作者:lailai | 来源:互联网 | 2023-10-14 09:40
基本情况
- 题目:Single-view and multi-view depth fusion
- 出处:Fácil J M, Concha A, Montesano L, et al. Single-view and multi-view depth fusion[J]. IEEE Robotics and Automation Letters, 2017, 2(4): 1994-2001.
- video: https://www.youtube.com/watch?v=ipc5HukTb4k&feature=youtu.be
摘要
单目序列的密集和精确的三维映射是一项关键技术,在许多应用中仍然是一个开放的研究领域。这篇论文利用了基于单视图卷积网络(CNN)深度估计的最新结果,并将其与多视图深度估计相融合。这两种方法具有互补性。
多视点深度是高精度的,但仅在高纹理区域和高视差情况下。单视图深度捕捉中层区域的局部结构,包括无纹理区域,但估计深度缺乏全局一致性。我们提出的单视图和多视图融合在几个方面具有挑战性。
- 首先,这两个深度都与变形有关,变形依赖于图像内容。
- 其次,对于低视差的结构,高精度多视点的选择可能是困难的。
我们对这两个问题提出了自己的看法。我们在NYUv2和TUM的公共数据集中的结果表明,我们的算法优于单一和多视图方法。
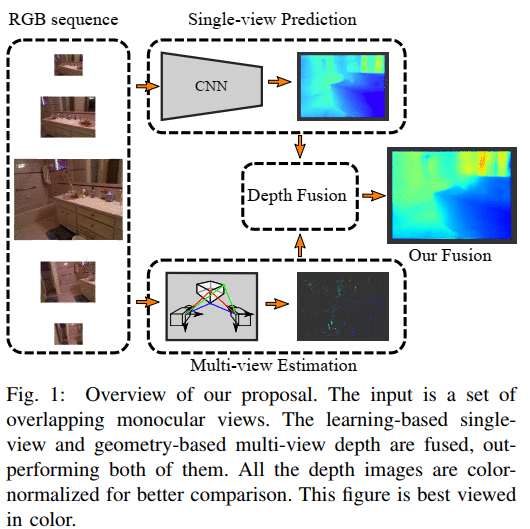
介绍
从一般的单眼序列估计在线,准确和密集的3D场景重建是计算机视觉中的基本研究问题之一。如今,该问题具有高度的相关性,因为它是几个新兴应用市场(增强和虚拟现实,自动驾驶汽车和机器人技术)中的一项关键技术。现有技术是所谓的直接映射方法[1],其通过基于若干视图中的对应像素之间的光度误差,通过最小化正则化的成本函数来估计图像深度。多视点深度估计的准确性主要取决于三个因素:
- 1)几何配置,低视差配置的精度较低;
- 2)只能可靠地估计高梯度像素的视图之间的对应关系的质量;
- 3)正则化函数,通常是总变化范数(Total Variation norm?),对于较大的无纹理区域而言是不准确的。
由于在大的低梯度区域上的这种较差的性能,有时仅在视觉直接SLAM的高梯度图像像素中估算半密集图(例如[2])。这样的半密集图在高视差配置中是准确的,但不是所查看多个视角的完整模型。低视差配置在视觉SLAM文献中通常被忽略。
另一种方法是单视图深度估计,由于使用了深度卷积网络[3],最近它的精度有了质的提高。对于高纹理和高视差点,其准确性仍低于多视图方法的准确性。但是,正如我们将在本文中争论的那样,深度卷积网络提高了多视图方法在低纹理区域的准确性,这是由于深度网络进行了高层次的特征提取,而不是多视图方法使用的低层次的高梯度像素。有趣的是,估计深度中的错误似乎是局部的,而不是全局相关的,因为它们来自深度学习功能。
本文的主要思想是
- 利用单视图和多视图深度图的信息来获得改进的深度,即使在低视差序列和低梯度区域中也是如此。
我们的贡献是
此任务有两个主要挑战。
- 首先,单视图估计的误差分布具有几种局部模式,因为它取决于图像内容,而不取决于几何结构。因此,单视图深度和多视图深度与内容依赖的变形(deformation)有关。
- 其次,在处理包括高和低视差配置在内的一般情况时,对多视图准确性进行建模并非易事。
我们提出了
- 一种基于加权的插值方法,该方法基于多视图半密集深度的质量和影响区域,基于单视图局部结构的加权插值,
并在两个公共数据集(NYU和TUM)中评估其性能。结果表明,我们的融合算法相对于单个单视图和多视图方法均得到了改进。
本文的其余部分安排如下。第二节介绍了最相关的相关工作。第三节提出并详细介绍了用于单视图和多视图融合的算法。第四节介绍了我们的实验结果,最后,第五节包含了这项工作的结论。








 京公网安备 11010802041100号
京公网安备 11010802041100号