篇首语:本文由编程笔记#小编为大家整理,主要介绍了回龙观大叔狂磕mysql(第二回)相关的知识,希望对你有一定的参考价值。同学,还记得上一回说的回龙观大叔面试的故事嘛?
篇首语:本文由编程笔记#小编为大家整理,主要介绍了回龙观大叔狂磕mysql(第二回)相关的知识,希望对你有一定的参考价值。
同学, 还记得上一回说的回龙观大叔面试的故事嘛?
经过上一回合的学习, 这位大叔终于找回了点自信, 这次又投了几家公司, 不过现在还没有公司去联系他.
大叔的电脑桌放在阳台上, 这是个绝佳的位置, 每天清晨惺忪的阳光都能照进来, 但大叔可不想坐在那每天晚上数星星、白天晒太阳, 当小区里面的年轻人还在熟睡的时候, 大叔早已经坐在书桌前开始继续瞌 mysql 的知识了.
以下知识均为大叔周末聊天时的口述, 我这里整理下大概知识点.
大叔: 小兄弟, 大叔是面试的过来人, 这回合的知识很重要, 可要避免重走我的老路呀~
InnoDB管理存储空间的基本单位: 页
我把 Innodb 比喻成一本书, 那么基本存储单位就是页, 一个页的大小大约是16KB. 页的类型也不一样, 在书里面有目录页、附录页、内容页, Innodb 根据不同功能也有很多类型的页, 比如存放INODE信息的页、存放 undo 日志信息的页、存放数据索引的页等等.
这是一行数据的底层存储结构, 看看我调的色都么清新~
下面大叔解释淡绿框字段的含义:
1.delete_mask
被删除的记录还在页中么? 他不会立即从页中真正的移除掉, 行记录中 delete_mask 就是标记已删除的记录, 所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉
如果面试官要问你, 为什么删除掉记录不真正移除掉?
你就答: 记录与记录之间是有关联关系的, 移除它们之后把其他的记录在磁盘上重新排列需要性能消耗.
2.min_rec_mask
min_rec_mask 用来标记 B+树 的每层非叶子节点中的最小记录
3.heap_no
用来标记当前记录的页位置, 页中行数据排列顺序也是从小到大顺序排列的, 值得一提的是每个页中自动加了两条虚拟记录, 一个记录的是当前页的主键最大记录, 一个记录的是最小记录. 也就是上一回合提到的每个 page页 最少两条记录的原因
4.record_type
当前行记录类型
类型值 |
含义 |
0 |
普通记录(通常我们插入的数据记录) |
1 |
B+树非叶节点记录(索引数据) |
2 |
页最小记录(虚拟记录) |
3 |
页最大记录(虚拟记录) |
5.空间换性能 next_record
6.n_owned
n_owned 表示该组内共有几条记录
我问大叔具体这个是啥意思啊, 大叔说他没搞明白, 如果面试官继续问就说不知道就可以了, 技术圈一般都已点到为止, 不用深究.
slot
查找一条记录, 我们需要遍历所有页嘛? 在数据量少的情况, 我们可以根据页中存的最大最小记录查找, 但是数据量一多, 肯定也是无法忍受的. 那 innodb 是怎么做的呢?
我们还是拿书举例子, 书也是一页一页的, 我们怎么快速定位到某一章某一节的某一段内容呢? 聪明的小伙伴肯定回答是: 目录。
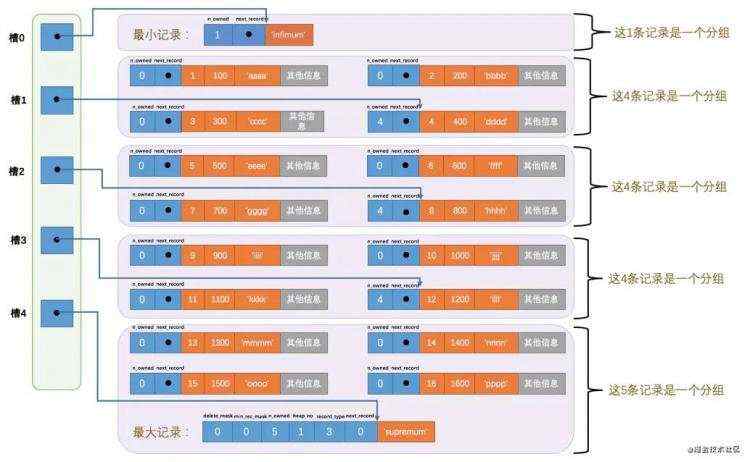
没错, 我们看看 mysql 是怎么实现页 ”页级别目录“ 的
 (此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
(此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
简单来说, 就是一个 page 页中最大8条记录分组, 将每组最小最大的值偏移量记录到 slot 槽中, 这里的 slot 就相当于目录的一个作用, 下面是一个查数过程:
-
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录
-
通过记录的 next_record 属性遍历该槽所在的组中的各个记录
B+树索引
听回龙观大叔说这是让他那天面试最心碎的地方, 需要我额外注意, 大家提起精神来啊~
大叔狂磕第一回我们就知道在一个数据页怎么定位数据了, 但是我们都是假设基于主键进行的查找哦。那么如果不是主键呢?
这个就很悲剧了, 因为在数据页中并没有对非主键列建立所谓的页目录,所以我们无法通过二分法快速定位相应的槽。这种情况下只能从最小记录开始依次遍历单链表中的每条记录,然后对比每条记录是不是符合搜索条件(下面会讲到索引, 解决这个遍历查询慢问题)
一个数据页大概只有 16KB, 我们数据一般不可能只有这些, 肯定需要多个数据页存储, 那么多个页之间是怎么管理的呢?
页和页之间是双向链表连接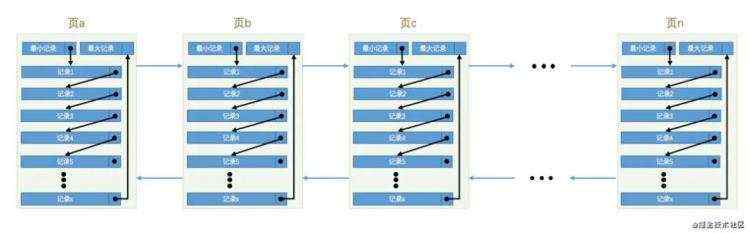 (此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
(此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
如果没有索引的话, 默认是从页a开始查知道页b、页c挨个查找, 直到满足指定的条件为止.
页分裂
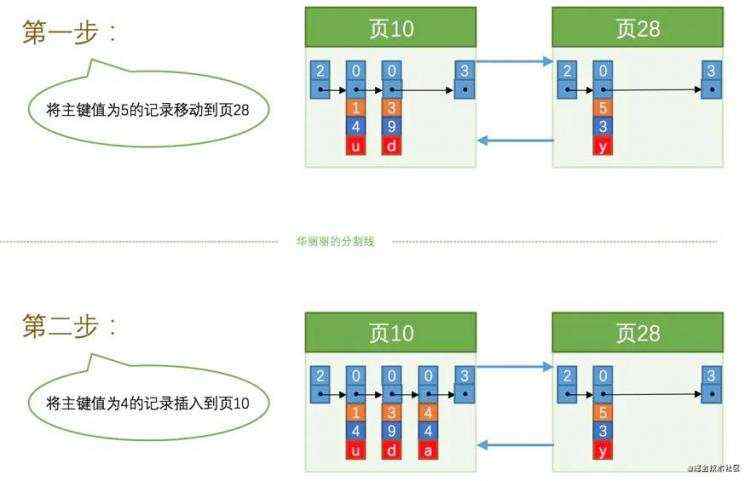
当数据页数据变大时, 将会由新增页来存储新数据, 这个过程就叫 页分裂.
比如下图是在页10中插入记录主键4, 而已存在记录主键5, 当页10已满时, 新创建页28, 进行的数据调整过程.
 (此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)]
(此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)]
大家忽略页号, 这个是没有实际作用的, 真正的前后关系是使用页之间双向链表维护的.
由上面的规则可以看出, 在对页中的记录进行增删改操作的过程中, 下一个数据页中的主键值必须大于上一个页中主键值, 所以我们一般设置主键都会设置自增, 这样是可以避免页满时数据进行交换调整.
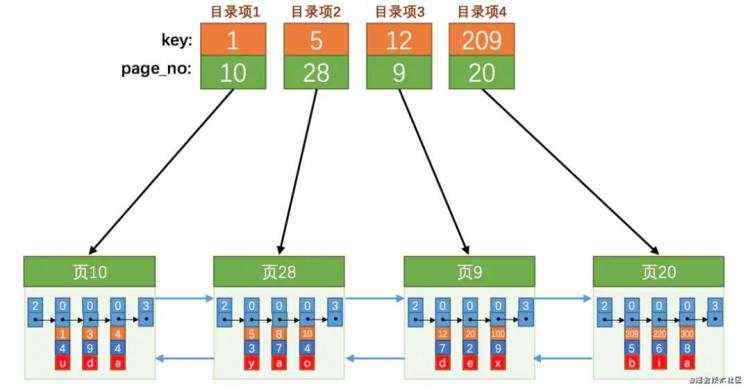
页内查询我们冗余 slot 空间来进行提高查询速度, 但是对于这么多页, 总不能一个页一个页的扫描吧. 当然不行!那我们再抽象一层.
 (此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
(此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
我们看这样扫描页是不是就很快了, 我们基于上面数据就可以很快定位到具体的页了.
key 就是我们说的索引
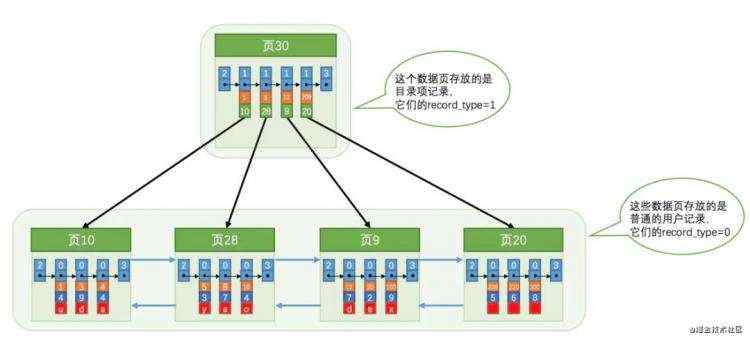 (此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
(此图为回龙观大叔所盗《mysql是怎样运行的》, 与本文作者无关)
如上图所示, 同数据页一样, 我们索引key也是也是页管理的, 还记得上面 record_type 类型么, record_type=1为 B+ 树非叶节点记录, 普通数据为 record_type=0
索引检索、slot检索都是通过二分查找算法实现的
如果数据量再大, 索引页也会变得更多, 那么我们该怎么办呢? 再抽象一层!
image.png
但是这里树的高度并不能无限扩增哦, 因为每一层都代表了一次磁盘IO, 层级高磁盘IO次数变多将会导致查询变慢. B+树本质增大层的宽度来降低树的高度, 所以一般我们树的高度也不会超过4层, 一个页节点存放1000条数据, 一层1000个节点, 四层则是1000X1000X1000X10000=100000000000!!!
聚簇索引索引
如上图, Innodb 将所有数据存在叶子节点, 我们通常称这种存储方式为聚簇索引.
我理解聚簇索引对于实现行锁是非常方便的, 主键查询条目比较少时,不用回行. 但是如果碰到不规则数据插入时,造成频繁的页分裂
MyISAM的索引方案也是树形结构,但是却将索引和数据分开存储的
回表与覆盖索引
当我们基于二级索引查找数据时, 会给二级索引同样建立一个类似的 B+ 树, 不过叶子节点存储的是主键的id, 再基于主键查询叶子节点数据, 这种行为我们称之为回表.
而我们查询字段正好与索引完全匹配, 不用再回表查询数据, 称为覆盖索引.
(此图为回龙观大叔所盗, 与本文作者无关)
联合索引
页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序. 这种记录模式决定了我们直接使用后面的字段是无法用到索引的, 因为单独它本身就是无序的.
索引可不是银弹
如果数据行数多和建立索引数据大, 索引是消耗存储空间的.
在增删改上都需要去修改各个B+树索引, 尤其对于无序的数据索引来说, 修改顺序的后果是将会频繁的进行插入修改页、页分裂, 对于 DML 性能来说是有损耗的.
只为用于搜索、排序或分组的列创建索引
通常我们只对索引数据分布广建立索引, 对于性别类是不适合建立索引的, B+树内节点变成了二节点, 叶子节点数据聚集严重.
索引列的类型小, 对于大类型列占据更多的存储空间, 检索效果不好, 可以选定索引字符串值的前缀.
与回龙观大叔总结
上一次见回龙观大叔, 距离现在过去才几天, 上次还抱怨找工作问他底层 mysql 知识, 这次感觉非常乐于学习并向我分享这些底层基础知识了. 但是一个跟我父亲年龄相仿还每天在努力学习、找砖搬的大叔, 我不知道是应该替他担心还是高兴.








 京公网安备 11010802041100号
京公网安备 11010802041100号