2019独角兽企业重金招聘Python工程师标准>>> 
本篇开始从源码的角度分析下Lucene的根基Directory的实现,在此之前,我们先来看下Directory家族的层级分布式图:
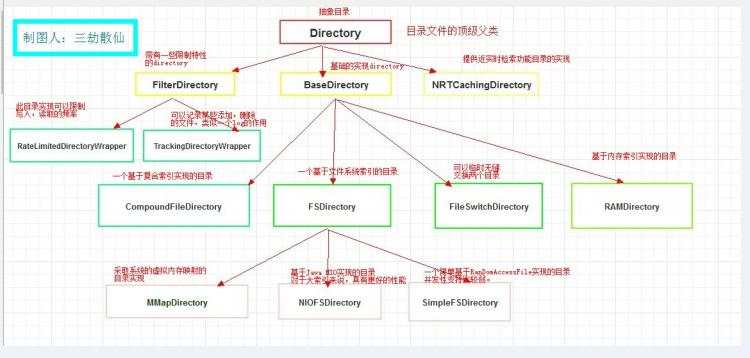
从上图中,我们可以看出Directory共有11个直接或间接的子类,不同子类的作用和功能不一样,那么Directory作为次继承图的顶级父类,在Lucene中确实发挥重要的根基作用,就像Hadoop的根基是HDFS一样,Directory肩负着索引存储的重任,如果没有存储,那么检索就无从谈起了,虽然我们经常称全文检索,搜索引擎什么的,其实他们的背后,Directory才是默默无闻的雷锋。
线面就来详细剖析Directory的核心实现:
Directory是由lucene中的一些索引文件组成的目录,一个典型的索引文件结构截图如下:
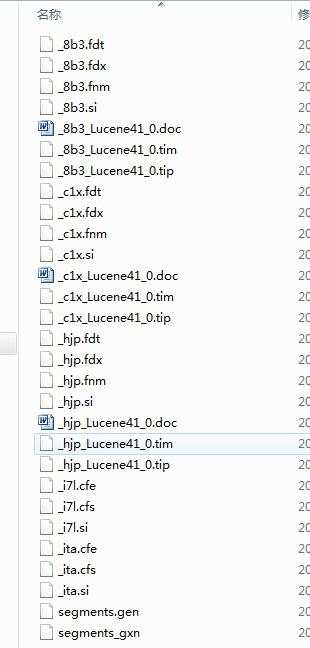
而Directory的作用,就是负责管理这些索引文件,包括数据的读取和写入,以及索引文件的添加、删除和合并。从这样的角度来分析,Directory更像一个系统的管理员,下面再具体分析一下核心方法的作用。
我们都知道lucene的索引体系,支持读共享,写独占的方式来访问索引目录,也就是说,它允许多个线程实例同时并发的读取,而不允许多个线程同时写入,大家可能会有疑问,为什么不支持多线程写入呢?这其实是因为索引目录有自己的某一时刻的内部状态,比如说文件指针,而多线程写入时,会造成指针混乱,从而引起索引结构或某些数据丢失,所以lucene任何时候都禁止有多个线程并发的写入索引,即使是多线程写,每次也只能通过队列的方式,一次只允许一个线程操作索引,按这样的情况分析,多线程写入与单线程写入,在性能上的提升,并不是明显的,那么lucene又是怎样控制一次只能只有一个线程的写入呢?打开Directory的源码,我们就会发现,他其实是在内部维护了一个锁的实例,通过加锁方式,来禁止后来线程的写入操作,当然锁的作用不仅仅是防止并发写入,他还可以通过锁的名字来判断,这两份索引是否为同一份索引,那么如果我们想使用多线程来提升写入速度,一个折中的办法就是,每一个I型按成写一份目录,最后再对这些目录进行合并,下面给出了一些源码中锁的实现:
protected LockFactory lockFactory;//锁实现,只能由子类覆盖
//设置锁名public Lock makeLock(String name) {return lockFactory.makeLock(name);}//清除锁public void clearLock(String name) throws IOException {if (lockFactory != null) {lockFactory.clearLock(name);}}
下面来分析Directory源码中另一个重要isOpen的作用
//注意,使用的是volatile关键字修饰volatile protected boolean isOpen = true;
isOpen是用来判断当前的Directory实例,在内存中的状态,它使用的是volatile关键字修饰的,被此变量修饰的内容,JVM虚拟机读取的时候会直接在主存中读取该变量的值,而不会再各个线程的本地内存中读,这样一来,当并发读的时候,如果Directory实例关闭了,那么各个读取的线程会立即获取最新的状态,如果不做处理的话,将会抛出一个目录实例关闭的异常。isOpen确保了索引在并发读的时候,各个线程实例获取Directory状态的一致性。
private static final class SlicedIndexInput extends BufferedIndexInput {IndexInput base;long fileOffset;long length;SlicedIndexInput(final String sliceDescription, final IndexInput base, final long fileOffset, final long length) {this(sliceDescription, base, fileOffset, length, BufferedIndexInput.BUFFER_SIZE);}SlicedIndexInput(final String sliceDescription, final IndexInput base, final long fileOffset, final long length, int readBufferSize) {super("SlicedIndexInput(" + sliceDescription + " in " + base + " slice=" + fileOffset + ":" + (fileOffset+length) + ")", readBufferSize);this.base = base.clone();this.fileOffset = fileOffset;this.length = length;}
接下来分析Directory的静态常量内部类。
SlicedIndexInput的作用,lucene的索引文件时非常松散的,不同类型的数据存储在不同的文件里,我们可以通过文件名,来单独读取指定索引文件的内容,同样的道理我们也可以,在写入信息时候,单独写入某部分数据的信息,这样一来,就避免了操作整个目录的可能,按需所用,从一定程度上来说,这样的实际提升了性能,保证了数据的稳定与可靠性,虽然也从某种程度上加大了Directory目录管理的复杂度,但是这是微不足道的。
SlicedIndexInput这个类的作用保证了lucene可以单独读取部分索引文件的内容,注意这些内容都不是最原始的数据,而是SlicedIndexInput克隆的一份副本,这样一来在并发读的环境下是非常有利的,每个线程都会从主存中load一份副本出来。在我们的源码中,我们并没有发现它具有深度克隆的功能,但是通过一系列继承的追踪,我们发现,SlicedIndexInput->BufferIndexInput->IndexInput->DataInput,在最后的这个父类中实现了Cloneable和Closeable接口,从而确保了SlicedIndexInput可以正常的工作,以及释放一些占用的IO资源。
除了上面几个比较重要的作用外,Directory还提供了,其他的一些文件管理功能,例如获取所有的索引文件信息,删除一个索引文件,获取一个索引文件的大小,索引的备份,等等。








 京公网安备 11010802041100号
京公网安备 11010802041100号