情感对话机:内部和外部记忆的情感对话生成 原文作者:Hao Zhou, Minlie Huang, Tianyang Zhang, Xiaoyan Zhu, Bin Liu
翻译作者:陈艺荣
翻译日期:2018年10月29日
| 中文关键词 | 英文关键词 |
| 情感对话机 人机对话系统 文本匹配 短文本分类 人机交互 | Emotional Chatting Machine Human-machine dialogue system Text matching Short text classification Human-Computer Interaction |
原文链接:https://arxiv.org/abs/1704.01074
作者源码:https://github.com/tuxchow/ecm
摘要
情感的感知和表达是对话系统或会话代理成功的关键因素。然而,到目前为止,尚未在大规模会话生成中研究该问题。 在本文中,我们提出情感对话机(ECM),它不仅可以在内容(相关和语法)中产生适当的响应,而且可以在情感中产生适当的响应(情绪一致)。据我们所知,这是第一个解决大规模会话生成中情感因素的研究。ECM使用三种新机制来解决情感因素:(1)通过嵌入情感类别来模拟情绪表达的高级抽象,(2)捕获内隐情绪状态的变化,以及(3)使用外部情感词汇实现明确的情感表达。实验表明,所提出的模型不仅可以生成合适的内容响应,还可以生成合适的情感响应。
1 引言
作为人类智力的重要组成部分,情商被定义为感知,整合,理解和调节情绪的能力(Mayer and Salovey 1997)。 人工智能的长期目标是使机器能够理解情绪和情感(Picard and Picard 1997)。为了创建能够在人类层面与用户通信的聊天机器人,有必要使机器具有感知和表达情感的能力。
现有研究表明,在对话系统或会话代理中解决情绪和情感可以提高用户满意度(Prendinger,Mori和Ishizuka,2005),并减少对话中的错误(Martinovski和Traum 2003)。 一些关于调整对话行为以适应用户的情绪状态(Polzin和Waibel 2000)以及在内容和情感相关的层次上产生对用户话语的响应方面(Skowron 2010)的研究工作已经得到开展。
然而,这些研究主要受心理学上的发现得到启发,要么是基于规则的,要么仅限于小规模数据。最近,在大规模数据上训练的神经模型显著改进了开放领域的对话生成(Ritter,Cherry和Dolan 2011; Vinyals和Le 2015; Shang,Lu和Li 2015; Serban et al。2016)。 这些模型中的大多数旨在提高会话生成的内容质量(Gu等人2016; Li等人2016a; Xing等人2017; Mou等人2016; Li等人2016b)。据我们所知,情感因素尚未在现有的对话生成神经模型中得到解决。Table 1显示了考虑/不考虑情感因素的一些例子。我们可以看到我们的ECM模型在情感上更具参与性,更善解人意。
| User: Worst day ever. I arrived late because of the traffic. |
| Basic Seq2Seq: You were late. ECM (Like): I am always here to support you. ECM (Happy): Keep smiling! Things will get better. ECM (Sad): It’s depressing. ECM (Disgust): Sometimes life just sucks. ECM (Angry): The traffic is too bad! |
Table 1: Conversations with/without considering emotion.
在解决大规模会话生成中的情感因素方面存在若干挑战。首先,在大规模语料库中很难获得高质量的情感标记数据,因为情感注释是一个相当主观的任务,情绪分类也具有挑战性。 其次,很难以自然和连贯的方式考虑情绪,因为我们需要平衡语法和情绪表达,如(Ghosh等人,2017)所述。最后,如我们的实验所示,简单地将情感信息嵌入现有的神经模型中,不能产生理想的情感响应,而只是产生难以察觉情感的一般表达(其中只包含对情绪非常含蓄或含糊的常见词语,相当于我们数据集中所有情感反应的73.7%)。
在本文中,我们解决了在开放领域对话系统中产生情感响应的问题,并提出了一种情感对话机(简称ECM)。为了获得ECM的大规模情感标记数据,我们在手动注释的语料库上训练神经分类器。分类器用于自动注释大规模会话数据以用于ECM的训练。为了在句子中自然而连贯地表达情感,我们设计了一个序列到序列(Seq2Seq)的生成模型,该模型配备了新的情绪表达生成机制,即用于捕获情绪表达的高级抽象的情感类别嵌入(emotion category embedding),用于动态平衡语法和情感的内部情感状态机(internal emotion state) ,以及帮助产生更明确和不含糊的情绪表达的外部情绪记忆(external emotion memory)。
总之,本文做出以下贡献:
1. 提出解决大规模会话生成中的情感因素。据我们所知,这是关于该主题的第一项研究工作。
2. 它提出了一个端到端的框架(称为ECM),将情感影响纳入大规模的会话生成当中。 它有三种新颖的机制:情感类别嵌入,内部情感记忆和外部记忆。
3. 它表明ECM可以产生比传统seq2seq模型更高得分的内容和情感响应。我们相信未来的工作,如善解人意的计算机代理和情感交互模型可以基于ECM进行。
2 相关工作
在人机交互(human-machine interactions)中,检测人类情感迹象并对其进行适当反应的能力可以丰富沟通。例如,善解人意的情感表达的显示增强了用户的表现(Partala和Surakka 2004),并且提高了用户满意度(Prendinger,Mori和Ishizuka 2005)。 (Prendinger和Ishizuka 2005)的实验表明,一种善解人意的计算机代理可以促进对交互的更积极的感知。 在(Martinovski和Traum 2003)中,作者表明如果机器能够识别用户的情感状态并敏感地对其作出反应,则可以避免许多故障。(Polzin和Waibel 2000)的工作介绍了如何根据用户的情感状态调整对话行为。Skowron(2010)提出了一种称为情感听众的会话系统,它可以在内容和情感相关的层面上响应用户的话语。
这些作品主要受到心理学发现的启发,要么基于规则,要么仅限于小规模数据,这使得它们难以应用于大规模的会话生成。 最近,序列到序列生成模型(Sutskever,Vinyals和Le 2014; Bahdanau,Cho和Bengio 2014)已成功应用于大规模会话生成(Vinyals和Le 2015),包括神经响应机器(Shang, Lu和Li 2015),等级复现模型(Serban et al.2015)和许多其他模型。 这些模型侧重于提高所产生的响应的内容质量,包括多样性促进(Li等人,2016a),考虑其他信息(Xing等人2017; Mou等人2016; Li等人2016b; Herzig等人,2017),并处理未知的单词(Gu et al.2016)。
然而,没有任何工作解决了大规模会话生成中的情感因素。 有几项研究从可控变量生成文本。(Hu et al.2017)提出了一种生成模型,它可以生成以语言的某些属性为条件的句子,例如情感和时态。在(Ghosh等人,2017)中提出了情感语言模型,该模型可以生成以上下文词和影响类别为条件的文本。(Cagan,Frank和Tsarfaty 2017)结合语法信息,使用情感和主题为文档生成评论。我们的工作在两个方面有所不同:1)先前的研究严重依赖于语言工具或文本生成中的定制参数,而我们的模型完全是数据驱动,无需任何手动调整; 2)先前的研究无法模拟输入帖子和响应之间的多种情感交互,相反,生成的文本只是继续主导语境的情绪。
3 情感对话机
3.1 背景:编码器 - 解码器框架
我们的模型基于常见的序列到序列(seq2seq)模型(Sutskever,Vinyals和Le 2014)的编码器-解码器框架。它采用门控循环单元(GRU)实施(Cho等人2014; Chung等人2014)。编码器把后序列 转换为隐藏层的表示
转换为隐藏层的表示 ,用下式表示为:
,用下式表示为:
 (1)
(1)
解码器将上下文向量和先前解码的字的嵌入作为输入,以使用另一个GRU更新其状态:
![s_{t}=GRU(s_{t-1},[c_{t};e(y_{t-1})])](https://private.codecogs.com/gif.latex?s_%7Bt%7D%3DGRU%28s_%7Bt-1%7D%2C%5Bc_%7Bt%7D%3Be%28y_%7Bt-1%7D%29%5D%29) (2)
(2)
其中,![[c_{t};e(y_{t-1})]](https://private.codecogs.com/gif.latex?%5Bc_%7Bt%7D%3Be%28y_%7Bt-1%7D%29%5D) 是两个向量的串联,用作GRU单元的输入。 上下文向量
是两个向量的串联,用作GRU单元的输入。 上下文向量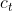 被设计为在解码期间动态地参与输入帖子的关键信息(Bahdanau,Cho和Bengio 2014)。 一旦获得状态向量
被设计为在解码期间动态地参与输入帖子的关键信息(Bahdanau,Cho和Bengio 2014)。 一旦获得状态向量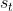 ,解码器通过从解码器的状态计算的输出概率分布
,解码器通过从解码器的状态计算的输出概率分布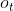 采样产生标志,如下:
采样产生标志,如下:
 (3)
(3)
 (4)
(4)
3.2 任务定义和概述
我们的问题表述如下:给定一个帖子和要生成的响应的情感类别(下面解释),目标是生成一个响应与情感类别一致。 本质上,该模型估计概率:。情感类别是{愤怒,厌恶,快乐,喜欢,悲伤,其他},采用中文情感分类挑战任务。
【未完待续】
【作者简介】陈艺荣,男,目前在华南理工大学电子与信息学院广东省人体数据科学工程技术研究中心攻读博士。曾获2次华南理工大学三好学生、华南理工大学“优秀共青团员”、新玛德一等奖学金(3000元,综测第3)、华为奖学金(5000元,综测第3)、汇顶科技特等奖学金(15000元,综测第1),两次获得美国大学生数学建模竞赛(MCM)一等奖,获得2016年全国大学生数学建模竞赛(广东赛区)二等奖、2017年全国大学生数学建模竞赛(广东赛区)一等奖、2018年广东省大学生电子设计竞赛一等奖等科技竞赛奖项,主持一项2017-2019年国家级大学生创新训练项目获得优秀结题,参与两项广东大学生科技创新培育专项资金、一项2018-2019年国家级大学生创新训练项目获得良好结题、4项华南理工大学“百步梯攀登计划”项目,发表SCI论文3篇授权实用新型专利5项,在受理专利17项(其中发明专利13项,11项进入实质审查阶段)。
我的Github
我的CSDN博客
我的Linkedin









 京公网安备 11010802041100号
京公网安备 11010802041100号