我最近在波鸿鲁尔大学开始了机器学习的博士学位研究。 我加入的小组的主要研究主题之一是慢特征分析(SFA)。 要学习一个新主题,我喜欢看示例和直观的解释,如果可能的话,让自己沉浸在数学上的严谨中。 我为其他喜欢以类似方式接触学科的人写了这篇博客文章,因为我认为SFA既强大又有趣。
在本文中,我将以一个应用SFA的代码示例为指导,以帮助激发该方法。 然后,我将详细介绍该方法背后的数学原理,最后提供指向该材料上其他良好资源的链接。
1.确定一个平滑的潜在变量
SFA是一种无监督的学习方法,可以从时间序列中提取最平滑(最慢)的基础功能或特征 。 这可以用于降维,回归和分类。 例如,我们可以有一个高度不稳定的级数,该级数由更好的行为潜变量确定。
让我们开始生成时间序列D和S:
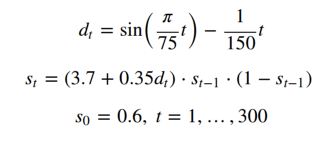
这称为后勤图。 通过绘制序列S ,我们可以检查其混沌性质。 驱动上面曲线的行为的基本时间序列D简单得多:
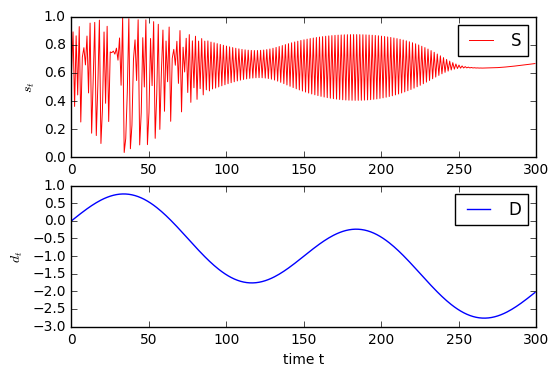
我们如何从不稳定的时间序列中确定简单的基础驱动力?
我们可以使用SFA来确定功能最缓慢变化的功能。 在我们的情况下,我们将以S之类的数据开始,以D结束,而不必事先知道S是如何生成的。
SFA的实现旨在寻找线性输入的特征。 但是从示例中我们可以看到,驱动力D是高度非线性的! 这可以通过首先对时间序列S进行非线性扩展,然后找到扩展数据的线性特征来解决。 通过这样做,我们找到了原始数据的非线性特征。
让我们通过在上面堆叠S的延时副本来创建一个新的多元时间序列:

接下来,我们对数据进行三次扩展并提取SFA特征。 立方膨胀变成一个4维向量[A,B,C,d]ᵀ与元件t³,t²v,电大,吨 ²,电视,t代表不同T,U,V∈{A,B的34元素矢量,c,d}。
请记住,每个问题要添加的最佳时间延迟副本数各不相同。 或者,如果原始数据的维数太高,则需要进行降维,例如使用主成分分析 。
因此,将以下内容视为该方法的超参数:维数展开(缩小)方法,展开后的输出尺寸(缩小)和要找到的慢特征数量。
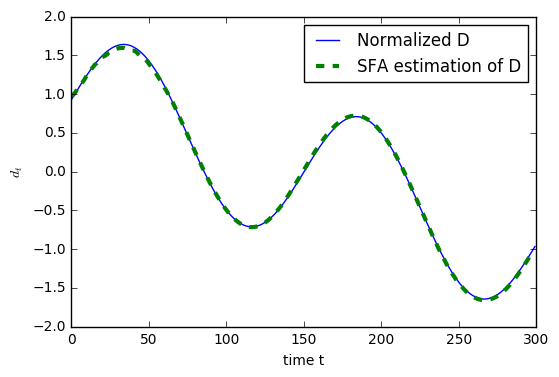
现在,在添加延时复制后,时间序列的长度从300更改为297。因此,慢特征时间序列的相应长度也为297。 为了在此处更好地进行可视化,我们通过在第一个值之前加上最后一个值两次来将其长度更改为300。 SFA发现的特征的均值和单位方差为零,因此我们在可视化结果之前也将D归一化。
即使仅考虑300个数据点,SFA功能也几乎可以完全恢复基础源-令人印象深刻!
2.那么到底发生了什么?
从理论上讲,SFA算法接受一个(多元)时间序列X和一个整数m来表示输入,该整数m指示要从该序列中提取的特征数量,其中m小于时间序列的维数。 该算法确定m个函数
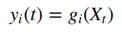
这样使得每个y 1的两个连续时间点的平方时间导数的平方最小。 直观地,我们希望最大化功能的慢度:
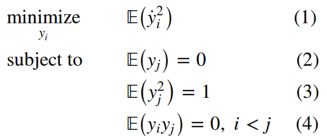
其中的点表示时间导数,在离散情况下:
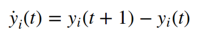
目标函数(1)测量特征的慢度。 零均值约束(2)使特征的第二矩和方差相等,并简化了表示法。 单位方差约束(3)放弃常数解。
最终约束(4)对我们的特征进行解相关,并导致其缓慢性排序。 这意味着我们首先找到最慢的特征,然后找到与它之前的正交的下一个最慢的特征,依此类推。 对功能进行解相关可确保我们捕获最多的信息。
在下文中,我浏览了重要的细节并跳过了步骤,但是为了完整起见,我想将其包括在内。 我建议也查看下面的链接以获取更详尽的解释。
让我们只考虑线性特征:
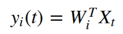
时间序列X可以是“原始数据”或它的非线性扩展,请参见上面的示例。 请记住,即使这些是扩展数据的线性特征,它们仍然可以是原始数据的非线性特征。
假设均值X为零,则通过求解广义特征值问题 AW = BWΛ找到线性特征。 我们确定米特征值-特征向量的元组(λᵢ,Wᵢ),使得A =Wᵢλᵢ 乙 Wᵢ,在那里我们有
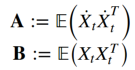
标量λᵢ表示特征的慢度,即λᵢ越小 ,相应y varying的变化就越慢。 如果您熟悉广义特征值问题,请注意此处的特征值在增加,而不会减少。 最后,特征向量Wᵢ是定义我们学习特征的变换向量。
3.进一步阅读
原始论文: https : //www.ini.rub.de/PEOPLE/wiskott/Reprints/WiskottSejnowski-2002-NeurComp-LearningInvariances.pdf
SFA在分类中的应用: http : //cogprints.org/4104/1/Berkes2005a-preprint.pdf
上面的示例改编自: http : //mdp-toolkit.sourceforge.net/examples/logmap/logmap.html
From: https://hackernoon.com/a-brief-introduction-to-slow-feature-analysis-18c901bc2a58






![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号