作者:vaaal52653 | 来源:互联网 | 2023-09-14 14:49
这周看了3篇对话系统的综述,主要是为了对对话系统有一个更深的了解,所以就把看的所有综述都放在一起了~~但是看完之后发现里面提到的一些具体的解决方法或者模型只看综述并不能很好的理解,所以还需要具体的看一下里面提出的论文!加油呀!!
- 《智能对话系统研究综述》
- 《A Survey on Dialogue Systems:Recent Advances and New Frontiers》
- 《对话系统评价方法综述》
智能对话系统研究综述_贾熹滨
论文主要内容(包含创新点以及不足)
学到的点
- 主要是了解了对话的类别、流程和自然语言生成的一些方法。具体还要继续看论文才能继续了解。
A Survey on Dialogue Systems:Recent Advances and New Frontiers
论文主要内容(包含创新点以及不足)
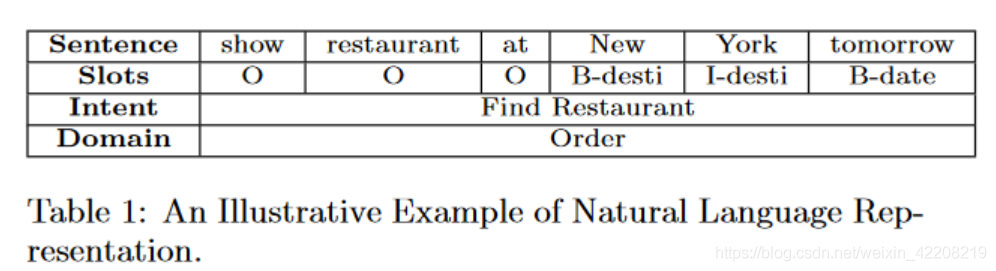
- 现有对话系统大致可以分为面向任务型对话和非面向任务型对话
- 面向任务型对话主要是针对某些特定的任务,比如订票订餐。
- 非面向任务型对话主要应用在娱乐等方面,例如聊天机器人。
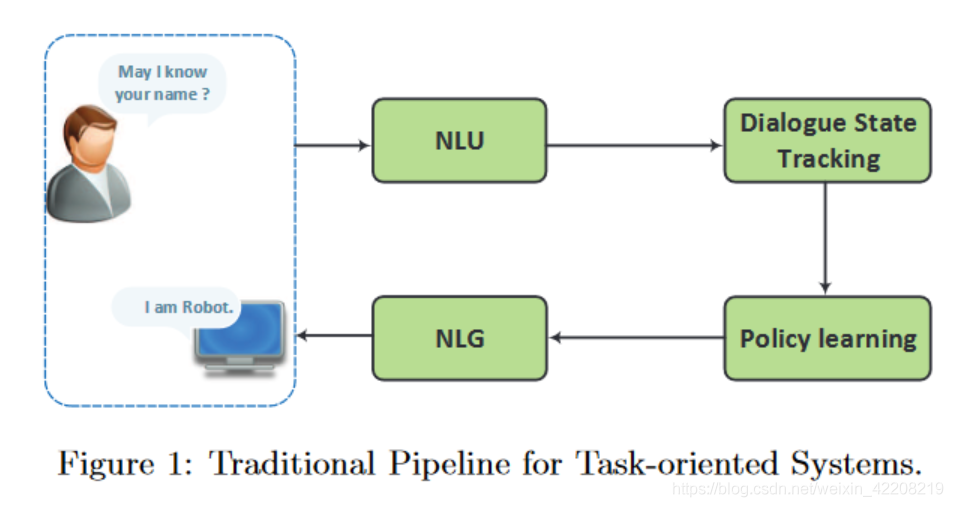
- 任务导向型对话主要介绍了两种方法,分别是pipeline和end2end
- 非任务导向型对话主要介绍了两种方法,分别是神经生成模型和基于检索的方法。
- 神经生成模型的基础是seq2seq,基于此,本论文还探索了当前的一些研究热点,如:结合背景信息,提高回复的多样性,主题和个性建模,利用外部知识库,互动学习与评估,每一部分都介绍了很多种方法,但是因为我还没有开始看里面的论文所以有很多方法我只能知道个大概,没有一个确切的了解。要好好读一下里面提到的论文!
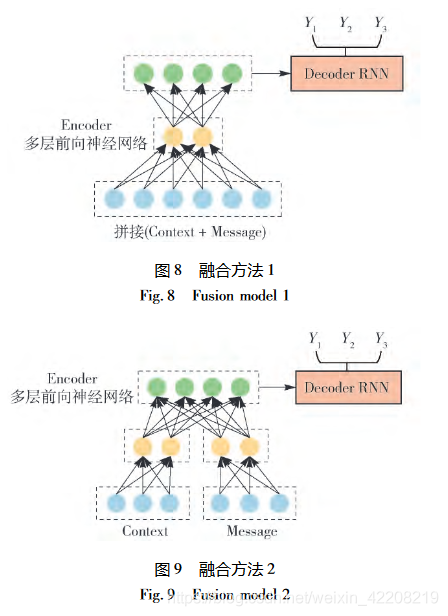
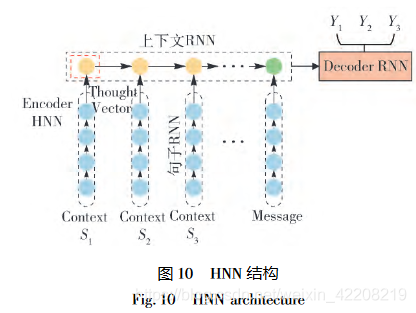
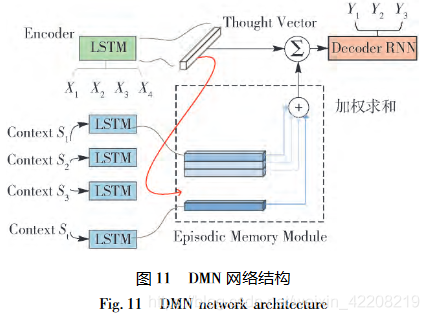
- 结合背景信息,个人感觉有点类似于《智能对话系统研究综述》里的seq2seq+context部分,但是本论文介绍的方法更多。
- 提高回复多样性,有点类似于上篇论文里的最大化互信息,但是又介绍了decoder解码过程中产生的冗余候选回复以及引入随即隐变量去提高回复多样性
- 主题与个性,有点类似于所有的对话要围绕一个主题,同时为了更好的用户体验,可以考虑给系统设定背景信息(这在上篇综述里也提到过)
- 利用外部知识库,用于弥补对话系统与人类之间背景知识差距
- 交互式学习,显然只让用户发问系统回答是不合理的,好的对话应该更有前瞻性和交互性
- 评价,目前的评价方法只有BLUE METEOR ROUGE,但是这个打分并不能完全代表回复的好坏
- 基于检索的方法主要是从若干个候选回复中选择一个回复,因此匹配模型一定要能够克服输入和回复之间的语义差异
- 单轮回复匹配,将当前消息和候选回复分别编码为向量,计算两个向量之间的匹配分数
- 多轮回复匹配,将当前消息与之前的对话作为输入,模型会选择与整个文本最相关且自然的回复。
- 混合方法。基于检索的方法回复准确但不流利,基于生成的方法回复更流利但有可能会生成无意义的回复,因此将两种方法结合。先通过检索的方法得到候选回复,再将其与原始信息一起送入基于RNN的回复生成器
- 结论,深度学习给对话系统带来了更好的可能性,也将任务导向型对话和非任务导向型对话的界限模糊了。未来研究方向主要有迅速热身,深度理解,隐私保护。但是除了隐私保护,我都不是很了解,后续会一直关注这篇论文!争取早日把它完全弄懂。
学到的点(感想)
这篇综述讲了很多方法和模型,但是因为我目前只是看了综述,所以很多方法和模型都还没有去了解,所以会一直看这篇论文,希望在阅读了别的论文之后能对这篇综述有更深的了解。
对话系统评价方法综述
论文主要内容(包含创新点以及不足)
-
主要是针对两种不同场景下的对话类型介绍了评价方法
-
任务导向型对话系统最终目标是测评用户的满意度,因此提出了三个策略,分别是通过构建某种特定形式的用户模拟系统进行评价;人工评价;在动态部署的系统中进行评价。
- 用户模拟:有效简单,最有可能覆盖最大空间,但是真实用户反映与模拟器的反应存在差距,差距的大小决定着模拟器的好坏,但这种方法仍然是任务型对话系统评价中最常用的评价方法。
- 人工评价:开销比较大,但是结果最真实。但是也有事实证明人工评价并没有非常完整的表现出对话的效果和特点。
- 部署动态系统评价:在真实用户群体中检测用户满意度
-
开放域对话系统评价方法主要有两种主流的方法,分别是客观评价指标和模拟人工评分。
-
未来趋势,对任务型对话,主要是根据任务完成程度来评价,对开放域对话系统,主要是对客观指标进行评分。
不懂的点
- 许多具体的解决问题的方法并不是很了解,只懂个大概,还需要继续阅读相关的文献。










 京公网安备 11010802041100号
京公网安备 11010802041100号