # repeating-key
# cipher = cipher + socre['ciphertext']
for k in range(0, len(block)):
message = message + Repeating_key_XOR(block[k], key)
return message, key
if __name__ == '__main__':
with open('6.txt') as of:
ciphertext = of.read()
ciphertext = base64.b64decode(ciphertext) # base64解密,解密后为bytes
message, key = Break_repeating_key_XOR(ciphertext)
print("message:", bytes.decode(message), "\nkey:", bytes.decode(key))

题目链接:Level II Challenges | MysteryTwister — The Cipher Contest
给出用户输入密码所使用的按键,密码的长度和密码SHA1之后的值。
简单的爆破问题,假设每个键只按了一次,再分析出所有可能的按键组合。
import hashlib
import itertools
import datetime
hash1 = "67ae1a64661ac8b4494666f58c4822408dd0a3e4"
str1 = "QqWw%58(=0Ii*+nN" # 字符集合
str2 = [['Q', 'q'], ['W', 'w'], ['%', '5'], ['8', '('], ['=', '0'], ['I', 'i'], ['*', '+'], ['n', 'N']]
def sha_encrypt(str):
hash = hashlib.sha1()
hash.update(str.encode('utf-8'))
encrypts = hash.hexdigest()
return encrypts
st3 = "0" * 8 # 假设每个键只按了一次,len(key)=8
str4 = ""
str3 = list(st3)
starttime = datetime.datetime.now()
for a in range(0, 2): # 共256种组合
str3[0] = str2[0][a]
for b in range(0, 2):
str3[1] = str2[1][b]
for c in range(0, 2):
str3[2] = str2[2][c]
for d in range(0, 2):
str3[3] = str2[3][d]
for e in range(0, 2):
str3[4] = str2[4][e]
for f in range(0, 2):
str3[5] = str2[5][f]
for g in range(0, 2):
str3[6] = str2[6][g]
for h in range(0, 2):
str3[7] = str2[7][h]
newS = "".join(str3)
for i in itertools.permutations(newS, 8):
str4 = sha_encrypt("".join(i))
if str4 == hash1:
print("password:", ("".join(i)))
endtime = datetime.datetime.now()
print("time:", ((endtime - starttime).seconds), "s")
password: (Q=win*5 time: 7 s




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有